DeepSeek-OCR 2 - DeepSeek团队开源的新一代OCR模型

DeepSeek-OCR 2是什么
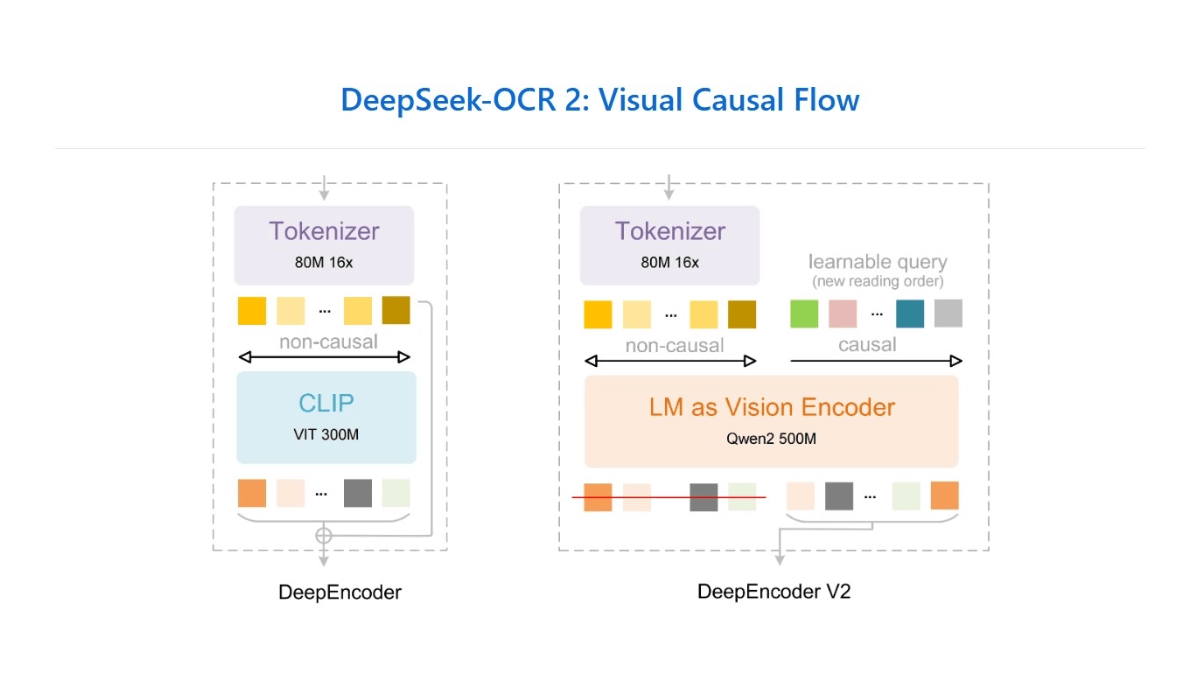
DeepSeek-OCR 2是DeepSeek团队开源的新一代OCR模型,核心创新在于采用DeepEncoder V2架构,将传统固定栅格扫描的视觉编码方式升级为基于语义推理的动态处理。模型通过因果流查询和双流注意力机制,能按图像内容逻辑自动重排视觉信息,非机械地按空间顺序处理,显著提升了复杂文档(如表格、公式混排)的识别效果。在OmniDocBench v1.5基准测试中,整体得分达91.09%,较前代提升3.73%,尤其在阅读顺序准确率方面表现突出。模型采用3B参数的混合专家解码器,视觉token预算控制在1120个以内,兼顾性能与效率。
DeepSeek-OCR 2的功能特色
- 视觉因果流:先用可学习“因果流查询”对图像语义重排,再送入LLM解码,模拟人类跳跃式阅读,阅读顺序编辑距离从0.085降到0.057。
- DeepEncoder V2:弃用CLIP,改用类LLM双流注意力,视觉token双向全局建模,因果token单向动态排序,仅重排后token进入下游,算力持平。
- 极限压缩:一张图只留256–1120个视觉token,与Gemini-1.5 Pro上限对齐,下游计算量显著低于同类模型。
- 精度跃迁:OmniDocBench v1.5综合得分91.09%,较前代提升3.73%,字符/单词准确率分别提高8.4和10.9个百分点。
- Open source friendly:Apache-2.0协议,模型与论文同步放GitHub与Hugging Face,一键调用。
DeepSeek-OCR 2的核心优势
- build:DeepEncoder V2 取代 CLIP,引入“视觉因果流”,先语义重排再 1D 因果推理,阅读顺序编辑距离从 0.085 降到 0.057,更接近人类逻辑。
- performances:OmniDocBench v1.5 综合得分 91.09%,较前代提升 3.73%;字符准确率 82.7%→91.1%,单词准确率 75.0%→85.9%。
- efficiency:视觉 Token 上限 256–1120,与 Gemini-3 Pro 持平,不增算力。
- expand one's financial resources:Apache-2.0 协议,Hugging Face 可直接调用。
DeepSeek-OCR 2官网是什么
- GitHub repository:https://github.com/deepseek-ai/DeepSeek-OCR-2
- HuggingFace Model Library:https://huggingface.co/deepseek-ai/DeepSeek-OCR-2
- Technical Papers:https://github.com/deepseek-ai/DeepSeek-OCR-2/blob/main/DeepSeek_OCR2_paper.pdf
DeepSeek-OCR 2的适用人群
- financial practitioner:银行、保险、券商需把海量票据、合同、回单秒级结构化,直接喂给风控与审计系统。
- 医疗信息科:面对手写病历、化验单、影像报告,高鲁棒识别减少人工录入,加速电子病历评级。
- 教育出版方:教辅、试卷、古籍多栏复杂版面一键转LaTeX/Word,排版工人告别加班。
- 科研工作者:批量提取论文中的公式、表格、跨页图表,做文献综述或知识图谱不再手动敲字。
- 档案与古籍数字化团队:对泛黄、破损、竖排、无框线文档仍保持90%+准确率,挽救历史资料。
- 开发者与SaaS厂商:Apache-2.0开源,可商用集成,低成本给自家产品加“拍图识字”超能力。
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts

No comments...