
DeepSeek Hands-on: Wissensgraphenkonstruktion in drei Schritten - Einzelextraktion, Mehrteilige Fusion, Themengenerierung

Frage: Wissensgraphen sind wichtig, das DeepSeek-Sprachmodell ist in aller Munde. Kann es verwendet werden, um Wissensgraphen schnell zu erstellen? Ich möchte es ausprobieren. DeepSeek um zu sehen, wie gut es Informationen extrahieren, Wissen integrieren und Diagramme aus dem Nichts erstellen kann.
Methoden: Ich habe drei Experimente durchgeführt, um die Fähigkeiten von DeepSeek zur Erstellung von Wissensgraphen zu testen:
- Einzelne Artikel bauen Mapping: Geben Sie DeepSeek einen Artikel und sehen Sie, ob es die Informationen genau erfassen und ein Diagramm erstellen kann.
- Kartierung mehrerer Artikel durch Fusion: Geben Sie DeepSeek mehrere Artikel, um zu sehen, ob es neues Wissen zu einem bestehenden Graphen hinzufügen kann.
- Mapping der Themengenerierung: Sagen Sie DeepSeek einfach das Thema des Atlasses, nicht den Artikel, und sehen Sie, ob es von selbst einen Atlas erstellen kann.
Ergebnisse: Experimente zeigen, dass DeepSeek Wissensgraphen gut aufbaut und zusammenführt, aber es gibt noch Raum für Verbesserungen.
Hier sind der genaue Ablauf und die Ergebnisse des Experiments, die ich in einfacheren Worten erläutern werde.
I. Extraktion von Wissen aus einem einzelnen Artikel zur Erstellung einer Karte
Zweck: Prüfung der Fähigkeit von DeepSeek, Wissen aus einem Artikel zu extrahieren und einen Wissensgraphen zu erstellen.
Prozess: Ich fand einen Artikel über NebulaGraph-Graph-Datenbanken und ließ DeepSeek den Artikel lesen, die wichtigsten Informationen extrahieren und dann NebulaGraph-Datenbankcode (nGQL) generieren, um einen Wissensgraphen zu erstellen.
Anweisungen: "Können Sie mir helfen, einen Wissensgraphen zu erstellen? Ich gebe Ihnen den Artikel, Sie extrahieren die wichtigsten Informationen und erstellen den Wissensgraphen mit nGQL-Code."
Betrieb: Kopieren Sie den Inhalt des Artikels und fügen Sie ihn direkt in DeepSeek ein.
DeepSeek erzeugt nGQL-Code:
# Schema 定义(TAG 类型)
CREATE TAG IF NOT EXISTS product (
name STRING,
description STRING
);
CREATE TAG IF NOT EXISTS company (
