PP-OCRv5 - Baidu's open source AI model for next-generation text recognition

What is PP-OCRv5
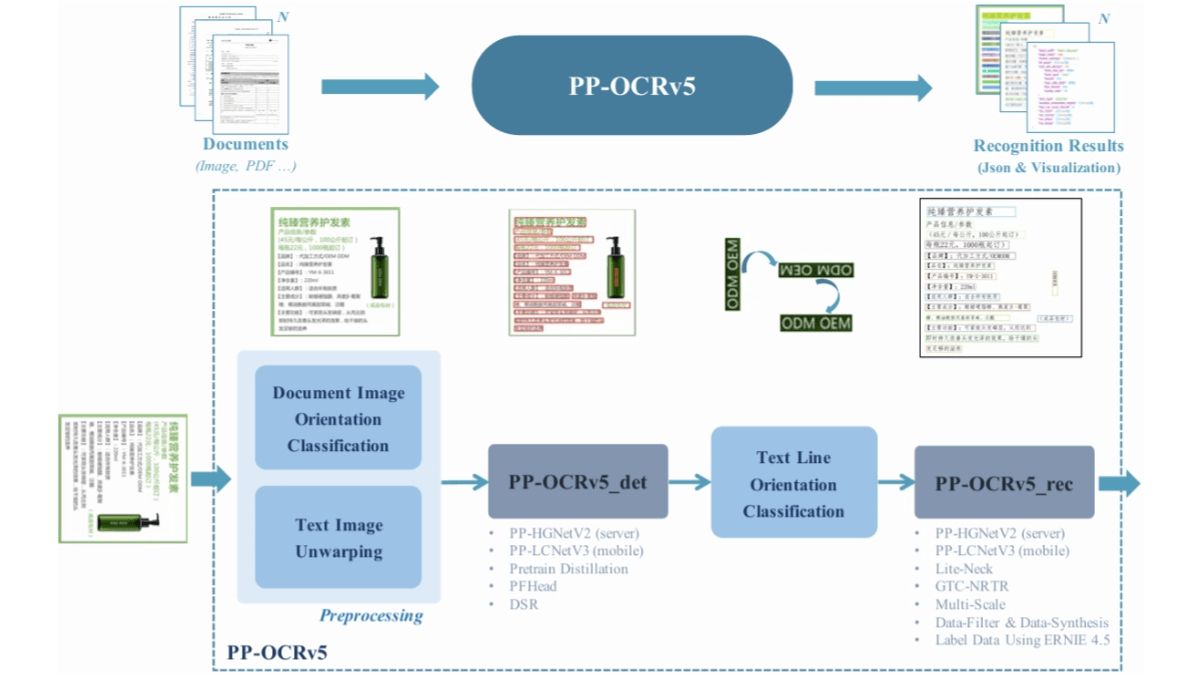
PP-OCRv5 is the latest generation of text recognition AI model released by Baidu. With a lightweight design and a reference count of only 0.07B, it is suitable for running efficiently on CPUs and edge devices, and can process more than 370 characters per second. The model supports five text types including Simplified Chinese, Traditional Chinese, English, Japanese and Pinyin, and can recognize more than 40 languages, making it suitable for multilingual document processing.PP-OCRv5 adopts a modularized two-phase process, including four core components: image preprocessing, text detection, text line direction classification and text recognition. It performs well in complex scenarios such as complex handwriting in Chinese and English, vertical text, and secluded characters, etc. Compared with PP-OCRv4, the accuracy of the scenarios such as handwritten Chinese detection, antique text detection, vertical text recognition, secluded character recognition, and handwritten English recognition has been improved by 13.8%, 43%, 71%, 96%, and 118%, respectively.PP-OCRv5 has upgraded the core components of the backbone and the core components of the backbone and the core components of the backbone. OCRv5 upgraded the backbone network, adopted the dual-branch architecture, optimized the data construction strategy by combining the attention mechanism and CTC loss, and obtained high-quality annotated data from documents such as PDFs and e-books.
Features of PP-OCRv5
- Lightweight design: The number of references is only 0.07B, which is suitable for running efficiently on CPUs and edge devices, and the mobile version can process more than 370 characters per second on Intel Xeon Gold 6271C CPUs, which is capable of processing large amounts of text data quickly.
