Stand-In - Tencent WeChat Visual Open Source Lightweight Video Generation Framework

What is Stand-In
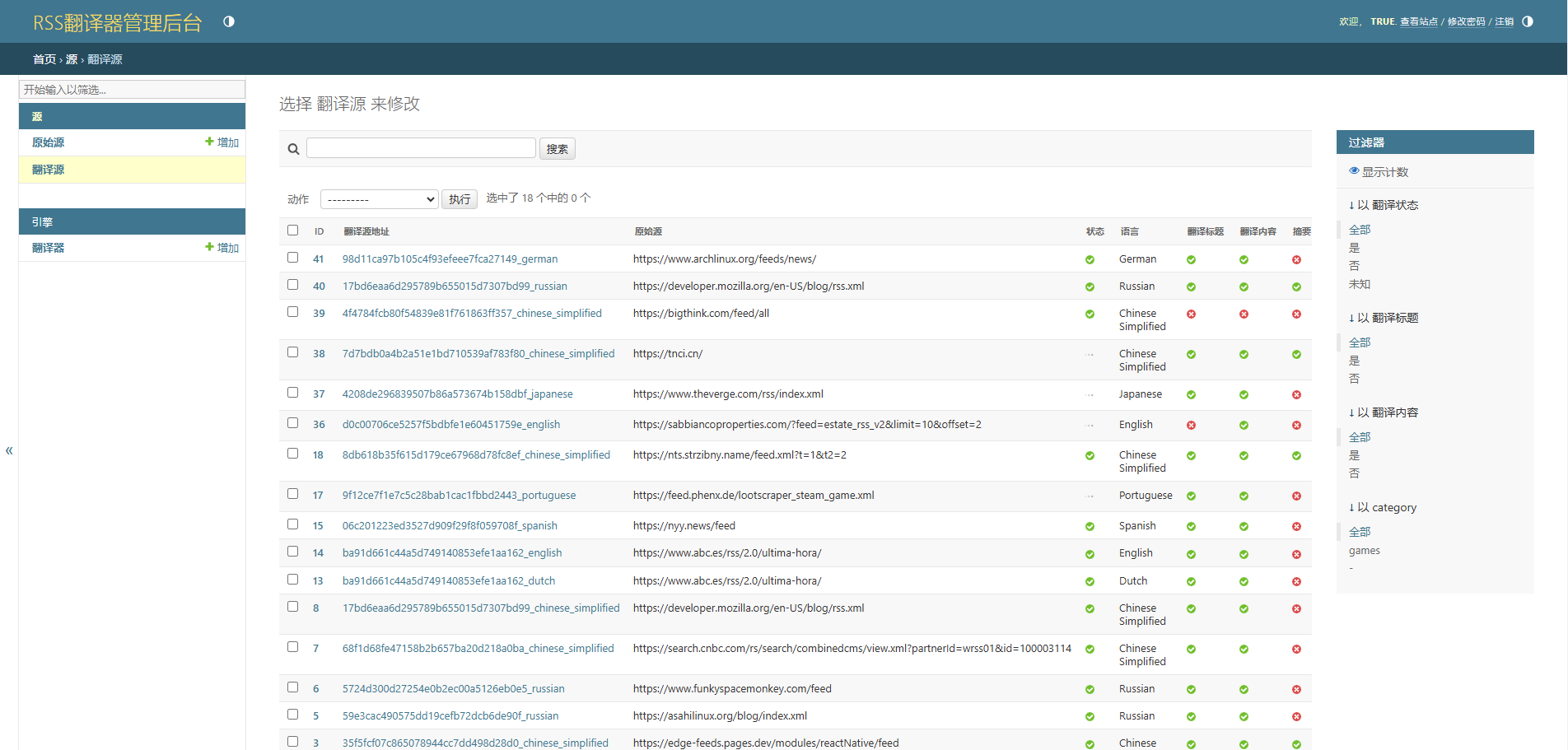
Stand-In is a lightweight, plug-and-play identity-preserving video generation framework from Tencent's WeChat Vision team. Focusing on preserving specific identity features in video generation, Stand-In can achieve excellent results in face similarity and naturalness by training only the additional parameters of the base model 1%.Stand-In supports a variety of application scenarios, including identity-preserving text-to-video generation, video generation for non-human subjects, stylized video generation, face-switching video, and pose-guided video generation. The framework is efficiently trained, high-fidelity, plug-and-play, and highly scalable, compatible with community models such as LoRA, and supports a variety of downstream video tasks.
Features of Stand-In
- Efficient training: Only the additional parameters of the base model 1% need to be trained, which drastically reduces the training cost compared to other methods.
- high fidelity: Outperforms in face similarity and video naturalness, effectively preserving identity without sacrificing video quality.
- plug-and-play: Can be easily integrated into existing text-to-video (T2V) models without complex adjustments.
- Highly scalable: Compatible with community models such as LoRA, it supports a variety of downstream video tasks such as stylized video generation, video face-swapping, and so on.
- Diversified application scenarios: It supports various application scenarios such as text-to-video generation for identity preservation, video generation for non-human subjects, and pose-guided video generation.
Stand-In's Core Benefits
- efficiency: Only the additional parameters of the base model 1% need to be trained, dramatically reducing training cost and time.
- high fidelity: Excels in face similarity and video naturalness, accurately preserving identity features while ensuring video generation quality.
- Ease of integration: Plug-and-play, seamlessly integrating into existing text-to-video (T2V) models without complex adjustments.
- compatibility: Highly compatible with community models such as LoRA, supports multiple downstream video tasks, and is highly extensible.
- Rich application scenarios: Covering a wide range of scenarios such as text-to-video generation for identity preservation, video generation for non-human subjects, stylized video generation, video face-swapping, and pose-guided video generation.
What is the official Stand-In website?
- Project website:: https://www.stand-in.tech/
- GitHub repository:: https://github.com/WeChatCV/Stand-In
- HuggingFace Model Library:: https://huggingface.co/BowenXue/Stand-In
- arXiv Technical Paper:: https://arxiv.org/pdf/2508.07901
Who Stand-In is for
- Video content creators: Use Stand-In to quickly generate high-quality, personalized video content, saving time and money on filming and post-production.
- Special effects producer for film and televisionStand-In provides efficient and natural identity-preserving video generation when identity replacement or special effects compositing is required, increasing production efficiency.
- Advertising and marketing practitioners: Can be used to create more engaging and targeted advertising videos that are more relatable and persuasive by generating videos with characters that resemble the target audience.
- game developer: Use Stand-In to quickly generate character-appropriate video content for gameplay animations or video promotions, enhancing gameplay immersion.
- Researchers and educators: In research projects or educational video production, it can be used to generate identity-specific demo videos to assist teaching or to present research results.
- Social Media Operators: Quickly generate video content that matches a brand's image or a specific theme for promotion and user interaction on social media platforms.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...