
450 to train an 'o1-preview'?UC Berkeley open-sources 32B inference model Sky-T1, AI community abuzz

The price of $450 doesn't sound like a lot at first. But what if that's the entire cost of training a 32B inference model?
Yes, as we come to 2025, inference models are becoming easier to develop and rapidly decreasing in cost to levels we couldn't have imagined before.
Recently, NovaSky, a research team at UC Berkeley's Sky Computing Lab, released Sky-T1-32B-Preview.Interestingly, the team says, "Sky-T1-32B-Preview costs less than $450 to train, which suggests that it is possible to economically and efficiently replicate high-level reasoning capabilities."

- Project homepage: https://novasky-ai.github.io/posts/sky-t1/
- Open source address: https://huggingface.co/NovaSky-AI/Sky-T1-32B-Preview
According to official information, this inference model matched an earlier version of OpenAI o1 in several key benchmarks.

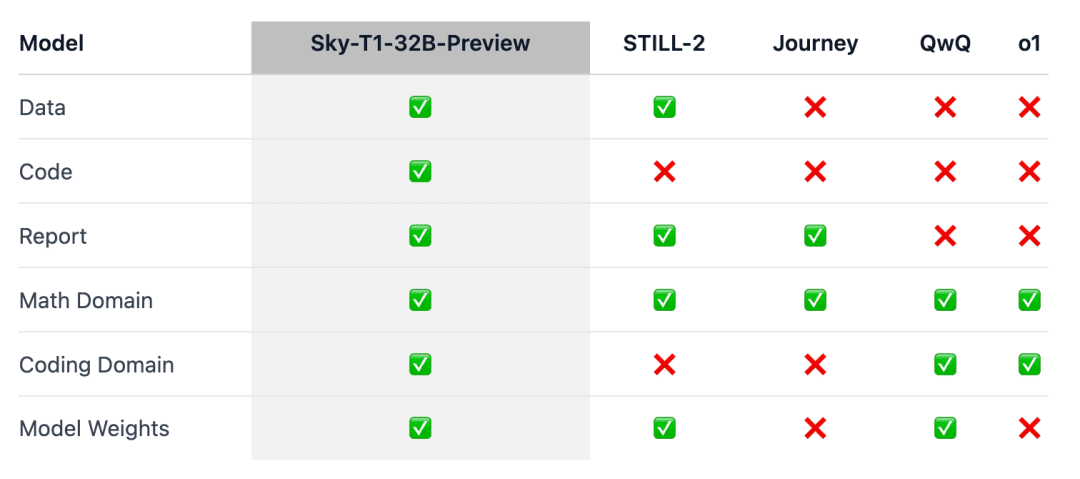
The point is that Sky-T1 appears to be the first truly open-source inference model, as the team released the training dataset as well as the necessary training code for anyone to replicate it from scratch.
Everyone exclaimed, "What an amazing contribution of data, code and model weights."
Not long ago, the price of training a model with equivalent performance often ran into millions of dollars. Synthetic training data or training data generated by other models has allowed a significant reduction in cost to be realized.
Previously, an AI company, Writer, released the Palmyra X 004, which was trained almost entirely on synthetic data and cost only $700,000 to develop.
Imagine running this program on the Nvidia Project Digits AI supercomputer, which sells for $3,000 (cheap for a supercomputer) and can run models with up to 200 billion parameters. In the near future, models with less than 1 trillion parameters will be run locally by individuals.
The evolution of big model technology in 2025 is accelerating, and that's a really strong feeling.
Model overview
The o1 who specializes in reasoning and Gemini 2.0 Models such as flash thinking have solved complex tasks and made other advances by generating long internal chains of thought. However, technical details and model weights are not available, which poses a barrier to participation by academia and the open source community.
To this end, there have been some notable results in the field of mathematics for training open-weighted inference models, such as Still-2 and Journey.Meanwhile, the NovaSky team at the University of California, Berkeley, has been exploring a variety of techniques to develop the inference capabilities of both base and command-tuned models.
In this work, Sky-T1-32B-Preview, the team achieved competitive inference performance not only on the mathematical side, but also on the coding side of the same model.

