450 um eine 'o1-Vorschau' zu trainieren?UC Berkeley veröffentlicht 32B Inferenzmodell Sky-T1, KI-Gemeinschaft ist begeistert
Ein Preisschild von 450 Dollar klingt zunächst nicht nach viel. Aber was ist, wenn das die gesamten Kosten für das Training eines 32B-Inferenzmodells sind?
Ja, im Jahr 2025 wird die Entwicklung von Inferenzmodellen immer einfacher, und die Kosten sinken rasch auf ein Niveau, das wir uns vorher nicht vorstellen konnten.
Kürzlich hat NovaSky, ein Forschungsteam am Sky Computing Lab der University of California, Berkeley, Sky-T1-32B-Preview veröffentlicht. Interessanterweise, so das Team, "kostet Sky-T1-32B-Preview weniger als 450 Dollar, um es zu trainieren, was darauf hindeutet, dass es möglich ist, High-Level-Reasoning-Fähigkeiten wirtschaftlich und effizient zu replizieren".

- Projekt-Homepage: https://novasky-ai.github.io/posts/sky-t1/
- Adresse der offenen Quelle: https://huggingface.co/NovaSky-AI/Sky-T1-32B-Preview
Nach offiziellen Angaben hat dieses Inferenzmodell eine frühere Version von OpenAI o1 in mehreren wichtigen Benchmarks übertroffen.

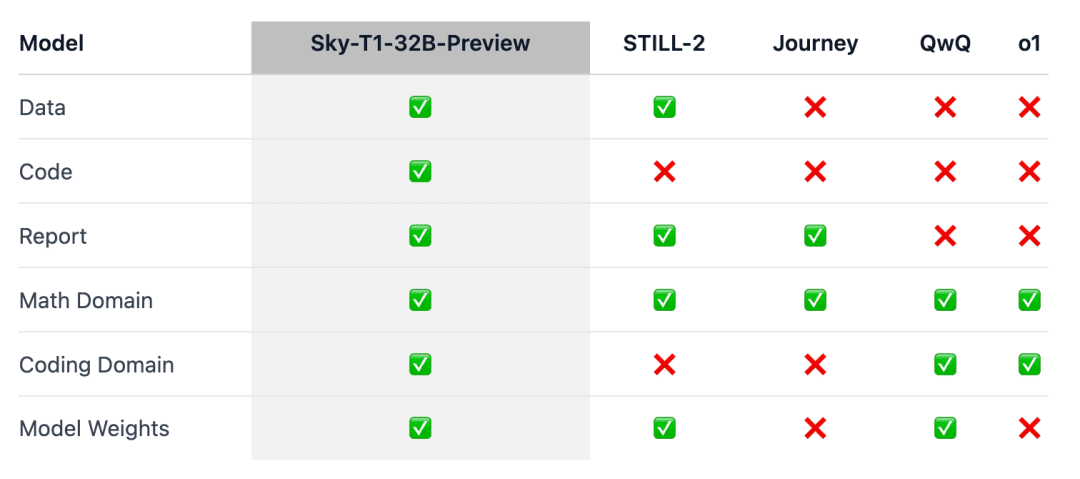
Sky-T1 scheint das erste wirklich quelloffene Inferenzmodell zu sein, da das Team sowohl den Trainingsdatensatz als auch den erforderlichen Trainingscode veröffentlicht hat, damit jeder das Modell von Grund auf nachbauen kann.
Die Leute riefen aus: "Was für ein erstaunlicher Beitrag an Daten, Code und Modellgewichten".
Es ist noch nicht lange her, dass die Kosten für die Ausbildung eines Modells mit gleicher Leistung oft in die Millionen Dollar gingen. Mit synthetischen oder von anderen Modellen generierten Trainingsdaten konnten die Kosten erheblich gesenkt werden.
Zuvor hatte das KI-Unternehmen Writer den Palmyra X 004 auf den Markt gebracht, der fast ausschließlich mit synthetischen Daten trainiert wurde und dessen Entwicklung nur 700.000 Dollar kostete.
Stellen Sie sich vor, dieses Programm läuft auf dem KI-Supercomputer Nvidia Project Digits, der 3.000 Dollar kostet (günstig für einen Supercomputer) und Modelle mit bis zu 200 Milliarden Parametern ausführen kann. In naher Zukunft werden Modelle mit weniger als 1 Billion Parametern lokal von Einzelpersonen ausgeführt werden.
Die Entwicklung der Big-Model-Technologie im Jahr 2025 beschleunigt sich, und das ist ein wirklich starkes Gefühl.
Überblick über das Modell
Die Argumentation o1 und Zwillinge 2.0 Modelle wie Flash Thinking haben komplexe Aufgaben gelöst und andere Fortschritte gemacht, indem sie lange interne Gedankenketten erzeugen. Technische Details und Modellgewichte sind jedoch nicht verfügbar, was ein Hindernis für das Engagement der akademischen und Open-Source-Gemeinschaft darstellt.
Zu diesem Zweck wurden auf dem Gebiet der Mathematik einige bemerkenswerte Ergebnisse für das Training von offen gewichteten Inferenzmodellen erzielt, wie z. B. Still-2 und Journey. Das NovaSky-Team an der University of California, Berkeley, hat eine Reihe von Techniken erforscht, um die Inferenzfähigkeiten sowohl von Basis- als auch von Befehlsmodellen zu entwickeln.
In dieser Arbeit, Sky-T1-32B-Preview, erreichte das Team eine konkurrenzfähige Inferenzleistung nicht nur auf der mathematischen Seite, sondern auch auf der Codierungsseite desselben Modells.

