
Das Wort "Agent" ist deprimierend, die GPT-4-Modelle sind nicht mehr erwähnenswert, und die großen Programmierer ziehen Bilanz über "Das große Modell 2024".

Experten sind sich einig: 2024 ist das Jahr der AGI. Dies ist das Jahr, in dem sich die große Modellierungsbranche für immer verändert:
Das GPT-4 von OpenAI ist nicht mehr unerreichbar; die Arbeit an Bild- und Videogenerierungsmodellen wird immer realistischer; es wurden Durchbrüche bei multimodalen großen Sprachmodellen, Inferenzmodellen und Intelligenzen (Agenten) erzielt; und die Menschen interessieren sich immer mehr für KI ......
Wie hat sich die große Modelbranche aus Sicht eines erfahrenen Brancheninsiders im Laufe des Jahres verändert?
Vor ein paar Tagen hat der renommierte unabhängige Programmierer, Mitbegründer des sozialen Konferenzverzeichnisses Lanyrd und Miterfinder des Web-Frameworks Django Simon Willison in dem Bericht mit dem Titel Was wir über LLMs im Jahr 2024 gelernt haben Der Artikel gibt einen detaillierten Überblick über die Veränderungen, Überraschungen und Unzulänglichkeiten in der Großmodellbranche im Jahr 2024.

Einige der Punkte sind im Folgenden aufgeführt:
- Im Jahr 2023 ist die Ausbildung eines Modells mit GPT-4-Einstufung eine große Sache. Im Jahr 2024 ist dies jedoch nicht einmal eine besonders bemerkenswerte Leistung.
- Im Laufe des letzten Jahres haben wir unglaubliche Leistungssteigerungen in den Bereichen Training und Schlussfolgerungen erzielt.
- Es gibt zwei Faktoren, die die Preise senken: verstärkter Wettbewerb und Effizienzsteigerungen.
- Diejenigen, die sich über den langsamen Fortschritt des LLM beklagen, neigen dazu, die großen Fortschritte bei der multimodalen Modellierung zu ignorieren.
- Die prompte Erstellung von Apps ist zu einer Massenware geworden.
- Vorbei sind die Zeiten des freien Zugangs zu SOTA-Modellen.
- Intelligenzia, noch nicht wirklich geboren.
- Das Schreiben guter automatischer Auswertungen für LLM-gesteuerte Systeme ist die am meisten benötigte Fähigkeit, um nützliche Anwendungen auf der Grundlage dieser Modelle zu entwickeln.
- o1 Führende neue Ansätze für erweiterte Modelle: Lösung schwierigerer Probleme durch mehr Rechenaufwand für die Inferenz.
- Die US-Vorschriften für chinesische GPU-Exporte haben offenbar zu einigen sehr wirksamen Optimierungen der Ausbildung geführt.
- In den letzten Jahren konnten der Energieverbrauch und die Umweltauswirkungen des Betriebes von Prompt deutlich reduziert werden.
- Unerwünschte und unzensierte Inhalte, die von künstlicher Intelligenz generiert werden, sind "Dreck".
- Der Schlüssel zur optimalen Nutzung des LLM liegt darin, zu lernen, wie man unzuverlässige, aber leistungsfähige Techniken einsetzt.
- Der LLM hat einen echten Wert, aber diesen Wert zu erkennen, ist nicht intuitiv und erfordert Anleitung.
Ohne den allgemeinen Tenor des ursprünglichen Textes zu verändern, wurde der Gesamtinhalt wie folgt gekürzt:
Im Jahr 2024 tut sich viel auf dem Gebiet der Large Language Modelling (LLM). Hier ein Rückblick auf das, was wir in den letzten 12 Monaten in diesem Bereich entdeckt haben, zusammen mit meinen Versuchen, Schlüsselthemen und Schlüsselmomente zu identifizieren. Einschließlich 19 Aspekte:
1. der Graben des GPT-4 wurde "durchbrochen".
In meiner Rezension vom Dezember 2023 schrieb ich: "Wir wissen noch nicht, wie wir GPT-4 bauen können.-- Zu diesem Zeitpunkt war GPT-4 bereits seit fast einem Jahr auf dem Markt, aber andere KI-Labors hatten noch kein besseres Modell entwickelt.Was weiß OpenAI, was wir nicht wissen?
Zu meiner Erleichterung hat sich dies in den letzten 12 Monaten komplett geändert. Das Chatbot Arena Leaderboard hat jetztModelle von 18 OrganisationenDiese Zahl ist höher als die ursprüngliche Version von GPT-4 (GPT-4-0314), die im März 2023 veröffentlicht wurde und erreicht 70
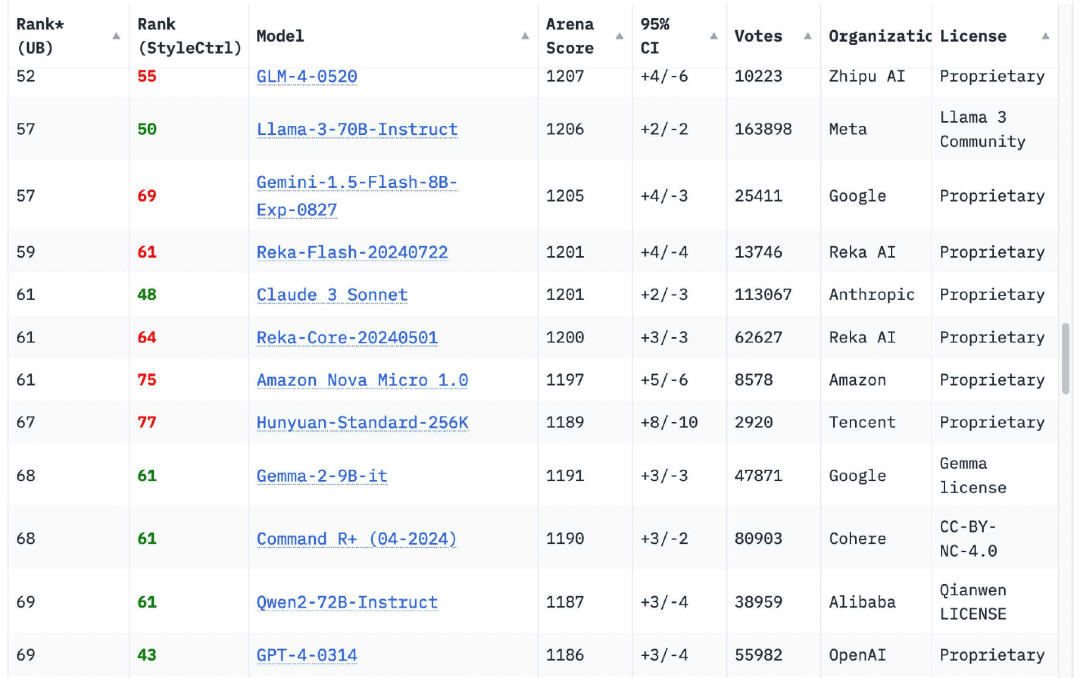
Der früheste Herausforderer war Googles im Februar 2024 veröffentlichte Zwillinge 1.5 Pro bietet nicht nur eine Ausgabe auf GPT-4-Niveau, sondern auch eine Reihe neuer Funktionen, darunter dieAm bemerkenswertesten ist die Länge des Eingabekontexts von 1 Million (später 2 Millionen) Token und die Möglichkeit, Videos einzugeben.