name STRING
);
CREATE TAG IF NOT EXISTS feature (
name STRING
);
CREATE TAG IF NOT EXISTS tool (
name STRING
);
CREATE TAG IF NOT EXISTS scenario (
name STRING
);
CREATE TAG IF NOT EXISTS language (
name STRING
);
CREATE TAG IF NOT EXISTS auth_service (
name STRING
);
CREATE TAG IF NOT EXISTS ecosystem (
name STRING
);
# Schema 定义(EDGE 类型)
CREATE EDGE IF NOT EXISTS has_feature ();
CREATE EDGE IF NOT EXISTS used_by ();
CREATE EDGE IF NOT EXISTS provides_tool ();
CREATE EDGE IF NOT EXISTS supports_language ();
CREATE EDGE IF NOT EXISTS applicable_scenario ();
CREATE EDGE IF NOT EXISTS compatible_with ();
CREATE EDGE IF NOT EXISTS supports_auth ();
CREATE EDGE IF NOT EXISTS integrates_with ();
# 数据插入 - 核心产品
INSERT VERTEX product(name, description) VALUES
"NebulaGraph": ("NebulaGraph", "开源的分布式图数据库,支持千亿点万亿边数据集");
# 数据插入 - 产品特性
INSERT VERTEX feature(name) VALUES
"high_performance": ("高性能"),
"open_source": ("开源"),
"scalability": ("易扩展"),
"flexible_modeling": ("灵活数据建模"),
"read_write_balance": ("读写平衡"),
"compatibility": ("查询语言兼容性");
/* ... 此处省略 n多数据 ... */
Ergebnisse: Der DeepSeek-Code ist in Ordnung, die Syntax ist korrekt, und er ist effizient, da er mehrere Daten in einer einzigen Anweisung kombiniert. Der Code wird zur Ausführung in NebulaGraph eingefügt, und der Graph sieht wie folgt aus:
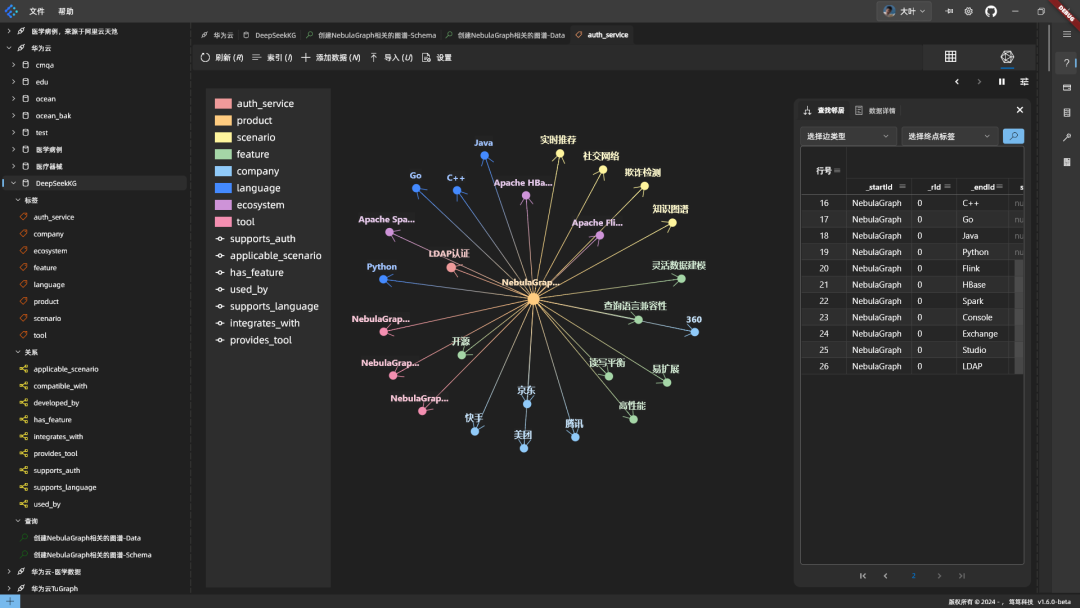
Die Grafik ist auf den NebulaGraph zentriert und zeigt die relevanten Informationen an.
II. die Integration von Wissen über mehrere Artikel hinweg
Zweck: Test der Fähigkeit von DeepSeek, Wissen aus mehreren Artikeln zu fusionieren, um einen bestehenden Graphen zu erweitern.
Prozess: Zunächst wird der Graph mit einem Artikel erstellt, dann gibt DeepSeek weitere Artikel über NebulaGraph (aus der Baidu-Enzyklopädie) ein, um das neue Wissen in den bestehenden Graphen einzufügen.
Anweisungen: "Als nächstes ein weiterer Artikel für Sie. Versuchen Sie, das Mapping mit der aktuellen Tabellenstruktur zu vereinen. Um die Tabellenstruktur zu ändern, verwenden Sie den ALTER-Befehl."
Betrieb: Zusammenfassungen von NebulaGraph und 360 Enzyklopädieeinträgen wurden an DeepSeek weitergegeben.
