Spark-TTS: A Text-to-Speech Tool for Generating Natural Speech

General Introduction
Spark-TTS is an open source Text-to-Speech (TTS) tool developed by the SparkAudio team and hosted on GitHub, designed to help users efficiently convert text into natural and smooth speech. It is based on advanced deep learning techniques, supports multiple languages and voice styles, and is suitable for developers, researchers, or content creators. With an emphasis on ease of use and high-quality speech output, the project provides pre-trained models and custom training options that allow users to adjust speech characteristics according to their needs. While there is no detailed official documentation, the code and community support in the GitHub repository allow users to get started quickly and explore its features. the open source nature of Spark-TTS makes it a useful resource in the speech synthesis space, especially for scenarios requiring a personalized speech solution.

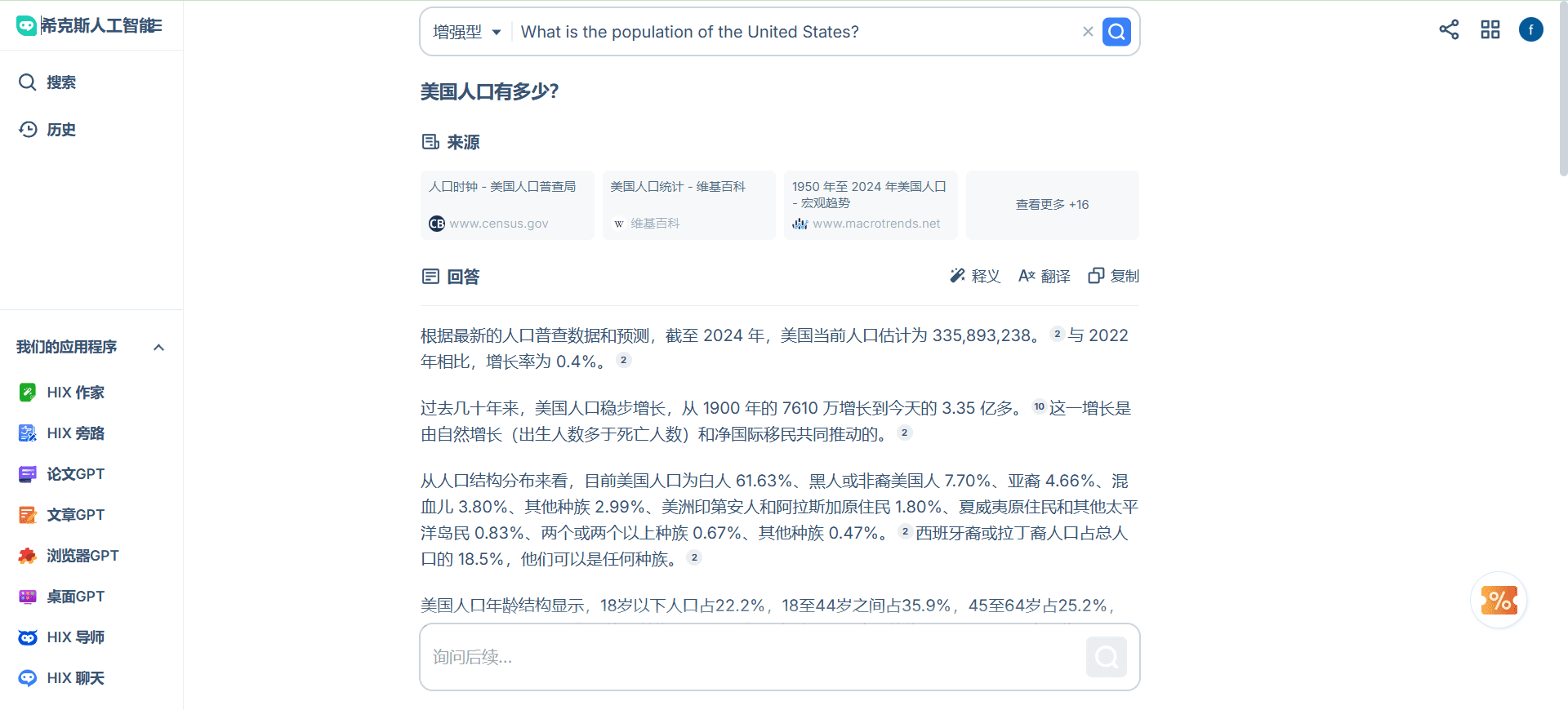
Spark-TTS Speech Generation Interface

Spark-TTS Speech Cloning Interface
Function List
- Text-to-speech conversion: Quickly convert input text to natural speech, supporting multiple languages.
- Pre-trained model support: Off-the-shelf models are provided so that users can generate speech without training from scratch.
- Customized Speech Training: Allows users to train models with their own datasets, adjusting voice style or intonation.
- Multiple voice styles: Supports speech output of different genders, speech rates and pitches.
- open source access: Users are free to download, modify and optimize the code to meet individual needs.
- Cross-platform compatibility: Based on a general-purpose programming environment, it supports operation on a wide range of operating systems.
Using Help
Spark-TTS, as an open source project on GitHub, does not have a separate installation package or graphical interface, and is mainly aimed at users with a certain programming foundation. The following is a detailed guide to help you get started from scratch and take full advantage of its features.
Installation process
Since Spark-TTS is a GitHub-based code repository, you need to use it by cloning the repository and configuring your environment. Here are the steps:
- environmental preparation
- Make sure you have Python installed on your computer (recommended version 3.8 or higher).
- Install Git for downloading code from GitHub. You can download and install it from the Git website.
- (Optional) Installation of virtual environment tools, such as the
virtualenvto isolate project dependencies.
- clone warehouse
- Open a terminal (CMD or PowerShell for Windows, Terminal for Mac/Linux).
- Enter the following command to clone the Spark-TTS repository locally:
git clone https://github.com/SparkAudio/Spark-TTS.git - Once the cloning is complete, go to the project directory:
cd Spark-TTS
- Installation of dependencies
- Spark-TTS typically relies on deep learning frameworks (such as PyTorch or TensorFlow) and audio processing libraries. Check out the repository for
requirements.txtfile (if any), run the following command to install the dependency:pip install -r requirements.txt - If not
requirements.txt, common dependencies may include:pip install torch torchaudio numpy - Depending on your hardware (CPU or GPU), make sure to install the corresponding version of PyTorch, see the official PyTorch website.
- Spark-TTS typically relies on deep learning frameworks (such as PyTorch or TensorFlow) and audio processing libraries. Check out the repository for
- Verify Installation
- Once in the project directory, run a simple test script (if provided by the repository). Example:
