MiDashengLM - Xiaomi's open source sound understanding model

What is MiDashengLM
MiDashengLM is Xiaomi's open-source large model for efficient sound understanding, specifically parameterized as MiDashengLM-7B, focusing on audio processing and understanding. The model is built based on Xiaomi Dasheng audio encoder and Qwen2.5-Omni-7B Thinker decoder, which can unify the understanding of speech, ambient sound and music. The model has excellent inference efficiency and is the first Token MiDashengLM training data is completely open source and supports both academic and commercial use, providing strong support for upgrading multimodal interaction experience.
Key Features of MiDashengLM
- Audio content to text: The model translates various kinds of audio, such as speaking voices, nature sounds, or music, into textual descriptions that help people quickly understand what's really going on in the audio.
- Recognize audio categories: The model can distinguish whether a piece of audio is speech, ambient sound or music, etc., just like labeling the audio to facilitate its use in different scenarios.
- speech recognition: Converts what a person says into text, supports multiple languages, and is especially suitable for use in voice assistants or smart devices.
- Audio Q&A: Answers questions based on audio content, such as "What was that sound?" in the car, and the model can answer.
- multimodal interaction: The ability to understand audio and other information (e.g., text, pictures) in conjunction with each other makes device interaction smarter and more natural.
MiDashengLM's official website address
- GitHub repository:: https://github.com/xiaomi-research/dasheng-lm
- HuggingFace Model Library:: https://huggingface.co/mispeech/midashenglm-7b
- Technical Papers:: https://github.com/xiaomi-research/dasheng-lm/blob/main/technical_report/MiDashengLM_techreport.pdf
- Online Experience Demo:: https://huggingface.co/spaces/mispeech/MiDashengLM-7B
How to use MiDashengLM
- Online Experience: Visit MiDashengLM's online experience demo address.
- Uploading audio files: Upload an audio file (supported formats include WAV, MP3, etc.).
- Waiting to be processed: After uploading the audio, the model automatically processes the audio and generates the results.
- View Results: After processing is complete, view the description or classification results generated by the model.
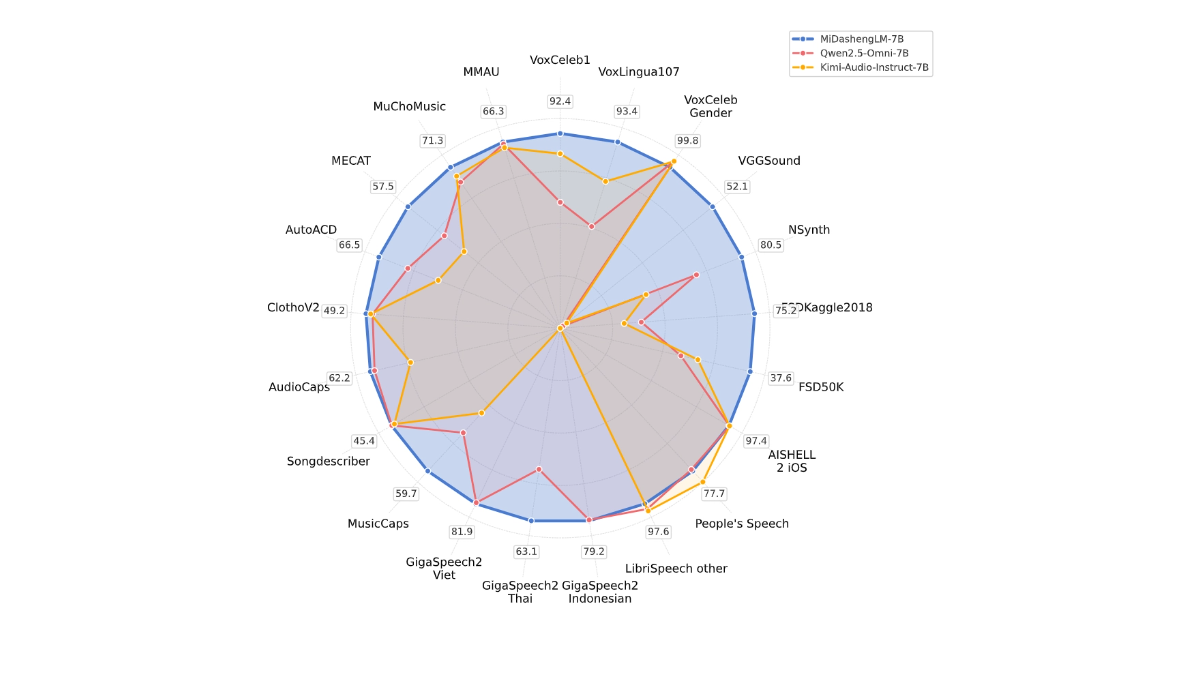
MiDashengLM's Core Strengths
- Efficient inference performance: MiDashengLM's inference efficiency is extremely high, the first token latency is extremely low, and the throughput is greatly improved, which makes it suitable for real-time interaction scenarios.
- Powerful audio comprehension: enables a unified understanding of a wide range of audio, including speech, ambient sound, and music, avoiding the limitations of traditional methods.
- Data and Modeling Open Source: The training data and models are completely open source, facilitating research and secondary development by developers and supporting academic and commercial use.
- Wide range of application scenarios: Apply to a variety of fields such as smart cockpit, smart home, voice assistant, audio content creation and education and learning.
- Technology Optimization: Based on an optimized audio encoder and decoder design, MiDashengLM excels at handling complex audio tasks while reducing computational load.
- Training Strategies: A training strategy based on generic audio description alignment and multi-expert analysis ensures that the model learns the deep semantic associations of audio and improves generalization capabilities.
People for whom MiDashengLM is intended
- Artificial intelligence researchers: The model provides researchers with open source audio understanding models and training data to facilitate research and innovation in related fields.
- Smart Device Developers: For teams developing products such as smart cockpits, smart homes, voice assistants, etc., the model is quickly integrated into the product to enhance the interaction experience.
- Audio content creators: Audio creators use models to automatically generate audio descriptions and labels to improve the efficiency of content creation.
- Educators and learners: in the field of language learning and music education, assisting pronunciation feedback and theoretical guidance, helping learners to better master knowledgeThe
- business user: An efficient solution for companies that need audio comprehension functionality that supports commercial use and can be used for product development and service optimization.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles


No comments...