Der von DeepSeek generierte nGQL-Code (NebulaGraph-Lexikon):
# 结构变更 1:为 product 标签增加版本和时间属性
ALTER TAG product ADD (
license STRING,
current_version STRING,
release_date STRING,
last_updated STRING
);
# 结构变更 2:新增开发关系类型
CREATE EDGE IF NOT EXISTS developed_by();
# 数据更新 - 补充产品属性
INSERT VERTEX product(name, description, license, current_version, release_date, last_updated)
VALUES
"NebulaGraph": ("NebulaGraph", "分布式图数据库", "Apache 2.0", "v3.3.0", "2019-05-15", "2022-11-14");
# 新增开发公司(复用 company 标签)
INSERT VERTEX company(name)
VALUES
"Yueshu": ("杭州悦数科技有限公司");
# 新增特性(复用 feature 标签)
INSERT VERTEX feature(name)
VALUES
"acl_mechanism": ("ACL 机制"),
"linear_scaling": ("线性扩容"),
"data_recovery": ("数据恢复"),
"htap": ("HTAP 混合负载"),
"nGQL_language": ("nGQL 查询语言");
# 关系建立(复用已有关系类型)
INSERT EDGE has_feature()
VALUES
"NebulaGraph"->"acl_mechanism":(),
"NebulaGraph"->"linear_scaling":(),
"NebulaGraph"->"data_recovery":(),
"NebulaGraph"->"htap":(),
"NebulaGraph"->"nGQL_language":();
# 新增开发关系
INSERT EDGE developed_by()
VALUES
"NebulaGraph"->"Yueshu":();
Von DeepSeek generierter nGQL-Code (360 Wörter):
# 结构变更 1:为 company 标签增加创始人、成立时间和收入属性
ALTER TAG company ADD (founder STRING, founded_date STRING, revenue DOUBLE);
# 结构变更 2:新增事件类型 TAG
CREATE TAG IF NOT EXISTS event (
type STRING,
date STRING,
amount DOUBLE,
details STRING
);
# 数据更新:补充 360 公司信息
INSERT VERTEX company(name, founder, founded_date, revenue)
VALUES
"360": ("奇虎360", "周鸿祎", "2005-09", 116.15);
# 数据插入:产品生态(复用 product 标签)
INSERT VERTEX product(name)
VALUES
"360_Security_Guard": ("360安全卫士"),
"360_Browser": ("360安全浏览器"),
"360_Cloud": ("360安全云");
# 数据插入:重大事件(使用新增 event 标签)
INSERT VERTEX event(type, date, amount, details)
VALUES
"acquisition_360.com": ("域名收购", "2015-02-04", 1700.0, "1.1亿人民币收购 360.com"),
"privatization": ("私有化", "2015-12", 9300.0, "93 亿美元私有化交易");
# 关系建立:复用 developed_by 边连接产品
Ergebnisse: DeepSeek kann die Tabellenstruktur auf der Grundlage des neuen Artikels ändern (z. B. indem es Produkt im Gesang antworten Unternehmen Tabelle plus Felder) und fügte auch einen neuen Beziehungstyp hinzu. Dies geschieht wie erforderlich mit dem ALTER um die Tabellenstruktur zu ändern. Das kleine Problem ist, dass der Kommentar die --nGQL nicht erkannt wird, ändern Sie es manuell. # Auf der Linie.
Der Code wird zur Ausführung in die Datenbank eingegeben, und das Fused Mapping funktioniert:
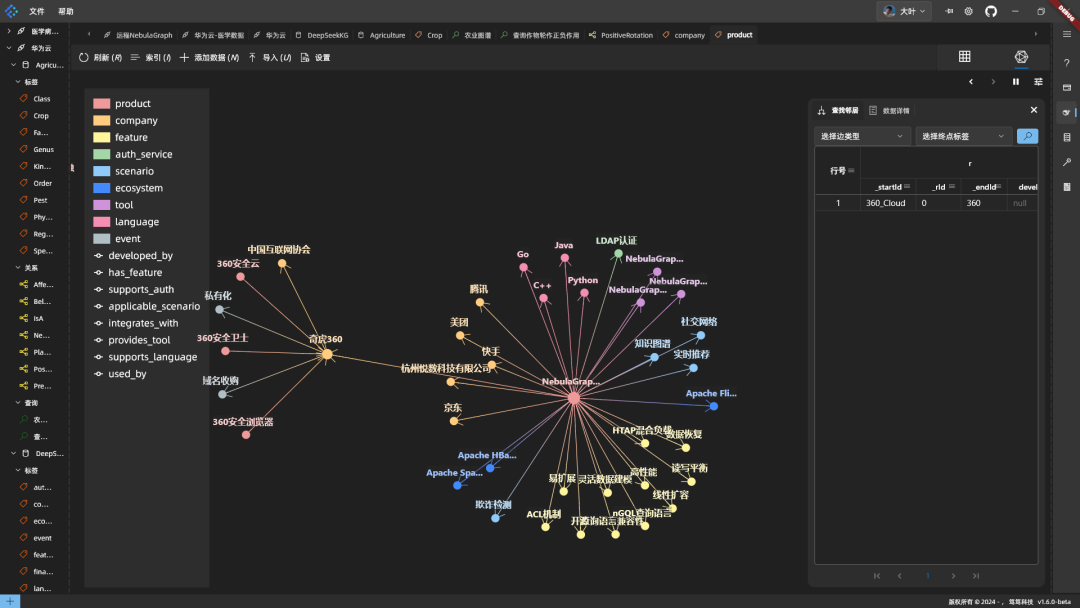
Zusammenfassung: DeepSeek ist gut geeignet, um Graphen zu erstellen und Wissen zu fusionieren. Allerdings ist der Server manchmal langsam, und NebulaGraph ändert das Schema asynchron und braucht eine Weile, um wirksam zu werden.
