Local-NotebookLM: local PDF to generate voice podcasts of open source tools

General Introduction
Local-NotebookLM is an open source project that aims to provide locally run intelligent document processing and content generation tools. It is subject to Google NotebookLM The project is inspired by the popularity of PDF and is focused on helping users convert documents such as PDFs into multiple output formats such as podcasts, interviews or lectures, while supporting local deployment to ensure data privacy. The developer, Gökdeniz Gülmez, maintains the project on GitHub, providing clear installation steps and instructions. With support for complex documents such as academic papers, up to 100,000 words, and intelligent chunking, the project is ideal for users who need to efficiently analyze documents or generate creative content. Whether you're a student, researcher, or content creator, it's easy to convert documents to audio or express yourself in multiple modes. 
Function List
- Intelligent Document Processing: automatically extract PDF text, clean up formatting errors, support for academic papers containing mathematical formulas.
- Intelligent chunking: Splits large files into manageable segments, supporting documents up to 100,000 words.
- Multi-modal content generation: 15 output formats are available, including podcasts, interviews, debates, lectures, and more.
- Local runtime support: No need to rely on cloud services, all processing is done on the user's device, guaranteeing data security.
- Open source and free: The code is publicly available on GitHub and users are free to download, modify and contribute.
Using Help
Installation process
To use Local-NotebookLM locally, you need to follow the steps below to configure your environment and run the project. Below is a detailed installation guide to ensure you get up and running quickly.
1. Cloning of warehouses
First, make sure you have Git installed on your device. open a terminal (Command Prompt or PowerShell for Windows users) and enter the following command to clone the project locally:
git clone https://github.com/Goekdeniz-Guelmez/Local-NotebookLM.git
When finished, go to the project catalog:
cd Local-NotebookLM
2. Creation of virtual environments
To avoid dependency conflicts, it is recommended to use a Python virtual environment. Run the following command to create and activate it:
- Linux/macOS::
python -m venv venv
source venv/bin/activate
- Windows (computer)::
python -m venv venv
venv\Scripts\activate
After activation, the terminal prompt will be preceded by (venv), indicating that the virtual environment has been entered.
3. Installation of dependencies
Project dependencies are listed in requirements.txt file. Run the following command to install all necessary libraries:
pip install -r requirements.txt
The installation process may take a few minutes, depending on network speed. Once completed, the installation can be accessed via the pip list Check if the installation was successful.
4. Running the project
After the installation is complete, run the main program file directly (assuming the main.py(The exact filename is based on the latest version of GitHub):
python main.py
If all goes well, the program will start and you can begin using Local-NotebookLM.
How to use the main features
The core of Local-NotebookLM lies in document processing and content generation, and the following are the steps to do so.
Function 1: Intelligent Document Processing
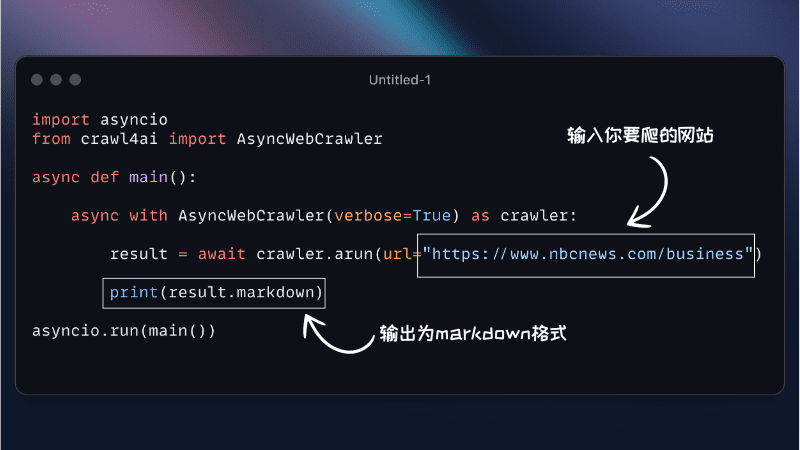
- Upload PDF files::
- Prepare a PDF file (e.g., an academic paper or report) and place it in the designated folder in the project directory (or directly in the root directory if not explicitly stated).
- Enter the file path in the program interface (or command line, depending on the version), for example:
input.pdfThe
- Text extraction and cleanup::
- The program automatically extracts the text from the PDF, removing extra line breaks, spaces or formatting errors.
- For documents containing mathematical formulas, the tool will try to preserve the structure of the formulas to ensure the integrity of the content.
- Results View::
- The processed text is saved as a plain text file (e.g.
output.txt), or displayed directly in the interface for the next step.
- The processed text is saved as a plain text file (e.g.
Function 2: Intelligent chunking
- Applicable Scenarios: When an uploaded PDF is more than a few thousand words, the program automatically chunks it.
- procedure::
- Specify the chunking parameters (e.g., 5000 words per chunk) when you run the program, example command:
python main.py --chunk-size 5000 input.pdf - The chunked content is saved in order as multiple files (e.g.
chunk1.txt,chunk2.txt) for easy follow-up.
- Specify the chunking parameters (e.g., 5000 words per chunk) when you run the program, example command:
- caveat: Maximum support for 100,000 words, if the file is too large, it is recommended to split it in advance.
Function 3: Multi-mode content generation
- Select Output Format::
- The program supports 15 modes, such as podcasts, interviews, and so on. Runtime is specified by parameters, e.g:
python main.py --mode podcast input.txt
- The program supports 15 modes, such as podcasts, interviews, and so on. Runtime is specified by parameters, e.g:
- Generate content::
- The program generates content in the corresponding format based on the extracted text, e.g. the podcast mode will simulate a two-person conversation.
- The generated results are usually saved as audio files (e.g.
output.mp3) or text scripts (such asscript.txt).
- Play or Edit::
- Use any audio player (e.g. VLC) to open the generated
.mp3file, or adjust the script with a text editor and regenerate it.
- Use any audio player (e.g. VLC) to open the generated
Handling tips and precautions
- Environmental requirements: Make sure Python version is 3.8 or higher, ffmpeg is recommended (for audio processing) and available for Linux users.
sudo apt install ffmpegWindows users need to download and configure the environment variables. - file path: Avoid using Chinese paths when entering file paths to avoid encoding errors.
- Debugging Issues: If you get an error, check to see if the dependencies are fully installed, or check the GitHub Issues page for community help.
- Extended functionality: Users familiar with programming can modify the code to add custom output formats, and the open source nature of the project provides unlimited possibilities for this.
Through the above steps, you can easily convert PDF documents into podcasts or other forms of content, enjoying a localized, intelligent processing experience. Whether it is academic research or idea generation, Local-NotebookLM can be your right hand.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...