
Design and Implementation of DeepSearch and DeepResearch


It's only February, and Deep Search is already looming as the new search standard for 2025. Giants like Google and OpenAI have unveiled their "Deep Research" products in an effort to capitalize on this wave of technology. (We're also proud to have released our open-sourcenode-deepresearch).
Perplexity followed suit with their Deep Research, while Musk's X AI went a step further by integrating deep search capabilities directly into their Grok 3 model, which is essentially a variant of Deep Research.
Frankly, the concept of deep search isn't much of an innovation; it's essentially what we used to call RAG (Retrieval Augmented Generation) or multihop quizzing last year. But at the end of January this year, with Deepseek-r1 s release, it has gained unprecedented attention and growth.
Just last weekend, both Baidu Search and Tencent WeChat Search have integrated Deepseek-r1 into their search engines.AI engineers realized that theBy incorporating long-term thinking and reasoning processes into the search system, it is possible to achieve more accurate and in-depth retrieval than ever before.
But why is this shift happening now? Throughout 2024, "Deep(Re)Search" doesn't seem to have attracted much attention. It should be remembered that in early 2024, the Stanford NLP Lab released the STORM Project, web-based long-form report generation. Is it just because "Deep Search" sounds more fashionable than more QA, RAG or STORM? But let's be honest, sometimes a successful rebranding is all it takes for the industry to suddenly embrace something that's already there.
We think the real tipping point is OpenAI's September 2024 release of theo1-previewIt introduced the concept of "test-time compute" and subtly changed the perception of the industry.The term "compute while reasoning" refers to investing more computational resources in the reasoning phase (i.e., the phase in which the large language model generates the final result), rather than focusing on the pre-training or post-training phases. Classical examples include Chain-of-Thought (CoT) reasoning, as well as approaches such as"Wait" Techniques such as injection (also known as budget control) which give the model a wider scope for internal reflection, such as evaluating multiple potential answers, more in-depth planning, and self-reflection before giving a final answer.
This concept of "compute while reasoning" and the modeling that focuses on reasoning are leading users to accept a concept of "delayed gratification":Trade longer wait times for higher quality, more useful results. Like the famous Stanford Marshmallow Experiment, kids who can resist the temptation to eat one marshmallow right away so they can get two marshmallows later tend to have better long-term success. deepseek-r1 further solidifies this user experience, which most users have implicitly accepted whether you like it or not.
This marks a significant departure from traditional search needs. In the past, if your solution couldn't give a response within 200 milliseconds, it was pretty much tantamount to failure. But in 2025, experienced search developers and RAG Engineers, put top-1 precision and recall before latency. Users have gotten used to longer processing times: as long as they can see the system trying to<thinking>The
In 2025, displaying the reasoning process has become a standard practice, with many chat interfaces rendered in dedicated UI areas <think> The content.
In this paper, we will discuss the principles of DeepSearch and DeepResearch by examining our open source implementation. We will present key design decisions and point out potential caveats.
What is Deep Search?
