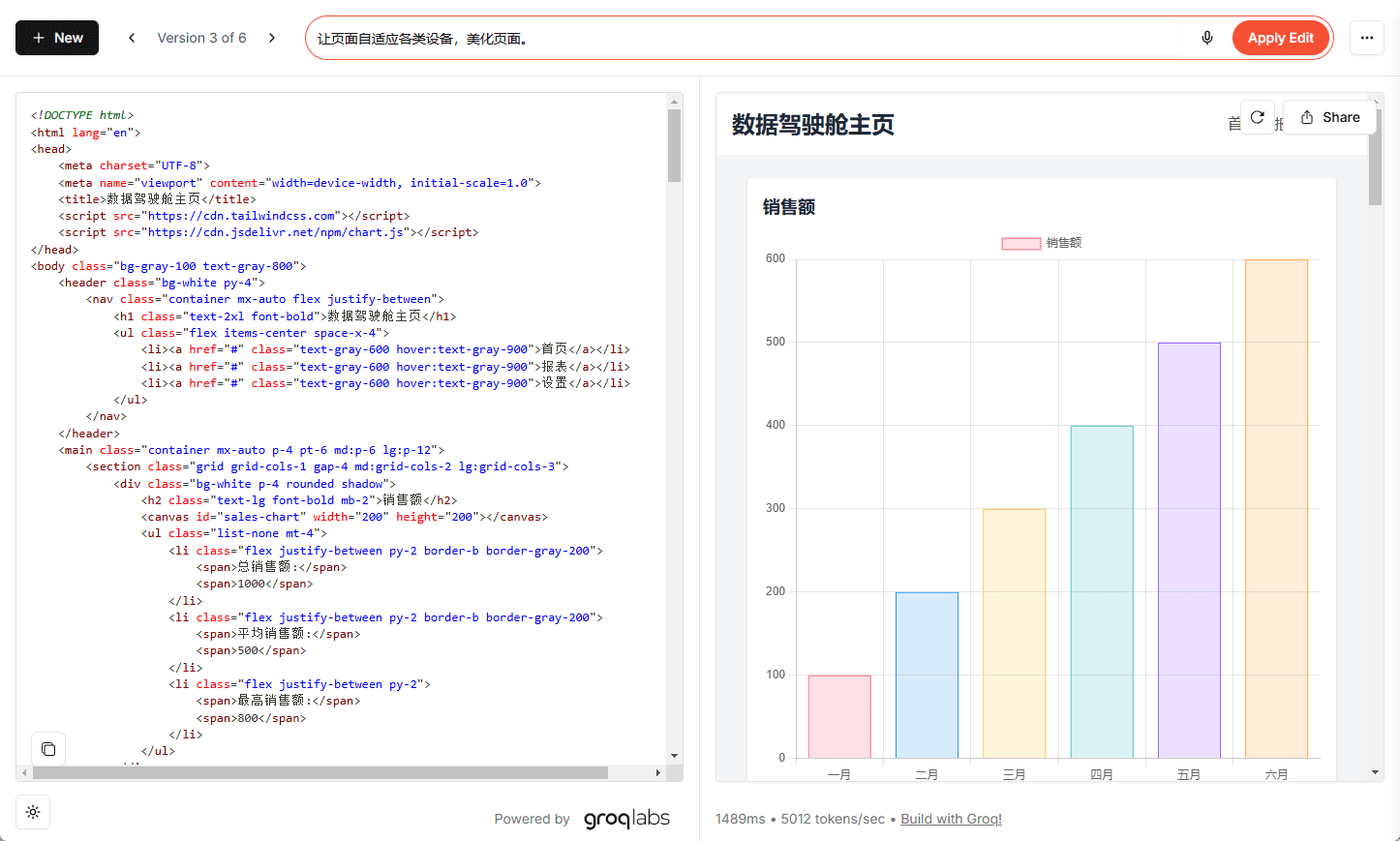
Qwen3-VL - AliCloud Tongyi Qianqian open source multimodal visual language big model

What is Qwen3-VL
Qwen3-VL is an open source multimodal visual language large model by AliCloud Tongyi Qianqian team, with 235 billion references and about 471GB of model files.It contains instruction version and thinking version, which adopts enhanced MRope interleaved layout, DeepStack and other technologies, which can effectively utilize the multi-level features of the visual transformer to improve video comprehension ability. In visual perception benchmarks, the instruction version equals or even surpasses Gemini 2.5 Pro; the thinking version reaches the latest level in multimodal reasoning benchmarks. qwen3-VL is easy to use, and bytransformersThe library can load the model, support for image and text input, and can generate text output. Using the Apache 2.0 protocol, fully commercializable, and smaller model versions will be released in the future.