III. Themengenerierung: Agrarkartierung aus dem Nichts
Zweck: Testen Sie die Fähigkeit von DeepSeek, einen Wissensgraphen auf der Grundlage von Themen ohne Artikel zu erstellen.
Prozess: Erstellen Sie einen neuen Dialog und lassen Sie DeepSeek den Mapping-Code direkt zum Thema "Landwirtschaft" generieren. Es wird kein Artikel vorgegeben, es ist ein "free-for-all".
Anweisungen: "Ich möchte einen landwirtschaftlichen Wissensgraphen erstellen. Verwenden Sie die NebulaGraph-Datenbank und erzeugen Sie ein nGQL-Skript. Tabellennamen sind große Buckel, Attributnamen sind kleine Buckel. Schemanamen sind mit `` umschlossen, um Konflikte zu vermeiden. Erzeugen Sie mindestens 3000 Knoten."
Von DeepSeek erzeugter nGQL-Code (teilweise):
# ======================================= #
# 创建图空间
# ======================================= #
CREATE SPACE `Agriculture` (vid_type = FIXED_STRING(32));
USE `Agriculture`;
# ======================================= #
# 定义标签 Schema(大驼峰命名)
# ======================================= #
CREATE TAG IF NOT EXISTS `Crop` (
`cropId` int,
`cropName` string,
`growthPeriod` int,
`suitableTemp` string,
`yieldPerMu` float
);
# ======================================= #
# 此处省略好多脚本
# ======================================= #
Probleme und Verbesserungen:
- Begrenzung der Knotenanzahl: Ich begann mit 3000 Knoten, DeepSeek verweigerte den Import des CSV-Codes und gab Python vor. Ich wollte Python nicht verwenden, also habe ich die Anzahl der Knoten reduziert.
- Die Frage der Kommentierung stellt sich erneut: Die Code-Kommentare sind wieder --Es wurde erneut auf die Frage hingewiesen.
Verbesserungshinweise: "Verwenden Sie # für Kommentare, keinen Python-Code, 3000 Knoten sind zu viel. Geben Sie mir einfach das ngql-Skript für 50 Knoten."
Nachfassender Dialog und Anweisungen: Um die Karte zu verfeinern, sprach ich weiter mit DeepSeek und bat es, Daten hinzuzufügen, die Assoziationen zu verstärken, die Karte nach Klassifizierung (Stamm, Ordnung, Familie, Gattung und Art) zu organisieren und auch Daten zur Fruchtfolge zu generieren.
Zum Beispiel meine Anweisungen:
- "Ergänzende Daten für stärkere Datenverknüpfungen".
- "Erstellen Sie einen Atlas mit diesen Klassifizierungen [von Phylonen, Ordnungen, Familien, Gattungen und Arten].
- "Identifizieren Sie Kontraindikationen und bauen Sie Kulturen in die Fruchtfolge ein.
- "Kombinieren von kartierten Kulturgewebedaten zu nGQL-Skripten im bisherigen Format"
Experimentelles Intermezzo: DeepSeek, einmal. INSERT Anweisung verwendet die Cypher-Syntax, die von nGQL nicht unterstützt wird, und wurde darauf hingewiesen und geändert.
Anweisungen: "Diese Einfügeanweisung entspricht nicht der nGQL-Syntax. Ändern Sie sie so, dass DDL an erster Stelle steht und DML an zweiter Stelle."