Gemini 1.5 Pro stößt eines der wichtigsten Themen von 2024 an: die Erhöhung der Kontextlänge.Im Jahr 2023 werden die meisten Modelle nur noch 4096 oder 8192 Token akzeptieren können.Libysch-Arabische Dschamahirija Claude Die Ausnahme ist 2.1, die 200.000 Token akzeptiert; heute hat jeder Modellanbieter ein Modell, das mehr als 100.000 Token akzeptiert. Token Modell kann die Gemini-Serie von Google bis zu 2 Millionen Token annehmen.
Längere Eingaben erweitern das Spektrum der Probleme, die mit LLM gelöst werden können, erheblich: Sie können jetzt ein ganzes Buch eingeben und Fragen zu seinem Inhalt stellen, aber noch wichtiger ist, dass Sie eine große Menge an Beispielcode eingeben können, um dem Modell zu helfen, das Codierungsproblem richtig zu lösen. Für mich sind LLM-Anwendungsfälle mit langen Eingaben viel interessanter als kurze Aufforderungen, die sich nur auf Informationen über Modellgewichte stützen. Viele meiner Werkzeuge sind auf diesem Modell aufgebaut.
Kommen wir zu den Modellen, die das GPT-4 "geschlagen" haben: Die Claude 3-Serie von Anthropic wurde im März auf den Markt gebracht, und das Claude 3 Opus wurde schnell zu meinem Lieblingsmodell. Im Juni folgte das Claude 3.5 Sonnet - und sechs Monate später ist es immer noch mein Lieblingsmodell! Sechs Monate später ist er immer noch mein Favorit.
Natürlich gibt es auch andere. Wenn Sie sich heute das Chatbot Arena Leaderboard ansehen, werden Sie feststellen, dass dieGPT-4-0314 ist auf etwa Platz 70 gefallen.. Die 18 Organisationen mit hohen Modellwerten sind Google, OpenAI, Alibaba, Anthropic, Meta, Reka AI, Zero One Thing, Amazon, Cohere, DeepSeek, NVIDIA, Mistral, NexusFlow, Smart Spectrum, xAI, AI21 Labs, Princeton University und Tencent.
Die Ausbildung eines Modells der Stufe GPT-4 im Jahr 2023 ist eine große Sache. Allerdings ist dieIm Jahr 2024 ist das nicht einmal eine besonders bemerkenswerte Leistung.aber ich persönlich freue mich immer noch, wenn eine neue Organisation in die Liste aufgenommen wird.
2. ein Laptop, der für die Ausführung von Modellen der Stufe GPT-4 geeignet ist
Mein persönliches Notebook ist ein MacBook Pro 2023 mit 64 GB. Es ist ein leistungsstarkes Gerät, aber es ist auch fast zwei Jahre alt - und, was noch wichtiger ist, es ist dasselbe Notebook, das ich seit März 2023 benutze, als ich LLM zum ersten Mal auf meinem eigenen Computer ausgeführt habe.
Im März 2023 wird dieser Laptop immer noch nur ein Modell der Stufe GPT-3 ausführen könnenDas GPT-4-Modell kann nun mehrere Modelle der Stufe GPT-4 ausführen!
Das überrascht mich immer noch. Ich dachte, man bräuchte einen oder mehrere Server in Rechenzentrumsqualität mit GPUs im Wert von über 40.000 Dollar, um die Funktionalität und Ausgabequalität des GPT-4 zu erreichen.
Die Modelle belegen 64 GB meines Arbeitsspeichers, also lasse ich sie nicht sehr oft laufen - sie lassen nicht viel Platz für andere Dinge.
Die Tatsache, dass sie funktionieren, ist ein Beweis für die unglaublichen Leistungssteigerungen beim Training und bei der Inferenz, die wir im letzten Jahr erzielt haben. Wie sich herausstellt, haben wir eine Menge sichtbarer Früchte in Bezug auf die Modelleffizienz geerntet. Ich hoffe, dass es in Zukunft noch mehr sein werden.
Die Modelle der Llama 3.2-Serie von Meta verdienen eine besondere Erwähnung. Sie sind zwar nicht als GPT-4 eingestuft, aber in den Größen 1B und 3B zeigen sie Ergebnisse, die die Erwartungen übertreffen.
3. die Preise für LLM sind aufgrund von Wettbewerb und Effizienzsteigerungen erheblich gesunken
In den letzten zwölf Monaten sind die Kosten für die Nutzung des LLM-Programms drastisch gesunken.
Dezember 2023, OpenAI erhebt $30/Millionen Input-Token für GPT-4(mTok) KostenDarüber hinaus wurde für die damals neu eingeführte GPT-4 Turbo eine Gebühr von 10 US$/mTok und für die GPT-3.5 Turbo eine Gebühr von 1 US$/mTok erhoben.
Heute ist das teuerste o1-Modell von OpenAI für $30/mTok erhältlich!Der GPT-4o kostet 2,50 $ (12-mal billiger als der GPT-4), und der GPT-4o mini kostet 0,15 $/mTok - fast siebenmal billiger als der GPT-3,5 und leistungsfähiger.
Andere Modellanbieter verlangen sogar noch weniger: Das Claude 3 Haiku von Anthropic liegt bei 0,25 $/mTok, das Gemini 1.5 Flash von Google bei 0,075 $/mTok und das Gemini 1.5 Flash 8B bei 0,0375 $/mTok, also 27 Mal günstiger als das GPT-3.5 Turbo im Jahr 2023. Turbo im Jahr 2023.