python test.py - If no error is reported, the environment is configured successfully.
- Once in the project directory, run a simple test script (if provided by the repository). Example:
Main Functions
The core function of Spark-TTS is to convert text to speech, the following is the specific operation procedure:
1. Speech generation using pre-trained models
- Prepared text: Create a simple text file (e.g.
input.txt), write the text to be converted, e.g., "Hello, this is a test voice." - Running Scripts: Assuming the repository provides a
generate.pyscript (the exact filename is based on the actual repository), enter it in the terminal:python generate.py --input input.txt --output output.wav
- Parameter description::
--input: Specifies the input text file path.--output: Specify the path to save the generated voice file (e.g.output.wav).- If the script supports it, add the
--modelparameter to select a pre-trained model, or--voiceparameter to adjust the sound style.
- in the end: After running it, you will find the generated
output.wavfile, open it with an audio player to hear the effect.
2. Training of customized models
- Preparing the dataset: You need to provide the text and the corresponding audio data. The data format is usually
.txtDocumentation (text) and.wavfile (audio), it is recommended to refer to the repository for theREADME.mdor example folder. - Configuration parameters: Edit the configuration file (possibly
config.jsonor similar file), set the training parameters such as learning rate, batch size, etc. If there is no configuration file, modify the parameters directly in the script. - priming training: Run a training script, for example:
python train.py --data_path ./dataset --output_model my_model - training process: Depending on the amount of data and hardware performance, training can take hours or even days. When it's done, you'll get a new model file (e.g.
my_model.pth). - Using the new model: Pass the trained model paths into the generation script:
python generate.py --input input.txt --model my_model.pth --output custom_output.wav
3. Adjustment of voice style
- If Spark-TTS supports multi-style output (you need to check the code or documentation to confirm), you can adjust the speech rate, pitch, etc. via parameters. Example:
python generate.py --input input.txt --speed 1.2 --pitch 0.8 --output styled_output.wav - Parameter description::
--speed: Speed of speech, 1.0 is normal speed, greater than 1.0 is faster, less than 1.0 is slower.--pitch: Pitch, the higher the value the higher the pitch and vice versa.
- Effectiveness Verification: Audition after generation and gradually adjust the parameters until you are satisfied.
Example of operation process
Suppose you want to convert a Chinese text into female speech:
- establish
test.txt, wrote: "It's a beautiful day, let's go for a walk in the park." - Run command:
python generate.py --input test.txt --voice female --output park.wav - probe
park.wav, confirm that the speech is natural and smooth. - If you are not satisfied, try to adjust the parameters or train a new model.
caveat
- documentation reference: Prioritize the view of the warehouse in the
README.md, which may have more specific instructions for installation and use. - hardware requirement: Generation and training may require GPU acceleration; if no GPU is available, it can be run on a CPU, but at a slower speed.
- Community Support: If you run into problems, ask questions on the GitHub Issues page or search for solutions from similar TTS projects such as Coqui TTS.
With the above steps, you can easily get started with Spark-TTS, whether it's generating speech or customizing exclusive models.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts

No comments...