
MiniMax-M1 - Open Source Inference Model from MiniMax

What is MiniMax-M1
MiniMax-M1 is an open source inference model from the MiniMax team, based on a combination of the Mixed Expert Architecture (MoE) and the Lightning Attention mechanism, with 456 billion total parameters. The model supports 1 million token MiniMax-M1 has a long context input and 80,000 tokens output, which makes it suitable for processing long documents and complex reasoning tasks. The model is available in 40K and 80K reasoning budget versions to optimize computational resources and reduce reasoning costs. miniMax-M1 outperforms several open source models in tasks such as software engineering, long context understanding, and tool usage. The model's efficient computational power and robust reasoning capabilities make it a powerful foundation for the next generation of language modeling agents.

Key Features of MiniMax-M1
- Long Context Processing: It supports inputs of up to 1 million tokens and outputs of 80,000 tokens, and can efficiently process long documents, long reports, academic papers, and other long text content, which is suitable for complex reasoning tasks.
- Efficient Reasoning: Provides two inference budget versions, 40K and 80K, to optimize the allocation of computing resources, reduce inference costs and maintain high performance.
- Multi-domain task optimization: excel in tasks such as mathematical reasoning, software engineering, long contextual understanding, and tool use.
- function call: Supports structured function calls, recognizes and outputs external function call parameters, facilitates interaction with external tools, and improves automation and work efficiency.
MiniMax-M1's Performance
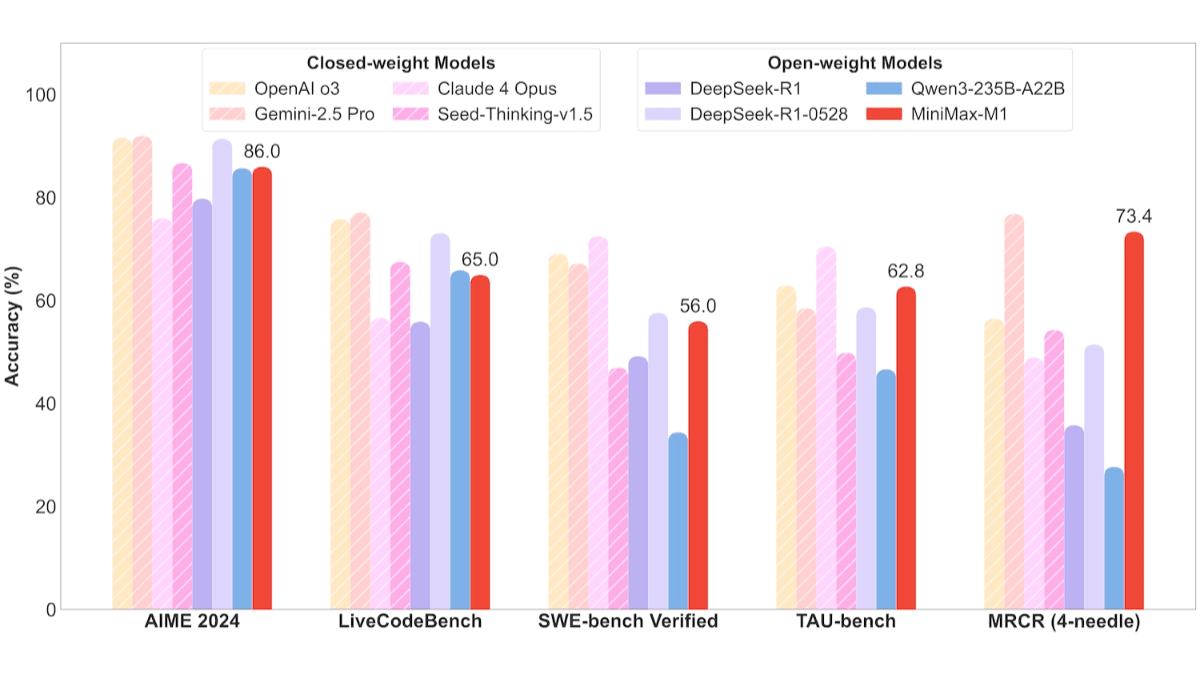
- Software engineering tasks: In the SWE-bench benchmark, MiniMax-M1-40k and MiniMax-M1-80k achieved 55.61 TP3T and 56.01 TP3T, respectively, which is slightly behind DeepSeek-R1-0528's 57.61 TP3T and significantly outperforms other open source models.
- Long contextual comprehension tasks: Relying on millions of context windows, MiniMax-M1 excels in long context understanding tasks, outperforming all open-source models across the board, even surpassing OpenAI o3 and Claude 4 Opus, and ranking second in the world behind Gemini 2.5 Pro.
- Tool use scenarios: In the TAU-bench test, MiniMax-M1-40k led all open source models, beating Gemini-2.5 Pro.
MiniMax-M1's official website address
- GitHub repository::https://github.com/MiniMax-AI/MiniMax-M1
- HuggingFace Model Library::https://huggingface.co/collections/MiniMaxAI/minimax-m1
- Technical Papers::https://github.com/MiniMax-AI/MiniMax-M1/blob/main/MiniMax_M1_tech_report.pdf
How to use MiniMax-M1
- API Calls::
- Visit the official website: Visit MiniMax Official website, register and log in to your account.
- Getting the API key: Request an API key in the Personal Center or on the Developer page.
- Using the API: Invoke the model based on HTTP requests, according to the official API documentation. For example, send a request using Python's requests library:
import requests
url = "https://api.minimax.cn/v1/chat/completions"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
data = {
"model": "MiniMax-M1",
"messages": [
{"role": "user", "content": "请生成一段关于人工智能的介绍。"}
]
}