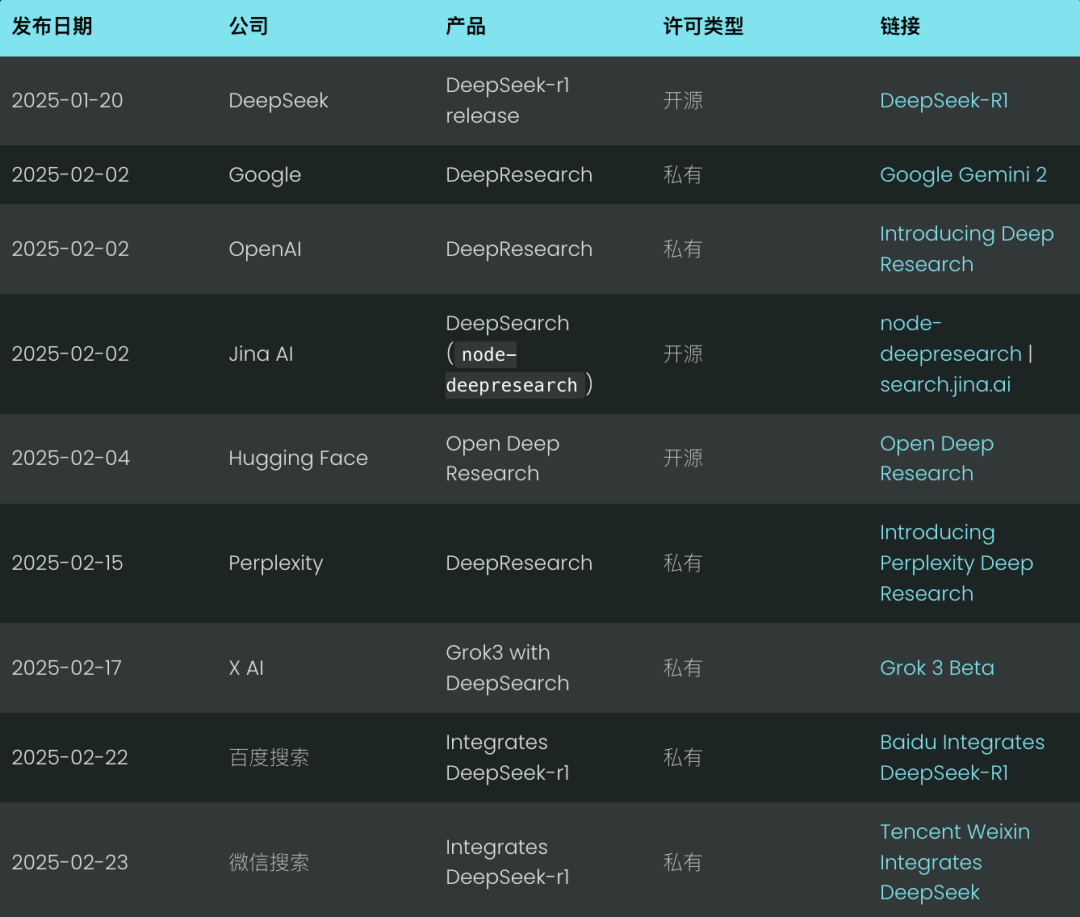
The core idea of DeepSearch is to find the optimal answer by cycling through the three stages of searching, reading and reasoning until the optimal answer is found. The search session explores the Internet using a search engine, while the reading session focuses on exhaustive analysis of specific web pages (e.g., using Jina Reader). The reasoning session is responsible for evaluating the current state and deciding whether the original problem should be broken down into smaller sub-problems or alternative search strategies should be tried.
 DeepSearch - Continuously searching, reading web pages, and reasoning until the answer is found (or exceeded) token (Budget).
DeepSearch - Continuously searching, reading web pages, and reasoning until the answer is found (or exceeded) token (Budget).
Unlike the 2024 RAG system, which typically runs a single search-generation process, DeepSearch performs multiple iterations that require explicit stopping conditions. These conditions can be based on token usage limits, or the number of failed attempts.
Try DeepSearch at search.jina.ai and observe the <thinking>in it to see if you can spot where the loop occurs.
Put another way.DeepSearch can be viewed as an LLM Agent equipped with various web tools such as search engines and web readers.This Agent analyzes the current observations and past actions to determine the next course of action: whether to give an answer directly or to continue exploring the network. This builds a state machine architecture, where the LLM is responsible for controlling the transitions between states.
At each decision point, you have two options available to you: you can craft the cue words so that the standard generative model produces specific action instructions; or, alternatively, you can utilize a specialized inference model like Deepseek-r1 to naturally derive the next action that should be taken. However, even with r1, you will need to periodically interrupt its generative process to inject the tool's output (e.g., search results, web page content) into the context and prompt it to continue with the reasoning process.
Ultimately, these are just implementation details. Whether you're crafting cue words or just using an inference model, theThey all follow the core design principles of DeepSearch: search, read, and inferenceof the continuing cycle.
