FireRed-OCR - 小红书团队开源的端到端文档解析模型

FireRed-OCR是什么
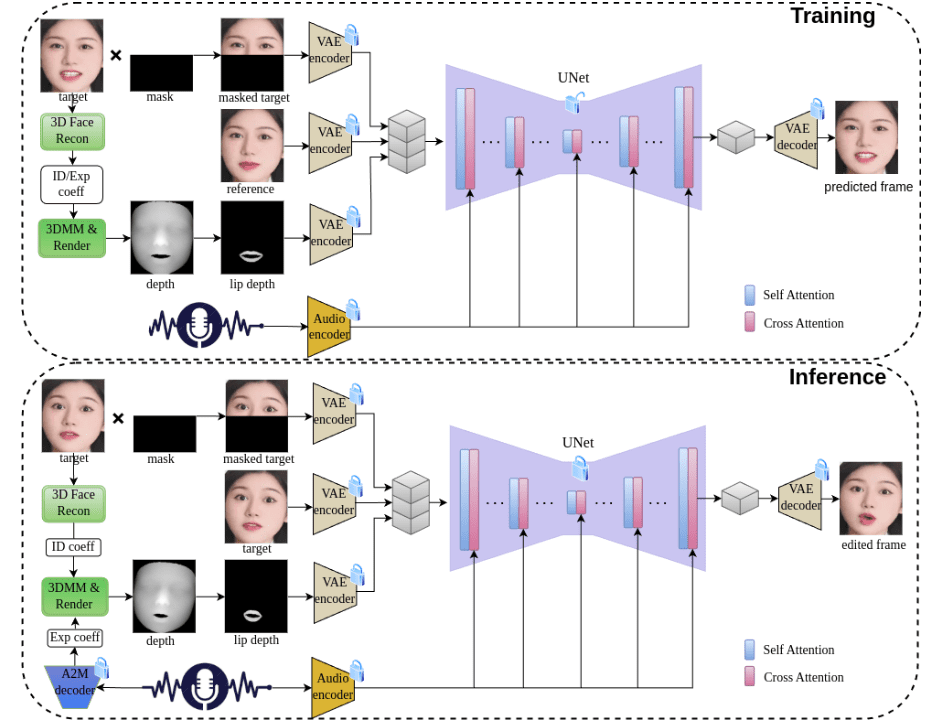
FireRed-OCR 是小红书 Super Intelligence 团队开源的端到端文档解析模型,基于 Qwen3-VL-2B 架构打造,仅用 2B 参数就在 OmniDocBench v1.5 基准测试中斩获 92.94% 综合得分,登顶端到端方案榜首。模型通过三阶段渐进训练策略——多任务预对齐、专项 SFT 微调和格式约束 GRPO 强化学习——有效解决了通用视觉语言模型的"结构幻觉"问题,在表格结构完整性(90.31%)、公式语法合法性(91.71%)和阅读顺序准确性(95.9%)等关键指标上表现卓越。项目采用 Apache 2.0 协议完全开源,支持将 PDF、扫描件、学术论文等复杂文档精准转换为标准 Markdown 格式,为 RAG 系统、知识库建设和企业文档数字化提供了轻量化、高性能的解决方案。

FireRed-OCR的功能特色
- 端到端文档解析:直接输入 PDF 或图片,一键输出标准 Markdown 格式,无需多模块拼接。
- 精准表格重构:表格结构完整性得分 90.31%,自动识别复杂行列对齐与合并单元格。
- 公式识别与 LaTeX 转换:公式语法合法性得分 91.71%,自动修正非法符号,完美还原数学表达式。
- 阅读顺序智能还原:多栏排版场景下阅读顺序准确率达 95.9%,确保内容逻辑连贯。
- 跨语种 OCR 支持:覆盖中英等多语言文档识别,满足国际化需求。
- 轻量化高性能:基于 2B 参数 Qwen3-VL-2B 架构,性能超越 DeepSeek-OCR 2 等超大模型。
- 格式自纠错机制:通过 GRPO 强化学习从公式语法、表格闭合、层级结构、文本准确性四维度自我修正。
- 开源可商用:Apache 2.0 协议,代码与权重完全开放,支持二次开发与企业集成。
FireRed-OCR的核心优势
- SOTA 级性能表现:OmniDocBench v1.5 端到端方案综合得分 92.94%,排名第一,超越 DeepSeek-OCR 2(91.09%)、OCRVerse 及 Gemini-3.0 Pro 等超大模型。
- 极致轻量化架构:仅 2B 参数,基于 Qwen3-VL-2B 打造,部署成本低,推理速度快,适合边缘端和云端多种场景。
- 解决结构幻觉难题:针对通用视觉语言模型常见的表格错位、公式乱码、阅读顺序混乱等问题专项优化,输出稳定可靠。
- 三阶段渐进训练:多任务预对齐建立像素级空间感知,专项 SFT 强化结构表达,格式约束 GRPO 实现自我纠错,层层递进提升精度。
- 几何+语义数据引擎:通过几何聚类识别版式重叠与稀缺类型,多维 Tag 体系分层均衡采样,数据质量与多样性双保障。
- Open Source Ecology Improvement:GitHub、HuggingFace、ModelScope 全平台托管,提供在线 Demo 即开即用,Apache 2.0 协议无商业限制。
- 专业化场景适配:在金融报表、学术论文、法律合同、医疗病历等复杂版式场景下表现稳定,满足企业级文档数字化需求。
FireRed-OCR官网是什么
- Github repository:https://github.com/FireRedTeam/FireRed-OCR
FireRed-OCR的适用人群
- AI 开发者与工程师:需集成文档解析能力的 RAG 系统、知识库、智能客服、数据分析平台开发者,轻量化架构易于部署和二次开发。
- 企业数字化团队:金融、法律、医疗、政务等行业需批量处理扫描件、合同、报表、病历等结构化文档的 IT 部门。
- academic researcher:从事文档理解、多模态大模型、OCR 技术方向的研究人员,开源权重和详细技术报告助力复现与创新。
- 内容创作者与编辑:需快速提取 PDF、图片中的文字、表格、公式并转换为 Markdown 用于二次创作的自媒体、知识博主。
- Educational and training institutions:需将教材、试卷、讲义数字化并保留复杂排版结构的在线教育平台与出版社。
- 数据标注与 AI 训练团队:需高质量文档解析结果作为下游任务训练数据的机器学习工程师。
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts

No comments...