Es gibt zwei Faktoren, die die Preise senken: verstärkter Wettbewerb und Effizienzsteigerungen. Effizienzverbesserungen sind für alle wichtig, die sich über die Umweltauswirkungen des LLM Gedanken machen. Diese Preissenkungen stehen in direktem Zusammenhang mit der Energie, die für den Betrieb der Eingabeaufforderung verbraucht wird.
Über die Umweltauswirkungen des Baus von KI-Rechenzentren muss man sich noch viele Gedanken machen, aber die Bedenken hinsichtlich der Energiekosten einzelner Abfragen sind nicht mehr glaubwürdig.
Machen wir eine interessante Berechnung: Wie viel würde es kosten, mit Googles billigstem Gemini 1.5 Flash 8B kurze Beschreibungen für jedes der 68.000 Fotos in meiner persönlichen Fotobibliothek zu erstellen?
Für jedes Foto werden 260 Eingabemarken und etwa 100 Ausgabemarken benötigt.
260 * 68000 = 17680000 Token eingeben
17680000 * 0,0375 $/Million = 0,66 $
100 * 68000 = 6800.000 Ausgabe-Token
6800000 * 0,15 $/Million = 1,02 $
Die Gesamtkosten für die Verarbeitung von 68.000 Bildern betragen $1,68. Es war so billig, dass ich sogar dreimal nachgerechnet habe, um sicherzugehen, dass ich es richtig hatte.
Wie gut sind diese Beschreibungen? Ich habe die Informationen von diesem Befehl erhalten:
llm -m gemini-1.5-flash-8b-latest beschreiben -a IMG_1825.jpeg
Dies ist ein Foto eines Schmetterlings von der California Academy of Sciences:

Auf dem Bild ist eine rote flache Schale zu sehen, die ein Kolibri oder Schmetterlingsfutter sein könnte. Auf dem Teller liegen orangefarbene Fruchtscheiben.
Es gibt zwei Schmetterlinge in der Futterstelle, einer ist ein dunkelbrauner/schwarzer Schmetterling mit weißer/cremefarbener Zeichnung. Der andere war ein größerer brauner Schmetterling mit hellbrauner, beiger und schwarzer Zeichnung, einschließlich auffälliger Augenflecken. Dieser größere braune Schmetterling scheint Früchte von einem Teller zu fressen.
260 Eingabemarken, 92 Ausgabemarken, zu Kosten von etwa 0,0024 Cent (weniger als 400stel eines Cents).
Höhere Effizienz und niedrigere Preise sind meine Lieblingstrends für 2024.Ich möchte den Nutzen von LLM zu einem Bruchteil der Energiekosten, und genau das erreichen wir.
4. multimodales Sehen hat sich durchgesetzt, Audio und Video beginnen sich zu entwickeln
Mein obiges Schmetterlingsbeispiel veranschaulicht auch einen anderen wichtigen Trend für 2024: den Aufstieg des Multimodal Large Language Model (MLLM).
Die GPT-4 Vision, die vor einem Jahr auf dem DevDay von OpenAI im November 2023 veröffentlicht wurde, ist das bemerkenswerteste Beispiel dafür. Google hingegen veröffentlichte am 7. Dezember 2023 das multimodale Gemini 1.0.
Im Jahr 2024 haben fast alle Modellanbieter multimodale Modelle veröffentlicht.Wir haben es im März gesehen. Anthropisch s Claude 3-Serie, im April die Gemini 1.5 Pro (Bild, Audio und Video) und im September die Mistral Pixtral 12B von Meta und die visuellen Modelle Llama 3.2 11B und 90B von Meta. Im Oktober erhielten wir Audioeingaben und -ausgaben von OpenAI, im November SmolVLM von Hugging Face und im Dezember Bild- und Videomodelle von Amazon Nova.
Glaube ich.Diejenigen, die sich über den langsamen Fortschritt der LLM beschweren, ignorieren die großen Fortschritte bei diesen multimodalen Modellen. Die Möglichkeit, Prompts anhand von Bildern (sowie Audio- und Videomaterial) auszuführen, ist eine faszinierende neue Möglichkeit, diese Modelle anzuwenden.
5) Sprach- und Echtzeit-Videomodus, um Science-Fiction in die Realität zu bringen
Besonders erwähnenswert sind Audio- und Echtzeit-Videomodelle, die sich allmählich durchsetzen.
zusammen mit ChatGPT Die Dialogfunktion debütiert im September 2023, aber das ist weitgehend eine Illusion: OpenAI nutzt seine hervorragende Flüstern Sprache-zu-Text-Modell und ein neues Text-zu-Sprache-Modell (mit dem Namen tts-1), um den Dialog mit ChatGPT zu ermöglichen, aber das eigentliche Modell kann nur Text sehen.
OpenAIs GPT-4o, das am 13. Mai veröffentlicht wurde, enthält eine Demonstration eines neuen Sprachmodells, des wirklich multimodalen GPT-4o ("o" steht für "omni"), das Audioeingaben verarbeiten und unglaublich realistische Sprache ausgeben kann, ohne dass ein separates TTS- oder STT-Modell erforderlich ist. realistische Sprache ausgeben kann, ohne dass ein separates TTS- oder STT-Modell erforderlich ist.
Als ChatGPT Advanced Voice Mode schließlich eingeführt wurde, waren die Ergebnisse erstaunlich.Ich benutze diesen Modus oft, wenn ich mit meinem Hund spazieren gehe, und der Ton hat sich so sehr verbessert, dass es erstaunlich ist!. Ich hatte auch viel Spaß bei der Verwendung der OpenAI Audio API.
OpenAI ist nicht das einzige Team mit einem multimodalen Audiomodell. Googles Gemini akzeptiert ebenfalls Audioeingaben und kann auch auf eine ChatGPT-ähnliche Weise sprechen. Amazon kündigte ebenfalls ein Sprachmodell für Amazon Nova vorzeitig an, aber dieses Modell wird erst im ersten Quartal 2025 verfügbar sein.
Google NotebookLM Das im September veröffentlichte Programm brachte die Audioausgabe auf ein neues Niveau, mit zwei "Podcast-Moderatoren", die realistische Gespräche über alles führen konnten, was Sie eintippten, und fügte später eigene Befehle hinzu.
Die jüngste Neuerung, die ebenfalls im Dezember eingeführt wurde, ist das Live-Video.ChatGPT Voice Mode bietet jetzt die Möglichkeit, Kamerabilder mit Models zu teilen und in Echtzeit darüber zu sprechen, was man sieht. Googles Gemini hat ebenfalls eine Vorschauversion mit denselben Funktionen veröffentlicht.