And what is DeepResearch?
DeepResearch adds to DeepSearch a structured framework for generating long-form research reports. Its workflow generally starts with the creation of a table of contents, and then systematically applies DeepSearch to each required section of the report: from the introduction, to the related work, to the methodology, to the final conclusion. Each section of the report is generated by feeding specific research questions into DeepSearch. Finally, all sections are integrated into a single cue to improve the coherence of the overall narrative of the report.
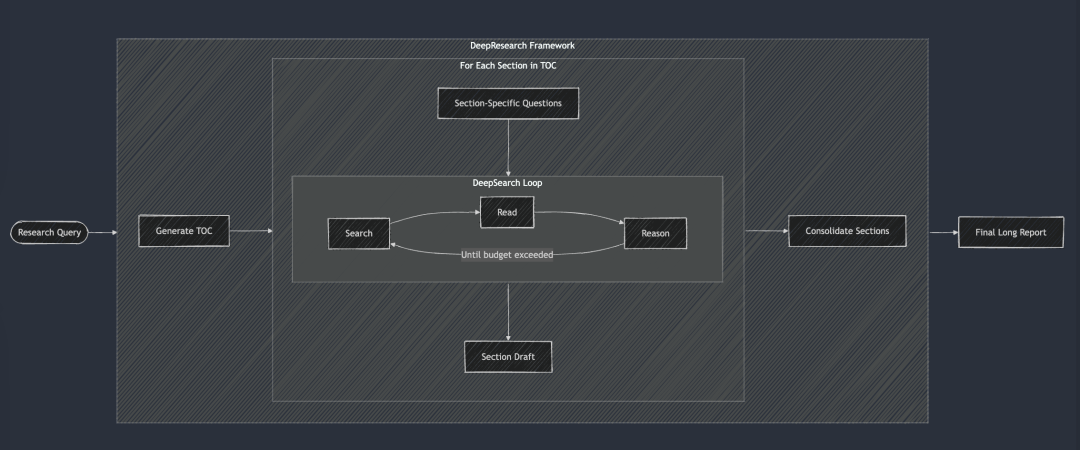 DeepSearch serves as the base building block for DeepResearch. Each chapter is built iteratively through DeepSearch and then the overall coherence is improved before the final long report is generated.
DeepSearch serves as the base building block for DeepResearch. Each chapter is built iteratively through DeepSearch and then the overall coherence is improved before the final long report is generated.
In 2024, we also did the "Research" project internally, and at that time, in order to ensure the consistency of the report, we adopted a rather dumb approach, taking all chapters into account in each iteration, and making multiple consistency improvements. But now it seems that this approach is a bit too hard, because today's large language model has a super-long context window, and it is possible to complete the coherence revision in one go, and the result is better instead.
However, we did not release the "Research" project for several reasons:
Most notably, the quality of the reports consistently failed to meet our internal standards. We tested it with two familiar internal queries: "Jina AI's Competitor Analysis" and "Jina AI's Product Strategy". The results were disappointing, the reports were mediocre and lackluster, and didn't give us any "ah-ha" surprises. Secondly, the reliability of the search results is poor, and the illusion is a serious problem. Finally, the overall readability is poor, with a lot of repetitive redundancies between sections. In short, it's worthless. And the report is so long that it's both a waste of time and unproductive to read.
However, this program also gave us valuable experience and spawned a number of sub-products:
For example.We were keenly aware of the reliability of search results and the importance of fact-checking at the paragraph and even sentence level, which directly led to the subsequent development of the g.jina.ai endpoint.We also realized the value of query expansion and started investing effort in training small language models (SLMs) for query expansion. Finally, we really liked the name ReSearch, which is both a clever expression of the idea of reinventing search and a pun. It was a shame not to use it, so we ended up using it for the 2024 yearbook.
In the summer of 2024, our "Research" project took an "incremental" approach, focusing on generating longer reports. It begins by synchronizing the report's Table of Contents (TOC) and then synchronizes the content of all chapters. Finally, each chapter is incrementally revised in an asynchronous manner, with each revision taking into account the overall content of the report. In the demo video above, the query we used was "Competitive Analysis for Jina AI".
