
FineVision - Open Source Visual Language Dataset from Hugging Face

What is FineVision
FineVision is Hugging Face's open source visual language dataset for training advanced visual language models. It contains 17.3 million images, 24.3 million samples, 88.9 million rounds of dialog, and 9.5 billion answer tokens. The dataset aggregates data from more than 200 sources, features multimodal and multi-round conversations, and supports the combination of visual and verbal. Each image is accompanied by a text caption that helps the model understand and generate natural language.FineVision helped the model improve performance by more than 20% on average across 10 benchmarks. Using Hugging Face's datasets The library makes it easy to load and use datasets.
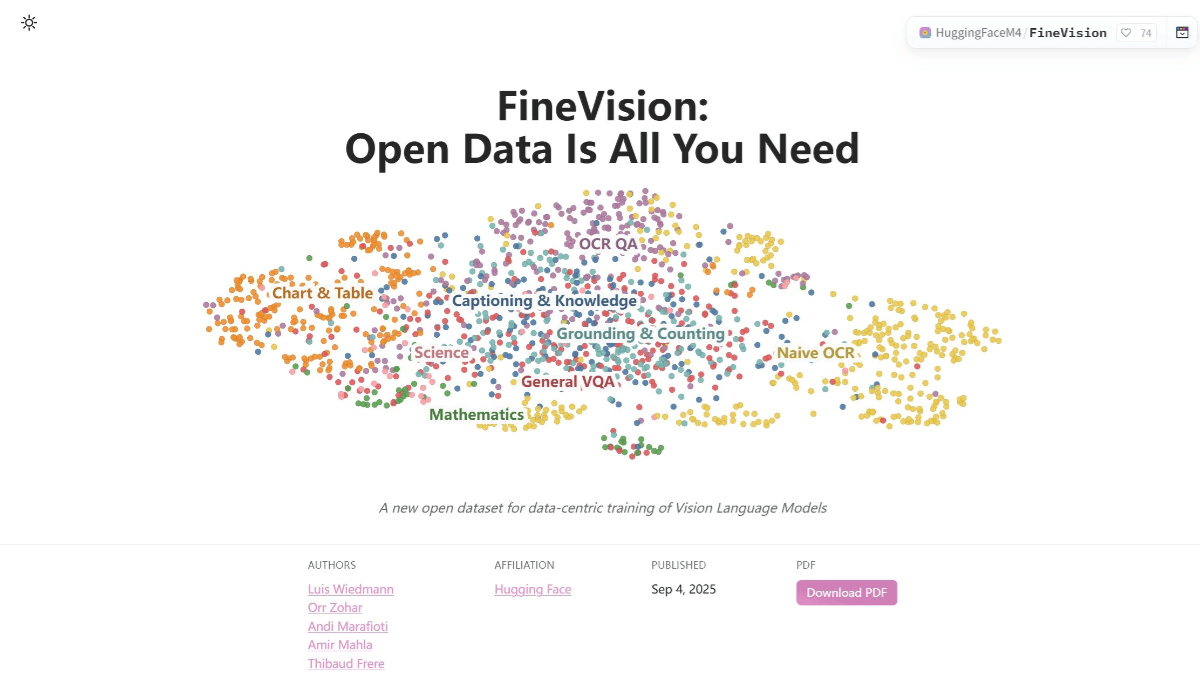
FineVision Features
- multimodal fusion: Combining images and text allows the model to process both visual and verbal information, improving the understanding of complex scenes.
- Multi-round dialog data: Provide rich multi-round dialog samples to help the model learn natural language communication patterns and enhance interaction capabilities.
- Massive data volume: Having massive image and text samples provides sufficient resources for model training and enhances model generalization.
- Significant performance improvements: Help models significantly improve performance in multiple benchmarks and advance visual language modeling technology.
- open source and easy to use: Through Hugging Face's
datasetslibrary, users can easily load and use the dataset, lowering the barrier to use.
FineVision's core strengths
- The sheer size of the data: Contains massive image and text samples to provide sufficient resources for model training.
- multimodal fusion: Integrating images and text to improve the model's ability to process visual and verbal information together.
- Multi-Round Dialog Support: Rich multi-round dialog data to enhance the model's interaction capability and depth of language understanding.
What is FineVision's official website?
- Project website:: https://huggingface.co/spaces/HuggingFaceM4/FineVision
- HuggingFace dataset:: https://huggingface.co/datasets/HuggingFaceM4/FineVision
Who FineVision is for
- Artificial intelligence researchers: for developing and optimizing visual language models and exploring new algorithms and architectures.
- Machine Learning Engineer: Apply FineVision datasets in real projects to improve model performance.
- natural language processing (NLP) expert: Focus on improving the language understanding and generation of models.
- Computer vision specialists: Using image data to improve visual recognition and understanding.
- data scientist: Analyze and process large-scale multimodal data to mine its value.
- Students and educators: serve as instructional resources to help students understand and practice visual language modeling.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...