6. die prompte Erstellung von Apps, die zu einem Massenprodukt geworden sind
GPT-4 kann dies bereits im Jahr 2023 erreichen, aber sein Wert wird erst 2024 deutlich.
LLM ist dafür bekannt, ein erstaunliches Talent für das Schreiben von Code zu haben. Wenn Sie einen Prompt richtig schreiben können, können sie Ihnen eine komplette interaktive Anwendung mit HTML, CSS und JavaScript erstellen - oft in einem einzigen Prompt.
Anthropic hat diese Idee mit der Veröffentlichung von Claude Artifacts auf die nächste Stufe gehobenArtifacts ist eine bahnbrechende neue Funktion. Mit Artifacts kann Claude bei Bedarf eine interaktive Anwendung für Sie schreiben, die Sie dann direkt in der Claude-Oberfläche verwenden können.
Dies ist eine Anwendung zum Extrahieren von URLs, die vollständig von Claude erstellt wurde:
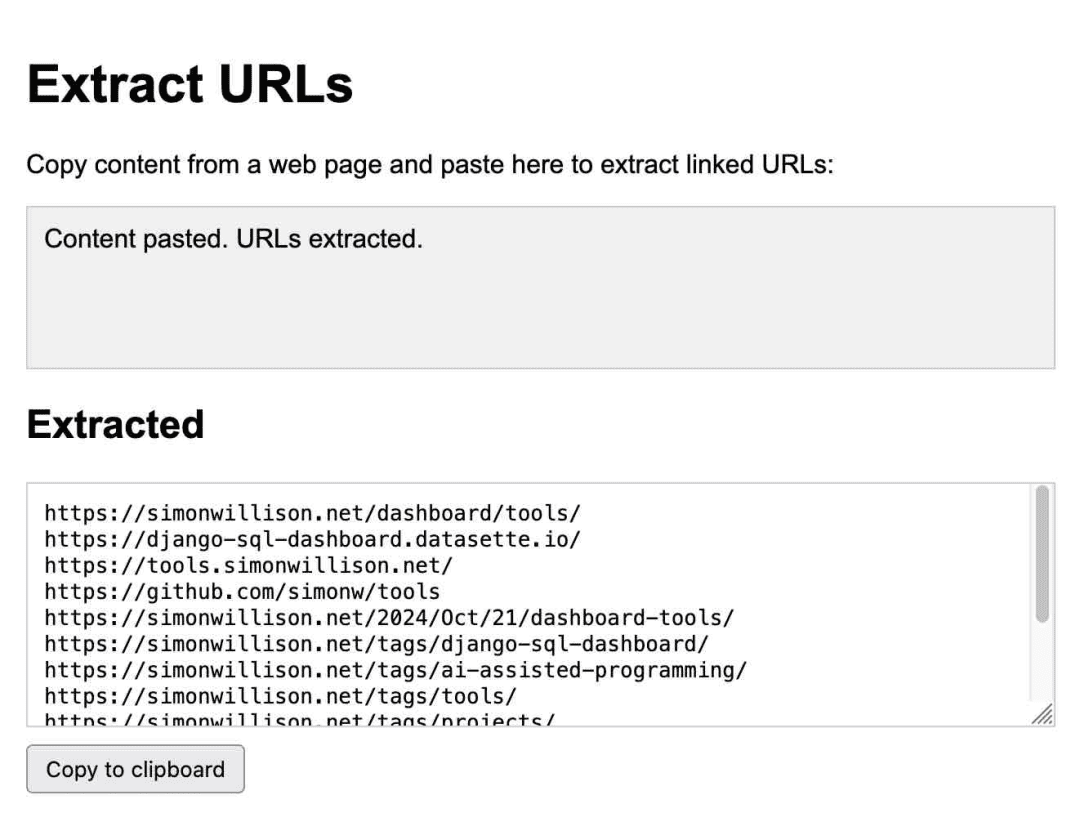
Ich benutze es regelmäßig. Im Oktober habe ich gemerkt, wie sehr ich mich darauf verlasse, dieIch habe mit Artifacts 14 Gadgets in sieben Tagen erstellt!.

Seitdem haben eine ganze Reihe anderer Teams ähnliche Systeme entwickelt, und im Oktober veröffentlichte GitHub seine Version, GitHub Spark, und im November fügte Mistral Chat es als eine Funktion namens Canvas hinzu.
Steve Krause aus Val Town antwortete auf Cerebras Eine Version wurde erstellt, um zu zeigen, wie LLM mit 2000 Token pro Sekunde die Anwendung iterieren und Änderungen in weniger als einer Sekunde erkennen kann.
Im Dezember hat das Chatbot Arena-Team dann ein brandneues Leaderboard für diese Funktion eingeführt, bei dem die Nutzer dieselbe interaktive App zweimal mit zwei verschiedenen Modellen erstellen und über die Antworten abstimmen. Es gibt wohl kaum ein überzeugenderes Argument dafür, dass diese Funktion jetzt ein Produkt ist, das mit allen führenden Modellen konkurrieren kann.
Ich habe über diese Version für mein Datasette-Projekt nachgedacht, mit dem Ziel, Benutzern die Möglichkeit zu geben, mit Prompt benutzerdefinierte Gadgets zu erstellen und zu iterieren und Daten auf der Grundlage ihrer eigenen Daten zu visualisieren. Ich habe auch ein ähnliches Muster für das Schreiben von einmaligen Python-Programmen über uv gefunden.
Diese Art von promptsgesteuerter benutzerdefinierter Schnittstelle ist so leistungsfähig und einfach zu erstellen (sobald man die Feinheiten der Browser-Sandbox herausgefunden hat), dass ich davon ausgehe, dass sie bis 2025 als Funktion in einer Vielzahl von Produkten auftauchen wird.
7 In nur wenigen Monaten wurden leistungsstarke Modelle populär gemacht
In nur wenigen Monaten, im Jahr 2024, werden leistungsstarke Modelle in den meisten Ländern der Welt kostenlos erhältlich sein.
OpenAI hat GPT-4o im Mai für alle Nutzer kostenlos gemacht, während Claude 3.5 Sonnet mit seiner Veröffentlichung im Juni kostenlos wurde. Dies ist eine bedeutende Veränderung, denn im vergangenen Jahr konnten kostenlose Nutzer meist nur Modelle auf dem Niveau von GPT-3.5 verwenden, was in der Vergangenheit dazu geführt hätte, dass neue Nutzer keine Klarheit über die tatsächlichen Fähigkeiten des LLM hatten.