DeepSearch vs DeepResearch
Many people tend to confuse DeepSearch with DeepResearch. But in our opinion, they solve completely different problems.DeepSearch is the building block of DeepResearch, the core engine on which the latter runs.
DeepResearch's focus is on writing high-quality, readable, long-form research reports.It's not just about searching for information, it's a systematic projectThe DeepSearch project was designed to be a powerful tool for the search industry, requiring the integration of effective visualization elements (e.g., charts, tables), a logical chapter structure that ensures sub-chapters flow logically, consistent terminology throughout the text, avoidance of redundancy of information, and the use of smooth transitions to connect the contexts. These elements are not directly related to the underlying search functionality, which is why we are focusing more on DeepSearch as a company.
To summarize the differences between DeepSearch and DeepResearch, see the table below. It is worth mentioning thatBoth DeepSearch and DeepResearch are inseparable from long context and inference models, but for slightly different reasons.
DeepResearch requires long context to generate long reports, which is understandable. And while DeepSearch may appear to be a search tool, it also needs to memorize previous search attempts and web page content in order to plan subsequent operations, so long contexts are equally indispensable.

Learn about the DeepSearch implementation
Open Source Link: https://github.com/jina-ai/node-DeepResearch
At the heart of DeepResearch is its circular reasoning mechanism. Unlike most RAG systems that try to answer questions in one step, we use an iterative loop. It continues to search for information, read relevant sources, and reason until it finds an answer or runs out of token budget. Here's a condensed skeleton of this large while loop:
// 主推理循环
while (tokenUsage < tokenBudget && badAttempts <= maxBadAttempts) {
// 追踪进度
step++; totalStep++;// Get the current issue from the gaps queue, or use the original issue if it's not available
const currentQuestion = gaps.length > 0 ? gaps.shift() : question;/
/ Generate prompts based on the current context and allowed actions
system = getPrompt(diaryContext, allQuestions, allKeywords.
allowReflect, allowAnswer, allowRead, allowSearch, allowCoding.
badContext, allKnowledge, unvisitedURLs);/
/ Let LLM decide what to do next
const result = await LLM.generateStructuredResponse(system, messages, schema);
thisStep = result.object;/
/ Perform the selected action (answer, reflect, search, visit, code)
if (thisStep.action === 'answer') {
// Process answer actions...
} else if (thisStep.action === 'reflect') {
// Processing reflective actions...
} // ... And so on for the other actions
}To ensure that the output is stable and structured, we have taken a key step:Selectively disable certain operations at each step.
For example, we disable the "visit" operation when there is no URL in memory, and we prevent the Agent from repeating the "answer" operation immediately if the last answer was rejected. This constraint mechanism guides the Agent in the right direction and prevents it from circling around in the same place.
system cue
For the design of the system prompts, we use XML tags to define the various parts, which allows us to generate more robust system prompts and generated content. At the same time, we found that the JSON Schema directly in the description field constraints in the field for better results. It is true that an inference model like DeepSeek-R1 can theoretically generate most of the cue words automatically. However, given the limitations of context length and our need for fine-grained control of Agent behavior, this way of explicitly writing cue words is more reliable in practice.
function getPrompt(params...) {
const sections = [];// Add a Header containing system commands
sections.push("You're a senior AI research assistant specializing in multi-step reasoning...") ;
// Add accumulated knowledge fragments (if they exist)
if (knowledge?.length) {
sections.push("[knowledge entry]");;
}// Add contextual information from previous actions
if (context?.length) {
sections.push("[Action History]");;
}
// Add failed attempts and learned strategies
if (badContext?.length) {
sections.push("[failed attempts]");;
sections.push("[improved strategy]");;
}
// Define available action options based on the current state
sections.push("[available action definitions]");;
// Add response formatting instructions
sections.push("Please respond in a valid JSON format and strictly match the JSON schema.");;
return sections.join("nn");
}
Traversing the knowledge gap problem
In DeepSearch.A "knowledge gap question" refers to a knowledge gap that Agent needs to fill before answering the core question.Instead of trying to answer the original question directly, the Agent identifies and solves sub-questions that build the necessary knowledge base.