- Multi-language supportIt supports five text types: Simplified Chinese, Traditional Chinese, English, Japanese and Pinyin, and recognizes more than 40 languages, which is suitable for multi-language document processing and meets the needs of text recognition in different language environments.
- High-precision recognition: It performs well in complex scenarios such as complex handwriting in Chinese and English, vertical text, and secluded characters, etc. Compared with PP - OCRv4, its accuracy in the scenarios of handwritten Chinese detection, ancient text detection, vertical text recognition, secluded character recognition, and handwritten English recognition has been improved by 13.81 TP3T, 431 TP3T, 711 TP3T, 961 TP3T, and 1,181 TP3T, respectively, and it is able to recognize various types of text more accurately.
- Precise text positioning: Providing accurate text line bounding box coordinates is a key requirement for structured data extraction and content analysis, and helps subsequent text processing and analysis work.
- Single Model Multilingual RecognitionIt is the industry's first ultra-lightweight (<100M) open source model that supports five text types in a single model. It realizes seamless recognition of five text types through a unified model architecture, eliminating the need to deploy independent models for different text types, simplifying the deployment process, and also improving the overall accuracy and speed of recognition.
- Highly adaptable to complex scenarios: It supports the recognition of a variety of challenging scenarios, such as complex handwriting in Chinese and English, vertical text, and rare characters, and can cope with a variety of complex text formats and contents, which improves the versatility and practicability of the model.
- Backbone network upgrade: A two-branch architecture with PP - HGNetV2 as the backbone is used, where one branch uses attention-based training to enhance sequence modeling, and the other branch focuses on efficient inference using CTC loss. The two branches collaborate with each other during training, but only the lightweight branch is used during prediction, thus ensuring accuracy and speed.
- Data building strategy optimization: Combine traditional models with ERNIE - 4.5 - VL - 424B - A47B to automatically annotate and filter high-quality handwriting samples, including rare characters generated by synthesis. Large-scale annotated data from documents such as PDFs and eBooks are obtained through automatic parsing and edit distance filtering, laying a solid data foundation for the overall performance of the model.
Core Benefits of PP-OCRv5
- Lightweight design: The model parameter count is only 0.07B, enabling higher performance on CPUs and edge devices. The mobile version can process over 370 characters per second on an Intel Xeon Gold 6271C CPU.
- High-precision recognition: Outperforms general-purpose visual language models such as Gemini 2.5 Pro, Qwen2.5-VL, and GPT-4o in OCR-specific benchmarking, including handwritten and printed Chinese and English, as well as Pinyin texts.
- Multi-language support: Supports five text types: Simplified Chinese, Traditional Chinese, English, Japanese and Pinyin, and recognizes more than 40 languages.
- Precise text positioning: Providing accurate text line bounding box coordinates is a key requirement for structured data extraction and content analysis.
What is PP-OCRv5 official website?
- Project website:: https://huggingface.co/blog/baidu/ppocrv5
- HuggingFace Model Library:: https://huggingface.co/collections/PaddlePaddle/pp-ocrv5-684a5356aef5b4b1d7b85e4b
Who is PP-OCRv5 for?
- Enterprise Developers: Enterprises that need to integrate high-efficiency text recognition functions in their business systems, such as the financial, medical, and education industries, can be used in scenarios such as contract parsing, digitization of medical records, and correction of test papers.
- (scientific) researcher: Researchers engaged in computer vision, natural language processing, and other artificial intelligence fields can use PP-OCRv5 for academic research and model comparison.
- software developer: Developers of applications that require text recognition functionality, such as mobile applications, desktop software, etc., can quickly integrate PP-OCRv5 to achieve functionality.
- Data Analyst: Data analysts who need to extract structured data from a large number of documents can use it to quickly process and analyze text data.
- educator: Teachers who need to process and analyze handwritten texts such as student assignments and test papers can use it for automatic corrections and content analysis.
- file manager: Archivists responsible for managing and digitizing large quantities of paper documents can be used to quickly identify and categorize documents.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...