Mit der Einführung von ChatGPT Pro von OpenAI scheint diese Ära vorbei zu sein, wahrscheinlich für immer!Dieses Abonnement für 200 $/Monat ist die einzige Möglichkeit, Zugang zu seinem leistungsstärksten Modell, dem o1 Pro, zu erhalten. Der o1 Pro, das leistungsstärkste Modell des Unternehmens, kann nur im Rahmen eines Abonnements für 200 $/Monat genutzt werden.
Der Schlüssel hinter der o1-Serie (und den zukünftigen Modellen, die sie zweifellos inspirieren werden) ist es, mehr Rechenzeit aufzuwenden, um bessere Ergebnisse zu erzielen. Ich denke, die Zeiten des freien Zugangs zu SOTA-Modellen sind damit vorbei.
8. intelligente Körper, die noch nicht wirklich geboren sind
Meiner persönlichen Meinung nach.Das Wort "Agent" ist sehr frustrierend.. Es gibt keine einheitliche, klare und allgemein verständliche Bedeutung ...... Aber diejenigen, die den Begriff verwenden, scheinen dies nie zuzugeben.
Wenn Sie mir sagen, dass Sie einen "Agenten" bauen, dann teilen Sie mir nichts mit. Ohne Ihre Gedanken zu lesen, kann ich nicht wissen, welche der Dutzenden von möglichen Definitionen Sie meinen.
Es gibt zwei Haupttypen von Menschen, die ich seheFür die eine Gruppe ist ein Agent offensichtlich etwas, das in Ihrem Namen handelt - ein reisender Agent - und für die andere Gruppe ist ein Agent ein LLM mit Zugang zu Werkzeugen, die in einer Schleife als Teil eines Problems ausgeführt werden können. Der Begriff "Autonomie" wird ebenfalls häufig verwendet, aber auch hier gibt es keine klare Definition. (Vor ein paar Monaten habe ich sogar eine Sammlung von 211 Definitionen des Begriffs "Agent" getwittert und gemini-exp-1206 gebeten, sie zusammenzufassen).
Was auch immer der Begriff bedeutet.Agent, es gibt immer noch ein Gefühl des ewigen "Bald".. Abgesehen von der Terminologie.Ich bin immer noch skeptisch, was ihre Praxistauglichkeit angeht.Dies ist eine Herausforderung, die auf Leichtgläubigkeit beruht: LLMs werden alles glauben, was man ihnen erzählt. Jedes System, das versucht, in Ihrem Namen sinnvolle Entscheidungen zu treffen, stößt auf das gleiche Hindernis: Wie nützlich ist ein Reisebüro, ein digitaler Assistent oder sogar ein Recherchetool, wenn es nicht unterscheiden kann, was wahr und was falsch ist?
Erst vor wenigen Tagen wurde bei einer Google-Suche eine völlig falsche Beschreibung des nicht existierenden Films Encanto 2 gefunden.
Die rechtzeitige Injektion ist eine natürliche Folge dieser Leichtgläubigkeit. Ich sehe 2024 kaum Fortschritte bei der Lösung dieses Problems, über das wir seit September 2022 diskutieren
Prompte Injektionsangriffe sind eine natürliche Folge dieser "Leichtgläubigkeit". Ich sehe kaum Fortschritte in der Branche im Jahr 2024, um dieses Problem anzugehen, über das wir seit September 2022 diskutieren.
Ich beginne zu glauben, dass das beliebteste Agenten-Konzept auf AGI basieren wird.Modelle widerstandsfähig gegen "Leichtgläubigkeit" zu machen, ist in der Tat eine große Aufgabe!.
9. die Bewertung, sehr wichtig
Amanda Askell von Anthropic (für Claude's). Zeichen den größten Teil der Arbeit dahinter) gesagt hatte:
Hinter einem guten Systemprompt steckt ein langweiliges, aber wichtiges Geheimnis: die testgetriebene Entwicklung. Man schreibt keinen Systemprompt und überlegt dann, wie man ihn testen kann. Man schreibt Tests, und dann findet man einen Systemprompt, der diese Tests besteht.
Im Laufe des Jahres 2024 ist überdeutlich geworden, dass dieAusgezeichnete automatische Auswertungen für LLM-gesteuerte Systeme schreibenist die Fähigkeit, die am meisten benötigt wird, um nützliche Anwendungen auf der Grundlage dieser Modelle zu entwickeln. Wenn Sie über eine starke Evaluierungssuite verfügen, können Sie neue Modelle schneller als Ihre Konkurrenten übernehmen, besser iterieren und zuverlässigere und nützlichere Produktfunktionen entwickeln.
Malte Ubl, Chief Technology Officer von Vercel, meint dazu:
Als v0 (ein Webentwicklungsagent) zum ersten Mal eingeführt wurde, waren wir paranoid, wenn es darum ging, Eingabeaufforderungen mit allen möglichen komplexen Vor- und Nachverarbeitungen zu schützen.
Wir haben uns völlig darauf verlegt, sie frei laufen zu lassen. Keine Bewertung, Modellierung und vor allem UX-Anweisungen sind wie eine kaputte ASML-Maschine ohne Anleitung.
Ich versuche immer noch, ein besseres Modell für meine eigene Arbeit zu finden. Jeder weiß, dass Bewertungen wichtig sind, aber für dieEs mangelt immer noch an einer guten Anleitung, wie die Bewertung am besten durchgeführt werden kann..
10: Apple Intelligence ist schlecht, aber MLX ist großartig!
Als Mac-Benutzer habe ich jetzt ein viel besseres Gefühl, was die Wahl meiner Plattform angeht.
Im Jahr 2023 habe ich das Gefühl, dass ich keinen Linux/Windows-Rechner mit einem NVIDIA-Grafikprozessor habe, was für mich ein großer Nachteil ist, um neue Modelle auszuprobieren.
Theoretisch sollte ein Mac mit 64 GB ein guter Rechner für die Ausführung von Modellen sein, da sich CPU und GPU die gleiche Menge an Speicher teilen können. In der Praxis werden viele Modelle als Modellgewichte und Bibliotheken veröffentlicht, wobei NVIDIAs CUDA gegenüber anderen Plattformen bevorzugt wird.
lama.cpp Das Ökosystem hat dabei sehr geholfen, aber der wirkliche Durchbruch war die MLX-Bibliothek von Apple, die fantastisch ist.