This is a very elegant way to handle it.
// 在“反思行动”中识别出知识空白问题后
if (newGapQuestions.length > 0) {
// 将新问题添加到队列的头部
gaps.push(...newGapQuestions);// Always add the original question to the end of the queue
gaps.push(originalQuestion);
}
It creates a FIFO (First In First Out) queue with a rotation mechanism that follows the following rules:
- New knowledge gap questions are prioritized and pushed to the head of the queue.
- The original question is always at the end of the queue.
- The system extracts issues from the queue header at each step for processing.
The subtlety of this design is that it maintains a shared context for all problems. That is, when a knowledge gap problem is solved, the knowledge gained can be immediately applied to all subsequent problems, and will eventually help us solve the original original problem as well.
FIFO queue vs recursion
In addition to FIFO queues, we can also use recursion, which corresponds to a depth-first search strategy. For each "knowledge gap" problem, recursion creates a new call stack with a separate context. The system must completely solve each knowledge gap problem (and all its potential subproblems) before returning to the parent problem.
As an example, a simple 3-level deep knowledge gap problem recursion with numbers in circles labeling the order in which the problems are solved.
In recursive mode, the system must fully solve Q1 (and its possible derived sub-problems) before it can move on to other problems! This is in contrast to the queue approach, which would revert to Q1 after dealing with 3 knowledge gap problems.
In practice, we have found that recursive methods are difficult to control the budget. Because subproblems may continue to spawn new subproblems, it is difficult to determine how much Token budget should be allocated to them without clear guidelines. The advantage of recursion in terms of clear contextual isolation pales in comparison to the complexity of budget control and the potential for delayed returns. In contrast, the design of FIFO queues balances depth and breadth well, ensuring that the system builds knowledge, improves incrementally, and ultimately returns to the original problem rather than sinking into a potentially infinite recursive quagmire.
Query Rewrite
One rather interesting challenge we encountered was how to effectively rewrite the user's search query:
// 在搜索行为处理器中
if (thisStep.action === 'search') {
// 搜索请求去重
const uniqueRequests = await dedupQueries(thisStep.searchRequests, existingQueries);// Rewrite natural language queries into more efficient search expressions
const optimizedQueries = await rewriteQuery(uniqueRequests);
// Ensure no duplication of previous searches
const newQueries = await dedupQueries(optimizedQueries, allKeywords);
// Perform a search and store the results
for (const query of newQueries) {
const results = await searchEngine(query);
if (results.length > 0) {
storeResults(results);
allKeywords.push(query);
}
}
}
We found thatQuery rewriting is far more important than expected and is arguably one of the most critical factors in determining the quality of search results.A good query rewriter not only transforms the user's natural language into something more suitable for the BM25 The algorithms process keyword forms that also extend the query to cover more potential answers in different languages, tones, and content formats.
In terms of query de-duplication, we initially tried an LLM-based scheme, but found that it was difficult to precisely control the similarity threshold, and the results were not satisfactory. In the end, we chose the jina-embeddings-v3. Its excellent performance on the semantic text similarity task allowed us to easily achieve cross-language de-duplication without having to worry about non-English queries being filtered by mistake. Coincidentally, it was the Embedding model that ultimately played a key role. We didn't intend to use it for in-memory retrieval at first, but we were surprised to find that it performed very efficiently on the de-duplication task.
Crawling web content
Web crawling and content processing is also a crucial part of the process, where we use the Jina Reader API. In addition to the full web page content, we collect summary snippets returned by the search engine as supporting information for subsequent reasoning. These snippets can be viewed as a concise summary of the web page content.
