GLM-5V-Turbo - 智谱发布首个原生多模态Coding基座模型

GLM-5V-Turbo是什么
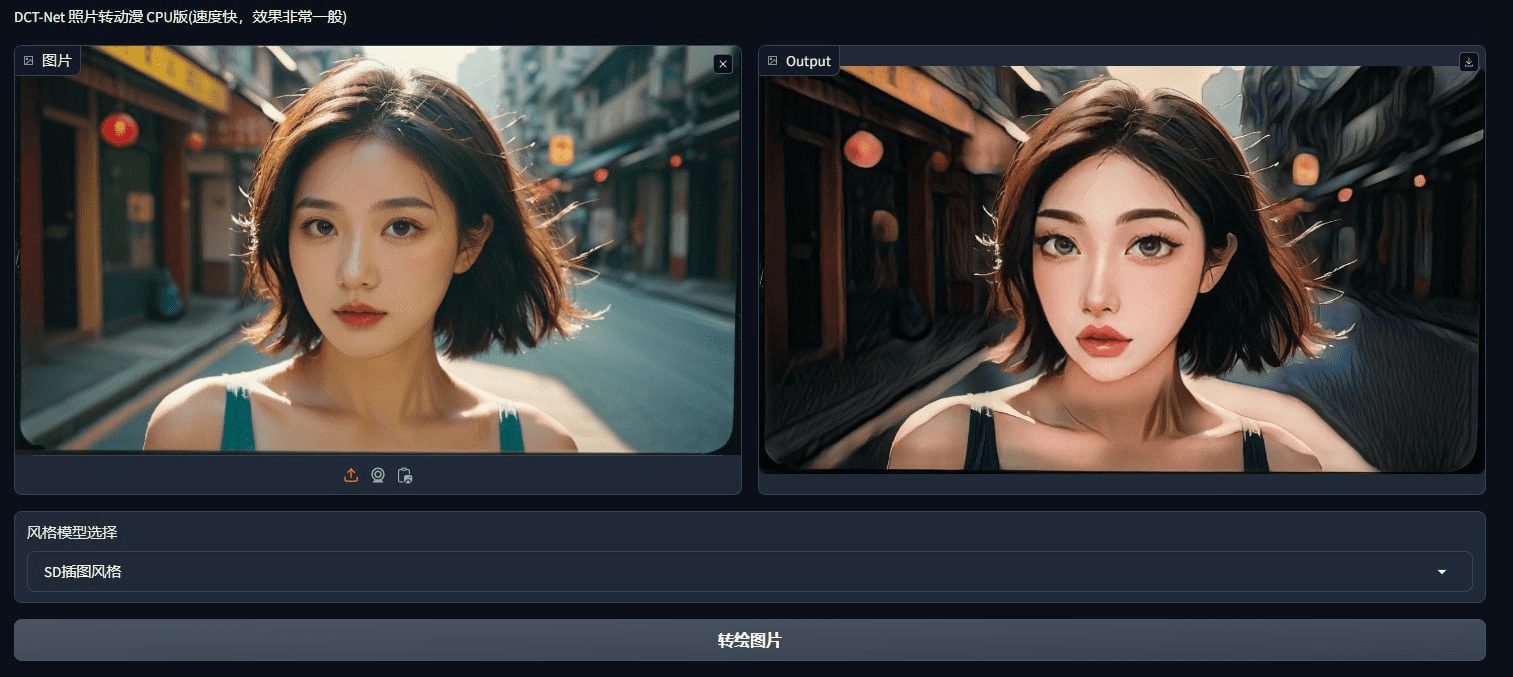
GLM-5V-Turbo是智谱发布首个原生多模态Coding基座模型,专为视觉编程打造。模型从预训练阶段深度融合视觉与文本能力,能直接理解设计稿、网页截图、K线图表等视觉信息并生成可运行代码,实现"所见即所得"的AI编程体验。支持200K超长上下文与128K输出,深度适配Claude Code与OpenClaw/AutoClaw生态,让"龙虾"Agent具备真正的视觉感知能力,在多模态Coding、GUI Agent等核心基准上取得领先表现。