Apples mlx-lm Python-Unterstützung führt eine Vielzahl von mlx-kompatiblen Modellen auf meinem Mac mit hervorragender Leistung aus. Die mlx-Community auf Hugging Face stellt über 1000 Modelle zur Verfügung, die in die erforderlichen Formate konvertiert wurden. Das mlx-vlm-Projekt von Prinz Canuma ist ausgezeichnet und schreitet schnell voran und bringt auch visuelle LLMs zu Apple Prinz Canumas mlx-vlm Projekt ist ausgezeichnet und schreitet schnell voran, und hat auch visuelle LLMs zu Apple Silicon gebracht.
Während MLX eine Neuerung darstellte, waren Apples eigene Apple Intelligence-Funktionen eher enttäuschend. Ich habe bereits im Juni einen Artikel über die ursprüngliche Veröffentlichung geschrieben und war damals optimistisch, dass Apple sich auf den Schutz der Privatsphäre der Nutzer konzentriert und die Irreführung der Nutzer über LLM-Apps minimiert hat.
Jetzt, wo diese Funktionen verfügbar sind, sind sie immer noch relativ ineffektiv. Als intensiver Nutzer von LLM weiß ich, wozu diese Modelle in der Lage sind, und die LLM-Funktionen von Apple sind nur eine blasse Imitation der modernsten LLM-Funktionen. Stattdessen erhalten wir Benachrichtigungszusammenfassungen, die die Schlagzeilen verfälschen, und ich glaube nicht einmal, dass der Schreibassistent überhaupt nützlich ist. Trotzdem ist Genmoji ziemlich lustig.
11. die Skalierung von Schlussfolgerungen, der Aufstieg von "schlussfolgernden" Modellen
Die interessanteste Entwicklung im letzten Quartal 2024 war das Aufkommen einer neuen LLM-Morphologie, die durch die o1-Modelle von OpenAI veranschaulicht wird - o1-preview und o1-mini wurden am 12. September veröffentlicht. Eine Möglichkeit, diese Modelle zu betrachten, ist eine Erweiterung der Technik der Gedankenkettenaufforderung.
Der Trick ist vor allem, dassWenn man ein Modell dazu bringt, intensiv über das Problem nachzudenken (laut zu sprechen), das es löst, erhält man in der Regel ein Ergebnis, das das Modell sonst nicht hätte erzielen können..
o1 bettet diesen Prozess weiter in das Modell ein. Die Details sind etwas unscharf: Das o1-Modell gibt "Argumentationstoken" aus, um über das Problem nachzudenken, was der Benutzer nicht direkt sehen kann (obwohl die ChatGPT-Benutzeroberfläche eine Zusammenfassung anzeigt), und gibt dann das Endergebnis aus.
Die größte Neuerung besteht darin, dass sie einen neuen Weg zur Erweiterung des Modells eröffnet: Modelle können nun schwierigere Probleme lösen, indem sie mehr Rechenaufwand für die Inferenz aufwenden, dieAnstatt die Leistung des Modells nur durch eine Erhöhung des Rechenaufwands zur Trainingszeit zu verbessern.
Der Nachfolger von o1, o3, wurde am 20. Dezember veröffentlicht und erzielte in den ARC-AGI-Benchmarks beeindruckende Ergebnisse, obwohl er möglicherweise mehr als 1 Million Dollar an Rechenzeit gekostet hat!
o3 wird voraussichtlich im Januar veröffentlicht werden. Ich bezweifle, dass es viele Menschen mit realen Problemen gibt, die von einem derartigen Rechenaufwand profitieren würden - ich jedenfalls nicht! Aber es scheint ein echter nächster Schritt in der LLM-Architektur zur Lösung schwierigerer Probleme zu sein.
OpenAI ist nicht der einzige Akteur in diesem Bereich. Am 19. Dezember veröffentlichte Google seinen ersten Neuzugang in diesem Bereich - gemini-2.0-flash-thinking-exp.
Das Qwen-Team von Alibaba veröffentlichte das QwQ-Modell am 28. November unter der Apache-2.0-Lizenz. Am 24. Dezember wurde dann ein visuelles Inferenzmodell namens QvQ veröffentlicht.
DeepSeek Das Modell DeepSeek-R1-Lite-Preview wurde am 20. November über die Chat-Schnittstelle zum Testen zur Verfügung gestellt.
Anmerkung der Redaktion: Wisdom Spectrum wurde ebenfalls am letzten Tag des Jahres 2024 veröffentlicht.Tiefgehende Reasoning-Modelle GLM-Zero.
Anthropic und Meta haben noch keine Fortschritte gemacht, aber es würde mich sehr überraschen, wenn sie nicht über ein eigenes Modell zur Erweiterung der Inferenz verfügen.
12. wird der beste LLM derzeit in China ausgebildet??
Nicht genau, aber fast! Es ist eine tolle Überschrift, die ins Auge fällt.
DeepSeek v3 ist ein gewaltiges parametrisches Modell von 685B - eines der größten öffentlich lizenzierten Modelle, die es gibt, und viel größer als das größte Modell der Llama-Familie von Meta, Llama 3.1 405B.
Benchmarks zeigen, dass es mit dem Claude 3.5 Sonnet gleichauf ist, und die Vibe-Benchmarks platzieren es derzeit auf Platz 7, hinter den Modellen Gemini 2.0 und OpenAI 4o/o1. Dies ist das am höchsten eingestufte öffentlich lizenzierte Modell bis heute.
Was wirklich beeindruckend ist, ist, dassDeepSeek v3AusbildungskostenDas Modell wurde in 2788000 H800 GPU-Stunden zu geschätzten Kosten von $5576000 trainiert. Das Modell wurde in 2788000 H800-GPU-Stunden zu geschätzten Kosten von 5576000 $ trainiert. Llama 3.1 405B wurde in 30840000 GPU-Stunden trainiert, 11 Mal so viel wie DeepSeek v3, aber die Basisleistung des Modells war etwas schlechter.
Die US-Vorschriften für chinesische GPU-Exporte haben offenbar zu einigen sehr wirksamen Optimierungen der Ausbildung geführt.
13. die Umweltauswirkungen von Bedienerhinweisen wurden verbessert.
Unabhängig davon, ob es sich um ein gehostetes Modell handelt oder um eines, das ich lokal betreibe, ist eines der willkommenen Ergebnisse der gesteigerten Effizienz, dass der Energieverbrauch und die Umweltauswirkungen des Prompt-Betriebs in den letzten Jahren stark reduziert werden konnten.