// 访问行为处理器
async function handleVisitAction(URLs) {
// 规范化并过滤已访问过的 URL
const uniqueURLs = normalizeAndFilterURLs(URLs);// Process each URL in parallel
const results = await Promise.all(uniqueURLs.map(async url => {
try {
// Fetch and extract content
const content = await readUrl(url);
// Stored as knowledge
addToKnowledge(`What is in ${url}? `, content, [url], 'url').
return {url, success: true};
} catch (error) {
return {url, success: false};
} finally {
visitedURLs.push(url);
}
}));
// Update logs based on results
updateDiaryWithVisitResults(results).
}
To facilitate tracing, we normalize the URLs and limit the number of URLs accessed at each step to control the memory footprint of the agent.
memory management
A key challenge in multi-step reasoning is how to effectively manage agent memory. The memory system we designed distinguishes between what counts as "memory" and what counts as "knowledge". But in any case, they are all part of the LLM cue context, separated by different XML tags:
// 添加知识条目
function addToKnowledge(question, answer, references, type) {
allKnowledge.push({
question: question,
answer: answer,
references: references,
type: type, // 'qa', 'url', 'coding', 'side-info'
updated: new Date().toISOString()
});
}// Record steps to the log
function addToDiary(step, action, question, result, evaluation) {
diaryContext.push(`
In step ${step}, you took **${action}** on the question: "${question}".
[Details and results] [Assessment (if any)] `); and
}
Given the trend towards very long contexts in LLM 2025, we have chosen to abandon vector databases in favor of a contextual memory approach.The Agent's memory consists of three parts within a context window: acquired knowledge, visited websites, and logs of failed attempts. This approach allows the Agent to directly access the complete history and state of knowledge during the reasoning process without additional retrieval steps.
Evaluation of answers
We also found that answer generation and assessment were better accomplished by placing them in different cue words.In our implementation, when a new question is received, we first identify the evaluation criteria and then evaluate them on a case-by-case basis. The evaluator refers to a small number of examples for consistency assessment, which is more reliable than self-assessment.
// 独立评估阶段
async function evaluateAnswer(question, answer, metrics, context) {
// 根据问题类型确定评估标准
const evaluationCriteria = await determineEvaluationCriteria(question);// Evaluate each criterion individually
const results = [];
for (const criterion of evaluationCriteria) {
const result = await evaluateSingleCriterion(criterion, question, answer, context);
results.push(result);
}
// Determine whether the answer passes the overall assessment
return {
pass: results.every(r => r.pass),
think: results.map(r => r.reasoning).join('n')
};
}
Budgetary control
Budgetary control is not just about cost savings, but about ensuring that the system adequately addresses issues before the budget is exhausted and avoids returning answers prematurely.Since the release of DeepSeek-R1, our thinking about budget control has shifted from simply saving budgets to encouraging deeper thinking and striving for high-quality answers.
In our implementation, we explicitly require the system to identify knowledge gaps before attempting to answer.
if (thisStep.action === 'reflect' && thisStep.questionsToAnswer) {
// 强制深入推理,添加子问题
gaps.push(...newGapQuestions);
gaps.push(question); // 别忘了原始问题
}
By having the flexibility to enable and disable certain actions, we can direct the system to utilize tools that deepen reasoning.
// 在回答失败后
allowAnswer = false; // 强制代理进行搜索或反思
To avoid wasting tokens on invalid paths, we limit the number of failed attempts. When approaching the budget limit, we activate "Beast Mode" to make sure we give an answer anyway and avoid going home empty-handed.
// 启动野兽模式
if (!thisStep.isFinal && badAttempts >= maxBadAttempts) {
console.log('Enter Beast mode!!!');// Configure prompts to guide decisive answers
system = getPrompt(
diaryContext, allQuestions, allKeywords.
false, false, false, false, false, false, // disable other operations
badContext, allKnowledge, unvisitedURLs.
true // Enable Beast Mode
);
// Force answer generation
const result = await LLM.generateStructuredResponse(system, messages, answerOnlySchema);
thisStep = result.object;
thisStep.isFinal = true;
}
The Beast Mode prompt message is deliberately overstated, clearly informing the LLM that it must now make a decisive decision and give an answer based on the available information!