Qwen3-VL Functional Features
- Strong visual comprehension: Qwen3-VL is capable of handling a variety of visual tasks such as image classification, target detection, and image description. With the enhanced MRope interleaved layout and DeepStack technology, the multi-level features of the vision transformer are effectively utilized to enhance the spatio-temporal modeling of images and videos for more accurate understanding of visual content.
- Excellent multimodal reasoning: The model is state-of-the-art in multimodal reasoning benchmark tests, and is capable of combining multiple modal information such as images and text for complex reasoning and decision making. For example, given an image and a piece of related text, Qwen3-VL can accurately understand the relationship between the two and generate accurate descriptions or answer related questions.
- Efficient text generation capabilities: Qwen3-VL has a powerful text generation capability, which can generate high-quality text descriptions based on input images or videos, such as generating detailed descriptions of pictures, scripts for videos, etc.. It can generate image content related to the text prompts, realizing text-to-image generation.
- Flexible Model Architecture: Qwen3-VL consists of several variants, such as the Command Edition and the Thinking Edition, to fulfill different application scenarios and needs. The Command version performs well in visual perception benchmark tests, while the Thinking version is better at multimodal reasoning tasks. The model supports multiple data types and device mappings, which facilitates flexible configuration according to the actual needs of users.
- Open Source and Scalability: Qwen3-VL is open source using the Apache 2.0 protocol and is fully commercializable without whitelisting. All weights have been released on Hugging Face for developers to download and use. Smaller model versions, such as 2 billion and 7 billion parameter versions, will be released in the future to satisfy users with different scale and performance requirements.
Core Benefits of Qwen3-VL
- Visual AgentQwen3-VL can operate computer and cell phone interfaces, recognize GUI elements, understand button functions, invoke tools, and perform tasks, and has reached the world's top level in OS World and other benchmarks, and can effectively improve performance in fine-grained perceptual tasks by invoking tools.
- Plain text capabilities comparable to top language modelsQwen3-VL is a new generation of visual language model with a solid textual foundation and multimodal capabilities, which is co-trained with mixed text and visual modality at the early stage of pre-training, and its textual capabilities are continuously strengthened, and its performance on text-only tasks is comparable to that of the flagship text-only model Qwen3-235B-A22B-2507. It is a new-generation visual language model with a solid textual foundation and multimodal capabilities.
- Visual Coding Capabilities Dramatically Improved: Realize image-generating code and video-generating code, for example, when you see a design drawing, the code generates Draw.io/HTML/CSS/JS code, truly realizing "WYSIWYG" visual programming.
- Significant increase in spatial awareness2D grounding: 2D grounding changes from absolute coordinates to relative coordinates, supports judgment of object orientation, perspective change, and occlusion relationship, and realizes 3D grounding, which lays the foundation for spatial reasoning and embodied scenes in complex scenes.
- Long Context Support and Long Video Comprehension: Full range of models natively supported 256K token This means that whether it's hundreds of pages of technical documentation, an entire textbook, or a two-hour-long video, it can be entered, memorized, and retrieved with precision, and it supports precise positioning of the video down to the second level.
- Significantly increased ability to think multimodally: The Thinking model is optimized for STEM and mathematical reasoning. When faced with questions in specialized disciplines, the model captures details, pulls out the threads, analyzes cause and effect, and delivers logical, evidence-based answers, reaching leading levels in authoritative reviews such as MathVision, MMMU, MathVista, and more.
- Comprehensive upgrade of visual perception and recognition capabilitiesBy optimizing the quality and breadth of the pre-training data, the model is now able to recognize a wider range of object categories - from celebrities, anime characters, commodities, landmarks, to plants and animals - covering the need to recognize everything in daily life as well as in the professional world.
- OCR supports more languages and complex scenarios: Supported languages in Chinese, English and foreign languages from 10 Expansion of species to 32 The company's products are of different kinds, covering more countries and regions; more stable performance in challenging scenes of real photography, such as complex lighting, blurring, and tilting; significant improvement in the recognition accuracy of rare words, ancient characters, and professional terms; and further improvement in the ability to comprehend ultra-long documents and restore fine structures.
Model performance of Qwen3-VL
- Excellent visual perception: In visual perception benchmarks, the command version of the Qwen3-VL equaled or even surpassed the Gemini 2.5 Pro, demonstrating strong image and video understanding.
- Leading Multimodal Reasoning Capabilities: The Thinking Edition is state-of-the-art in multimodal reasoning benchmarking and is capable of accurately combining multimodal information, such as images and text, to perform complex reasoning.
- High quality of text generation: It can generate high-quality text descriptions based on input images or videos, such as detailed descriptions of pictures, scripts of videos, etc. The generated text is natural, accurate and logical.
- High modeling efficiency: Despite the large number of parameters, Qwen3-VL shows high efficiency in practical applications, and is able to quickly handle complex multimodal tasks and provide timely responses to users.
- adaptable: The model is highly adaptable to different types of visual and textual inputs, both simple images and complex videos, and can effectively understand and generate relevant outputs.
What is the official website for Qwen3-VL
- Project website:: https://qwen.ai/blog?id=99f0335c4ad9ff6153e517418d48535ab6d8afef&from=research.latest-advancements-list
- Github repository:: https://github.com/QwenLM/Qwen3-VL
- HuggingFace Model Library:: https://huggingface.co/collections/Qwen/qwen3-vl-68d2a7c1b8a8afce4ebd2dbe
People for whom Qwen3-VL is intended
- Artificial intelligence researchers: Qwen3-VL provides researchers with a powerful multimodal research platform that can be used to explore cutting-edge areas such as visual-verbal interaction and multimodal reasoning, and to advance the development of AI technology.
- Developers & Engineers: The model is open source and fully commercially available, and developers can use its powerful features to develop a variety of multimodal applications, such as intelligent image annotation, video content generation, and multimodal dialog systems, to meet the needs of different industries.
- Enterprise and Business Users: Enterprises can integrate Qwen3-VL into their business processes to improve the efficiency and quality of content creation, customer service, and data analysis. For example, for automatic generation of product descriptions, multimodal interactions in intelligent customer service, etc.
- Educators and students: In education, Qwen3-VL can be used as a teaching tool to help students better understand complex visual and verbal information, and to stimulate their interest and creativity in AI.
- content creator: For creators who need to generate high-quality text and visual content, Qwen3-VL can provide creative inspiration and content generation support, such as automatic generation of articles, scripts, image descriptions, etc., to improve creative efficiency.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles

No comments...