GLM-5V-Turbo的功能特色
- 原生多模态Coding:原生理解图片、视频、设计稿、文档版面等多模态输入,无需中间文本描述,直接进行Vision-to-Code转换。
- 多模态工具调用:支持画框标注、截图识别、网页读取等视觉工具调用,实现从"看图复刻"到"GUI探索复刻"的能力跃升。
- 设计稿还原:发送草图、设计稿或参考网站截图,模型可理解布局、配色、组件层级与交互逻辑,生成完整可运行的前端工程。
- Interactive editing:支持通过对话直接增删页面模块、修改文案样式、调整布局结构,补充按钮反馈、弹窗切换等交互功能。
- 视觉Agent能力:在AutoClaw等龙虾Agent中接入后,可浏览网页和文档,生成图文并茂的报告、PPT,查询并解读K线图等复杂图表。
- 长程规划执行:擅长复杂任务的长程规划与操作执行,支持多步骤工具调用与环境交互。
GLM-5V-Turbo的核心优势
- 视觉与编程能力兼顾:通过30+任务联合强化学习(RL),在引入视觉能力的同时,纯文本编程与推理能力保持同等水准,未出现"跷跷板"效应。
- Extra Long Context Window:支持200K上下文长度,可处理庞大工程项目或长篇技术文档;支持最高128K输出tokens,适合仓库级代码生成。
- 高效推理架构:采用MTP(Multi-Token Prediction)架构与INT8量化加速,提升推理效率与响应速度。
- 深度生态适配:与Claude Code、OpenClaw/AutoClaw等Agent框架深度协同,提供全套官方Skills,开箱即用,实现"感知→规划→执行"完整闭环。
- 领先基准表现:在Design2Code、CC-Bench-V2、AndroidWorld、WebVoyager等多模态Coding与GUI Agent基准上,以更小尺寸超越Claude Opus 4.6等竞品。
- 高性价比API定价:输入$1.2/百万tokens,输出$4/百万tokens,显著低于同类多模态模型。
使用GLM-5V-Turbo的操作步骤
- 通过智谱MaaS平台:访问智谱AI开放平台,选择GLM-5V-Turbo模型,获取API密钥后即可通过标准OpenAI-compatible API调用。
- 通过Vercel AI Gateway:在AI SDK中设置
model: 'zai/glm-5v-turbo',支持统一API调用、用量追踪与自动故障转移。 - 通过OpenRouter:使用OpenRouter统一API接口,支持推理过程展示(reasoning_details)与多提供商路由。
- 在AutoClaw中使用:在AutoClaw Agent设置中切换模型至GLM-5V-Turbo,即可让龙虾获得视觉能力,使用"股票分析师"等视觉Skill。
- 设计稿转代码工作流:上传设计稿截图或录屏→模型自动分析视觉布局→生成前端代码→交互式迭代调整样式与功能。
- GUI自主探索:结合Claude Code框架,发送目标网站链接→模型自主浏览页面结构→采集视觉素材与交互细节→生成完整站点代码。
GLM-5V-Turbo的适用人群
- front-end developer:需要将设计稿快速还原为代码的工程师,特别是处理复杂布局与动效的场景。
- 全栈工程师:构建完整应用时,需要理解视觉界面并生成前后端代码的开发者。
- AI Agent开发者:构建基于OpenClaw/AutoClaw的Agent应用,需要视觉感知能力的开发者。
- financial analyst:需要直接解读K线图、估值区间图和券商研报图表,生成图文交错研报的专业人士。
- Product Managers & Designers:希望将原型草图直接转化为可运行Demo,缩短设计到开发流程的产品团队。
- 自动化测试工程师:需要基于GUI界面进行自动化操作与测试的测试开发者。
GLM-5V-Turbo的常见问题FAQ
Q:GLM-5V-Turbo与GLM-5-Turbo有什么区别?
A:GLM-5V-Turbo在GLM-5-Turbo的编程和Agent能力基础上,从预训练阶段融入了原生视觉能力,是多模态版本。两者在纯文本Coding能力上保持同等水准,但V版本额外支持图像、视频输入与视觉工具调用。
Q:该模型是否开源?
A:目前GLM-5V-Turbo通过智谱MaaS平台开放API接入,未明确宣布开源。如需开源多模态模型,可关注智谱此前开源的GLM-4.5V-Flash。
Q:在纯文本Coding任务上,引入视觉能力后性能会下降吗?
A:不会。通过30+任务联合强化学习,GLM-5V-Turbo在CC-Bench-V2的Backend、Frontend和Repo Exploration三项纯文本基准上均保持稳定表现,部分指标甚至略优于纯文本版本的GLM-5-Turbo。
Q:支持哪些前端技术栈生成?
A:模型可生成包含HTML/CSS、React、Tailwind CSS等技术栈的代码,支持响应式布局与现代化前端框架。
Q:与Claude Opus 4.6相比表现如何?
A:在多模态Coding(Design2Code等)与GUI Agent任务上,GLM-5V-Turbo以更小尺寸取得领先;但在纯文本Coding(后端任务、仓库探索)上,Claude Opus 4.6仍保持优势。
Q:上下文窗口200K是否支持多模态输入?
A:是的,200K上下文支持混合输入文本、图片、视频等多模态内容,适合处理长视频录制或大量技术文档。
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles


No comments...