<action-answer>
🔥 启动最高战力! 绝对优先! 🔥Prime Directive:
- Eliminate all hesitation! It is better to give an answer than to remain silent!
- A localized strategy can be adopted - using all known information!
- Allow reuse of previous failed attempts!
- When you can't make up your mind: Based on available information, strike decisively!
Never allow failure! Be sure to reach your goals! ⚡️
</action-answer>
This ensures that even when faced with difficult or vague questions, we can give a usable answer rather than nothing.
reach a verdict
DeepSearch can be said to be an important breakthrough in search technology in dealing with complex queries. It breaks down the whole process into independent search, reading and reasoning steps, overcoming many of the limitations of traditional single-round RAGs or multi-hop Q&A systems.
During the development process, we have been constantly reflecting on what the future search technology base should look like in 2025, in the face of the drastic changes in the entire search industry after the release of DeepSeek-R1. What new needs are emerging? What needs are obsolete? What needs are actually pseudo-needs?
Looking back at the DeepSearch implementation, we've carefully summarized what was expected and essential, what we took for granted and didn't really need, and what we didn't anticipate at all but turned out to be critical.
First.A long context LLM that generates output in a canonical format (e.g. JSON Schema) is essential. Perhaps an inference model is also needed to enhance action reasoning and query expansion.
Query extensions are also absolutely necessary, whether it is implemented using SLM, LLM, or a specialized inference model, is an inextricable link. However, after doing this project, we realized that SLM may not be well suited for this task, because query expansion must be inherently multilingual and cannot be limited to simple synonym replacement or keyword extraction. It has to be comprehensive enough to have a Token base that covers multiple languages (so that the scale can easily reach 300 million parameters), and it has to be smart enough to think outside the box. So, query scaling by SLM alone may not work.
Web searching and web reading skills are, without a doubt, top prioritiesLuckily, our [Reader (r.jina.ai)] has performed very well and is not only powerful but also scalable, which has inspired me to think about how we can improve our search endpoint (s.jina.ai) are many inspirations that can be focused on optimizing in the next iteration.
Vector modeling is useful, but used in completely unexpected places. We originally thought it would be used for in-memory retrieval, or in conjunction with vector databases to compress context, but neither proved necessary. Ultimately, we found that it worked best to use the vector model for de-duplication, essentially an STS (semantic text similarity) task. Since the number of queries and knowledge gaps is usually in the range of hundreds, it is perfectly sufficient to compute the cosine similarity directly in memory without the need to utilize a vector database.
We did not use the Reranker model, but theoretically, it can assist in determining which URLs should be prioritized for access based on the query, URL title, and summary snippet. For the Embeddings and Reranker models, multilingual capabilities are a basic requirement, since queries and questions are multilingual. Long context processing is helpful for the Embeddings and Reranker models, but is not a decisive factor. We did not encounter any problems caused by the use of vectors, probably thanks to the fact that the jina-embeddings-v3 (an excellent context length of 8192 tokens). Taken together, thejina-embeddings-v3 cap (a poem) jina-reranker-v2-base-multilingual Still my first choice, they have multi-language support, SOTA performance, and good long context handling.
The Agent framework ultimately proved to be unnecessary. In terms of system design, we preferred to stay close to the native capabilities of LLMs and avoided introducing unnecessary abstraction layers.The Vercel AI SDK provides a great deal of convenience in adapting to different LLM vendors, which greatly reduces the amount of development effort, with only one line of code change in the Gemini Switching between Studio, OpenAI and Google Vertex AI. Proxy memory management makes sense, but introducing a specialized framework for it is questionable. Personally, I think that over-reliance on frameworks can build a barrier between LLM and the developer, and the syntactic sugar they provide can become a burden to the developer. Many LLM/RAG frameworks have already validated this. It is wiser to embrace the native capabilities of LLM and avoid being tied down by frameworks.
This post is from WeChat: Jina AI
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles


No comments...