Endgültige Datenmenge: Nach einigen Dialogrunden wird die Menge der Daten angezeigt:

Mapping-Effekte: Erweitern Sie ein paar zufällige Knoten, um zu sehen:
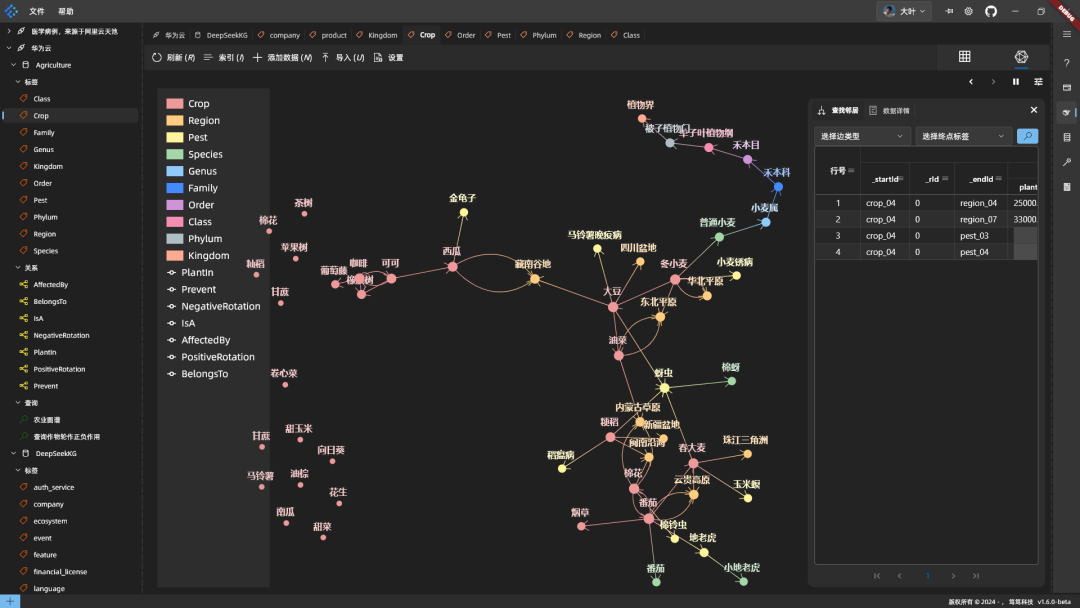
Beispiele für ertragssteigernde Kombinationen von Rotationsarten: Ertragssteigernde kombinatorische Effekte der Adventivbepflanzung:
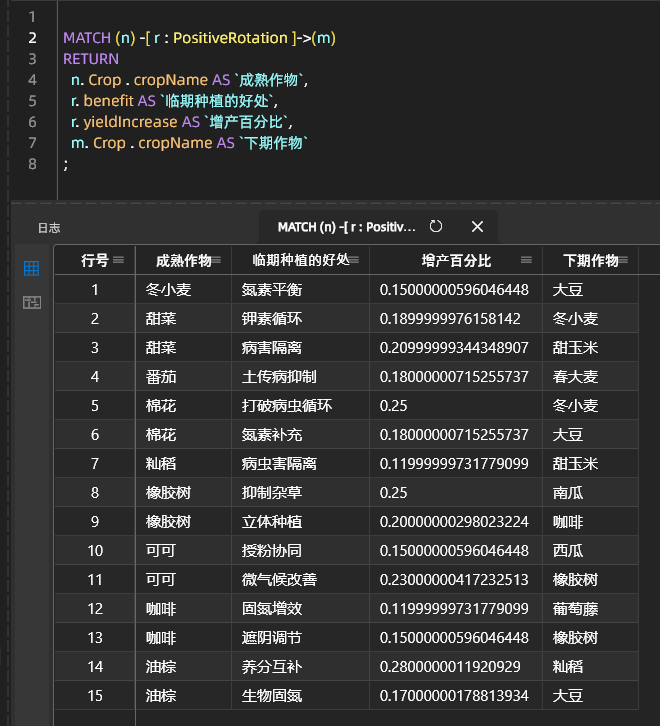
IV. Zusammenfassung
Schlussfolgerung: DeepSeek zeichnet sich durch die Konstruktion und Fusion von Wissensgraphen aus, und Experimente belegen seine Fähigkeiten:
- Die Extraktion von Informationen erfolgt schnell und präzise: DeepSeek extrahiert schnell Schlüsselinformationen aus Texten, generiert konforme nGQL-Skripte und verfügt über ein ausgeprägtes Sprachverständnis, um Entitäten, Beziehungen und Ereignisse zu erkennen.
- Ausgeprägte Fähigkeit, Wissen zu integrieren: DeepSeek führt Wissen aus mehreren Artikeln zusammen, erweitert und aktualisiert den Graphen auf der Grundlage neuer Artikel und gewährleistet die Vollständigkeit und Genauigkeit des Graphen.
- Sie können eine Karte aus dem Nichts erstellen: Keine Artikel können Diagramme nach Thema erstellen. Es gibt einige Syntaxprobleme bei der Generierung, aber die Anpassungen ergeben brauchbare Skripte.
- Die Details müssen optimiert werden: Von DeepSeek generierte Skripte weisen gelegentlich Syntaxprobleme auf, wie z. B. falsche Kommentare. Bei der Generierung einer großen Anzahl von Knoten kann es vorkommen, dass der Server nur langsam reagiert. Achten Sie auf diese Probleme, wenn Sie das Programm tatsächlich verwenden.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...