To ensure that this work 'reaches the wider community', the team open-sourced all the details (e.g. data, code, model weights) so that the community could easily replicate and improve upon it:
- Infrastructure: building data, training and evaluating models in a single repository;
- Data: 17K data used to train Sky-T1-32B-Preview;
- Technical details: technical reports and wandb logs;
- Model weights: 32B Model weights.
Technical details
Data collation process
To generate the training data, the team used QwQ-32B-Preview, an open-source model with inference capabilities comparable to o1-preview. The team organized the data mixture to cover the different domains where inference was needed and used a rejection sampling procedure to improve the quality of the data.
Then, inspired by Still-2, the team rewrote the QwQ trace into a structured version using GPT-4o-mini to improve data quality and simplify parsing.
They found that the simplicity of parsing is particularly beneficial to inference models. They are trained to respond in a specific format, and the results are often difficult to parse. For example, on the APPs dataset, without reformatting, the team could only assume that the code was written in the last code block, and QwQ could only achieve an accuracy of about 25%. However, sometimes the code may be written in the middle, and after reformatting, the accuracy increases to over 90%.
Reject Sample. Depending on the solution provided with the dataset, the team discards the QwQ sample if it is incorrect. For math problems, the team performs an exact match with the ground truth solution. For coding problems, the team performs the unit tests provided in the dataset. The team's final data consists of 5k of coded data from APPs and TACO, and 10k of math data from the Olympiads subset of the AIME, MATH, and NuminaMATH datasets. In addition, the team retained 1k of science and puzzle data from STILL-2.
train
The team used the training data to fine-tune Qwen2.5-32B-Instruct, an open-source model without inference capabilities. The model was trained using 3 epochs, a learning rate of 1e-5, and a batch size of 96. Model training was completed in 19 hours on 8 H100s using a DeepSpeed Zero-3 offload (priced at about $450 according to Lambda Cloud). The team used Llama-Factory for training.
Assessment results
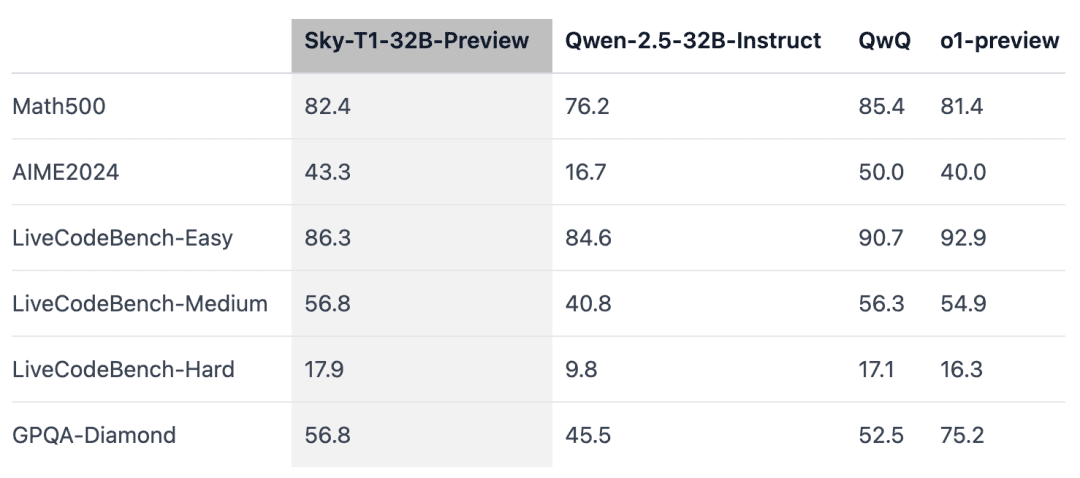
Sky-T1 outperformed an earlier preview version of o1 on MATH500, a 'competition-level' math challenge, and also beat a preview version of o1 on a set of puzzles from LiveCodeBench, a coding assessment. However, Sky-T1 is not as good as the preview version of o1 on GPQA-Diamond, which contains physics, biology, and chemistry-related problems that PhD graduates should know.
However, OpenAI's o1 GA release is more powerful than the preview version of o1, and OpenAI expects to release a better performing inference model, o3, in the coming weeks.
New findings that deserve attention
Model size matters.The team initially tried training on smaller models (7B and 14B), but observed little improvement. For example, training Qwen2.5-14B-Coder-Instruct on the APPs dataset showed a slight improvement in performance on LiveCodeBench, from 42.6% to 46.3%.However, when manually examining the output of the smaller models (those smaller than 32B), the team found that they often generated duplicate content, which limiting their effectiveness.
Data blending is important.The team initially trained the 32B model using 3-4K math problems from the Numina dataset (provided by STILL-2), and the accuracy of AIME24 increased significantly from 16.7% to 43.3%. however, when programming data generated from the APPs dataset was incorporated into the training process, the accuracy of AIME24 dropped to 36.7%. It may imply that this drop is due to the different inference methods required for math and programming tasks.
Programming reasoning usually involves additional logical steps, such as simulating test inputs or internally executing generated code, whereas reasoning for mathematical problems tends to be more straightforward and structured.To address these differences, the team enriched the training data with challenging math problems from the NuminaMath dataset and complex programming tasks from the TACO dataset. This balanced mix of data allowed the model to excel in both domains, recovering an accuracy of 43.3% on AIME24 while also improving its programming capabilities.
At the same time, some researchers have expressed skepticism:


What do people think about this? Feel free to discuss it in the comments section.
Reference link: https://www.reddit.com/r/LocalLLaMA/comments/1hys13h/new_model_from_httpsnovaskyaigithubio/
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...