Die Gebühren für die Eingabeaufforderung von OpenAI sind 100 Mal niedriger als die von GPT-3.Ich weiß aus zuverlässiger Quelle, dass weder Google Gemini noch Amazon Nova (die beiden günstigsten Modellanbieter) sofort mit Verlust arbeiten.
Das bedeutet, dass wir als einzelne Nutzer überhaupt kein schlechtes Gewissen haben müssen, weil die meisten Eingabeaufforderungen Energie verbrauchen. Verglichen mit dem Autofahren auf der Straße oder sogar dem Ansehen eines Videos auf YouTube sind die Auswirkungen vielleicht vernachlässigbar.
Das Gleiche gilt für die Ausbildung. deepSeek v3 kostet weniger als 6 Millionen Dollar für die Ausbildung, was ein sehr gutes Zeichen dafür ist, dass die Ausbildungskosten weiter sinken können und sollten.
14. neue Rechenzentren, sind sie noch notwendig?
Und das größere Problem ist, dass es einen erheblichen Wettbewerbsdruck geben wird, um die Infrastruktur aufzubauen, die diese Modelle in Zukunft benötigen werden.
Unternehmen wie Google, Meta, Microsoft und Amazon geben Milliarden von Dollar für neue Rechenzentren aus, was enorme Auswirkungen auf das Stromnetz und die Umwelt hat. Es wird sogar über den Bau neuer Kernkraftwerke gesprochen, aber das wird Jahrzehnte dauern.
Ist diese Infrastruktur notwendig? 6 Millionen Dollar Ausbildungskosten für DeepSeek v3 und die kontinuierliche Senkung der LLM-Preise könnten ausreichen, um dies zu begründen. Aber würden Sie gerne der große Tech-Manager sein, der gegen diese Infrastruktur argumentiert, nur um ein paar Jahre später das Gegenteil zu erfahren?
Ein interessanter Kontrast ist die Entwicklung der Eisenbahnen auf der ganzen Welt im 19. Jahrhundert. Jahrhundert. Der Bau dieser Eisenbahnen erforderte enorme Investitionen, hatte enorme Auswirkungen auf die Umwelt und viele der gebauten Strecken erwiesen sich als unnötig.
Die daraus resultierenden Blasen führten zu mehreren finanziellen Zusammenbrüchen und hinterließen uns eine Menge nützlicher Infrastrukturen, aber auch viele Konkurse und Umweltschäden.
15.2024, das Jahr des "Slops"
2024 ist das Jahr, in dem das Wort "Slop" zu einem Kunstbegriff wird. schrieb @deepfates auf Twitter:
So wie "Spam" zu einem Eigennamen für unerwünschte E-Mails wurde, wird "Slop" im Wörterbuch als Eigenname für unerwünschte, von der KI generierte Inhalte erscheinen.
Ich habe im Mai einen Beitrag geschrieben, in dem ich diese Definition ein wenig erweitert habe:
"Slop" bezieht sich auf unerwünschte und unzensierte Inhalte, die von künstlicher Intelligenz erzeugt werden.
Ich mag das Wort "Slop", denn es fasst kurz und bündig zusammen, wie wir generative KI nicht einsetzen sollten!
16. synthetische Trainingsdaten, sehr effektiv
Überraschenderweise scheint der Begriff des "Modellkollapses" - d. h., dass KI-Modelle zusammenbrechen, wenn sie auf rekursiv generierten Daten trainiert werden - tief im öffentlichen Bewusstsein verankert zu sein. .
Die Idee ist verführerisch: Wenn KI-generierter "Müll" das Internet überflutet, werden die Modelle selbst degenerieren, sich von ihrem eigenen Output ernähren und zu ihrem unvermeidlichen Untergang führen!
Offensichtlich ist dies nicht geschehen. Stattdessen sehen wir, dass KI-Labore zunehmend mit synthetischen Inhalten trainieren - indem sie künstliche Daten erzeugen, die ihren Modellen helfen, in die richtige Richtung zu lenken.
Eine der besten Beschreibungen, die ich kenne, stammt aus dem technischen Phi-4-BerichtIm Folgenden sind einige Elemente des Programms aufgeführt:
Synthetische Daten werden immer häufiger zu einem wichtigen Bestandteil des Pre-Trainings, und die Phi-Modellfamilie hat stets die Bedeutung synthetischer Daten hervorgehoben. Synthetische Daten sind nicht nur eine billige Alternative zu realen Daten, sondern haben auch mehrere direkte Vorteile gegenüber realen Daten.
Strukturiertes progressives Lernen. In realen Datensätzen sind die Beziehungen zwischen Token oft komplex und indirekt. Viele Inferenzschritte können erforderlich sein, um das aktuelle Token mit dem nächsten Token in Verbindung zu bringen, was es für das Modell schwierig macht, effektiv aus der Vorhersage des nächsten Tokens zu lernen. Im Gegensatz dazu wird jedes von einem Sprachmodell erzeugte Token durch das vorherige Token vorhergesagt, was es dem Modell erleichtert, dem daraus resultierenden Inferenzmuster zu folgen.
Eine weitere gängige Technik ist die Verwendung größerer Modelle zur Erstellung von Trainingsdaten für kleinere, weniger teure Modelle, und immer mehr Labors verwenden diese Technik.
DeepSeek v3 verwendet DeepSeek-R1 Meta's Llama 3.3 70B fine-tuning verwendet über 25 Millionen synthetisch generierte Beispiele.
Die sorgfältige Planung der für LLM verwendeten Trainingsdaten scheint der Schlüssel zur Erstellung dieser Modelle zu sein. Die Zeiten, in denen man sich alle Daten aus dem Internet schnappte und sie wahllos in Trainingsläufe einspeiste, sind längst vorbei.
17 Der richtige Umgang mit LLM ist nicht einfach!
Ich habe immer betont, dass LLMs leistungsstarke Benutzerwerkzeuge sind - sie sind Kettensägen, getarnt als Hubschrauber. Sie sehen einfach aus - wie schwer kann es sein, eine Nachricht an einen Chatbot zu tippen? Aber in Wirklichkeit.Um sie optimal zu nutzen und ihre zahlreichen Fallstricke zu vermeiden, müssen Sie ein tiefes Verständnis und viel Erfahrung mit ihnen haben.
Dieses Problem wird sich im Jahr 2024 noch verschärfen.