response = requests.post(url, headers=headers, json=data)
print(response.json())- Hugging Face Usage::
- Installing the Hugging Face Library: Ensure that dependencies such as transformers and torch are installed.
pip install transformers torch- Loading Models: Load a MiniMax-M1 model from the Hugging Face Hub.
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "MiniMaxAI/MiniMax-M1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
input_text = "请生成一段关于人工智能的介绍。"
inputs = tokenizer(input_text, return_tensors="pt")
output = model.generate(**inputs, max_length=100)
print(tokenizer.decode(output[0], skip_special_tokens=True))- MiniMax APP or Web use::
- Access to the Web: Log in to the MiniMax Web site, enter a question or task on the page, and the model generates the answer directly.
- DOWNLOAD APP: Download the MiniMax APP on your phone and interact with it using similar operations.
Product Pricing for MiniMax-M1
- API call inference cost pricing::
- 0-32k Input Length::
- input cost: $0.8/million tokens.
- output cost: $8 per million tokens.
- 32k-128k Input length::
- input cost: $1.2/million token.
- output cost: $16 per million tokens.
- 128k-1M Input Length::
- input cost: $2.4/million token.
- output cost: $24 per million tokens.
- 0-32k Input Length::
- APP and Web::
- free of charge: MiniMax APP and Web offer unlimited free access, suitable for general users and users with non-technical background.
MiniMax-M1 Core Benefits
- long context processing capabilityIt supports inputs of up to 1 million tokens and outputs of up to 80,000 tokens, making it suitable for processing long documents and complex reasoning tasks.
- Efficient inference performance: Provide two inference budget versions of 40K and 80K, combined with the lightning attention mechanism to optimize computational resources and reduce inference costs.
- Multi-domain task optimization: excel in tasks such as software engineering, long context understanding, mathematical reasoning, and tool use, adapting to diverse application scenarios.
- Advanced Technology Architecture: Based on hybrid expert architecture (MoE) and large-scale reinforcement learning (RL) training to improve computational efficiency and model performance.
- high quality-price ratio: The performance is close to the international leading models, while providing flexible pricing strategies and free access to APP and Web to lower the threshold of use.
People for whom MiniMax-M1 is intended
- developers: Software developers efficiently generate code, optimize code structure, debug programs or automatically generate code documentation.
- Researchers and scholars: Process long academic papers, conduct literature reviews or complex data analysis, use models to quickly organize ideas, generate reports and summarize research results.
- content creator: Those who need to create long-form content use the MiniMax-M1 to assist in generating ideas, writing story outlines, touching up text, or generating long-form fiction, and more.
- schoolchildren: for providing clear solutions and writing support.
- business user: Enterprises integrate them into automation solutions, such as intelligent customer service, data analytics tools or business process automation.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles



No comments...