Wir haben Computersysteme entwickelt, mit denen man in menschlicher Sprache sprechen kann und die Ihre Fragen beantworten können - und in der Regel auch richtig liegen! ...... Das hängt davon ab, wie die Frage lautet, wie sie gestellt wird und ob sie in einem geheimen Trainingssatz ohne Aufzeichnung genau wiedergegeben werden kann.
Heute gibt es immer mehr Systeme, die zur Verfügung stehen. Verschiedene Systeme verfügen über unterschiedliche Werkzeuge, die zur Lösung Ihres Problems verwendet werden können, wie Python, JavaScript, Websuche, Bilderzeugung und sogar Datenbankabfragen ...... Sie sollten also besser verstehen, was diese Werkzeuge sind, was sie können und wie Sie feststellen können, ob der LLM sie verwendet.
Wussten Sie, dass ChatGPT jetzt zwei völlig unterschiedliche Möglichkeiten bietet, Python auszuführen?
Wenn Sie ein Claude-Artefakt erstellen möchten, das mit einer externen API kommuniziert, sollten Sie sich mit CSP und CORS HTTP-Headern vertraut machen.
Die Fähigkeiten dieser Modelle mögen sich verbessert haben, aber die meisten Beschränkungen bleiben bestehen. o1 von OpenAI ist vielleicht endlich in der Lage, das "r" in Erdbeere (größtenteils) zu berechnen, aber seine Fähigkeiten sind immer noch durch seine Natur als LLM und durch seine Laufzeit-Kabelbäume beschränkt. o1 kann keine Websuche durchführen oder einen Code-Interpreter verwenden, aber GPT-4o kann es - beide sind in der gleichen ChatGPT-Benutzeroberfläche. GPT-4o kann - beide befinden sich in der gleichen ChatGPT-Benutzeroberfläche.
Was haben wir dagegen unternommen? Nichts. Die meisten Benutzer sind "Neulinge". Die Standard-LLM-Chat-Benutzeroberfläche ist so, als würde man brandneue Computerbenutzer in ein Linux-Terminal setzen und von ihnen erwarten, dass sie alles selbst machen können.
Gleichzeitig kommt es immer häufiger vor, dass die Endnutzer ungenaue Vorstellungen von der Funktionsweise dieser Geräte entwickeln. Ich habe viele Beispiele dafür gesehen, wie Leute versucht haben, Argumente mit Screenshots von ChatGPT zu gewinnen - was angesichts der inhärenten Unzuverlässigkeit dieser Modelle in Verbindung mit der Tatsache, dass man sie dazu bringen kann, alles zu sagen, wenn man die richtige Aufforderung gibt, ein lächerliches Unterfangen gewesen wäre.
Es gibt aber auch eine Kehrseite: Viele "alte Hasen" haben das LLM ganz aufgegeben, weil sie nicht verstehen, wie jemand von einem Werkzeug profitieren kann, das so viele Schwächen hat. Der Schlüssel, um das Beste aus dem LLM herauszuholen, liegt darin, zu lernen, wie man diese unzuverlässige, aber leistungsstarke Technik einsetzt. Dies ist eindeutig keine selbstverständliche Fähigkeit!
Es gibt zwar so viele nützliche Bildungsinhalte, aber wir müssen mehr tun, als alles an die KI-Agenten auszulagern, die darüber twittern und schimpfen.
18. schlechte Kognition, noch vorhanden
Jetzt.Die meisten Menschen haben schon von ChatGPT gehört, aber wie viele haben schon von Claude gehört?
Zwischen denjenigen, die sich aktiv mit diesen Fragen befassen, und denjenigen, die sich nicht damit befassen, gibt es eine 99%Die große Wissenskluft.
Letzten Monat haben wir gesehen, wie beliebt Echtzeit-Schnittstellen sind, bei denen man die Kamera seines Handys auf etwas richten und mit seiner Stimme darüber sprechen kann ...... Es gibt auch die Möglichkeit, so zu tun, als wäre man der Weihnachtsmann. Die meisten selbstzertifizierten Menschen (sic "Nerd") haben das noch nicht ausprobiert.
In Anbetracht der anhaltenden (und potenziellen) Auswirkungen dieser Technologie auf die Gesellschaft bin ich der Meinung, dass die derzeitigeDiese Kluft ist ungesund. Ich würde mir mehr Anstrengungen zur Verbesserung der Situation wünschen.
19.LLM, bessere Kritik nötig
Viele Leute hassen das LLM-Zeug wirklich. Auf einigen der Websites, die ich besuche, reicht schon die Andeutung, dass "ein LLM sehr nützlich ist", um einen Krieg auszulösen.
Ich verstehe das. Es gibt viele Gründe, warum die Menschen diese Technologie nicht mögen - Umweltauswirkungen, mangelnde Zuverlässigkeit der Trainingsdaten, unvorteilhafte Anwendungen, potenzielle Auswirkungen auf die Arbeitsplätze der Menschen.
LLM hat definitiv Kritik verdient.Wir müssen diese Probleme erörtern, Wege zu ihrer Entschärfung finden und den Menschen helfen, einen verantwortungsvollen Umgang mit diesen Instrumenten zu erlernen, damit ihre positiven Anwendungen ihre negativen Auswirkungen überwiegen.
Ich liebe Menschen, die dieser Technologie gegenüber skeptisch sind. Seit mehr als zwei Jahren ist der Hype gewachsen, und eine Menge Fehlinformationen haben den Äther überschwemmt. Viele schlechte Entscheidungen wurden auf der Grundlage dieses Hypes getroffen.Kritik ist eine Tugend.
Wenn wir wollen, dass Menschen mit Entscheidungsbefugnis die richtigen Entscheidungen über die Anwendung dieser Instrumente treffen, müssen wir zunächst anerkennen, dass es tatsächlich gute Anwendungen gibt, und dann helfen, zu erklären, wie man sie in die Praxis umsetzt und dabei viele der unpraktischen Fallstricke vermeidet.
Glaube ich.Den Leuten zu sagen, dass die gesamte Branche eine umweltzerstörerische Plagiatsmaschine ist, die ständig etwas erfindet, egal wie viel Wahrheit darin steckt, ist ein Bärendienst für diese Leute... Es gibt hier einen echten Wert, aber diesen Wert zu erkennen, ist nicht intuitiv und erfordert Anleitung.
Diejenigen von uns, die sich mit dieser Materie auskennen, haben die Verantwortung, anderen zu helfen, sie zu verstehen.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...