Um sicherzustellen, dass diese Arbeit der Allgemeinheit zugute kommt, hat das Team alle Details (z. B. Daten, Code, Modellgewichte) offengelegt, so dass die Allgemeinheit sie leicht reproduzieren und verbessern kann:
- Infrastruktur: Erstellung von Daten, Training und Auswertung von Modellen in einem einzigen Repository;
- Daten: 17K Daten, die zum Training von Sky-T1-32B-Preview verwendet wurden;
- Technische Details: technische Berichte und wandb-Protokolle;
- Modellgewichte: 32B Modellgewichte.
Technische Einzelheiten
Prozess der Datenerhebung
Zur Generierung der Trainingsdaten verwendete das Team QwQ-32B-Preview, ein Open-Source-Modell mit Inferenzfähigkeiten, die mit denen von o1-preview vergleichbar sind. Das Team organisierte den Datenmix so, dass er die verschiedenen Bereiche abdeckte, in denen Schlussfolgerungen erforderlich waren, und verwendete ein Rückweisungsstichprobenverfahren, um die Qualität der Daten zu verbessern.
Dann schrieb das Team, inspiriert von Still-2, die QwQ-Spur in eine strukturierte Version mit GPT-4o-mini um, um die Datenqualität zu verbessern und das Parsing zu vereinfachen.
Sie stellten fest, dass die Einfachheit des Parsing besonders für Inferenzmodelle von Vorteil ist. Sie sind darauf trainiert, in einem bestimmten Format zu antworten, und die Ergebnisse sind oft schwer zu analysieren. Beim APPs-Datensatz zum Beispiel konnte das Team ohne Umformatierung nur davon ausgehen, dass der Code im letzten Codeblock geschrieben wurde, und QwQ konnte nur eine Genauigkeit von etwa 25% erreichen. Manchmal kann der Code jedoch in der Mitte geschrieben sein, und nach der Neuformatierung steigt die Genauigkeit auf über 90%.
Probe verwerfen. Je nach der mit dem Datensatz gelieferten Lösung verwirft das Team die QwQ-Stichprobe, wenn sie falsch ist. Bei mathematischen Problemen führt das Team einen exakten Abgleich mit der Lösung der Grundwahrheit durch. Bei Codierungsproblemen führt das Team die im Datensatz enthaltenen Unit-Tests durch. Die endgültigen Daten des Teams bestehen aus 5k kodierten Daten von APPs und TACO und 10k mathematischen Daten aus der Olympiaden-Untermenge der AIME-, MATH- und NuminaMATH-Datensätze. Zusätzlich behielt das Team 1k an Wissenschafts- und Rätseldaten aus STILL-2.
Zug
Das Team verwendete die Trainingsdaten zur Feinabstimmung von Qwen2.5-32B-Instruct, einem Open-Source-Modell ohne Inferenzfunktionen. Das Modell wurde mit 3 Epochen, einer Lernrate von 1e-5 und einer Stapelgröße von 96 trainiert. Das Training des Modells wurde in 19 Stunden auf 8 H100s mit einem DeepSpeed Zero-3 Offload abgeschlossen (laut Lambda Cloud zu einem Preis von etwa 450 $). Das Team verwendete Llama-Factory für das Training.
Bewertungsergebnisse
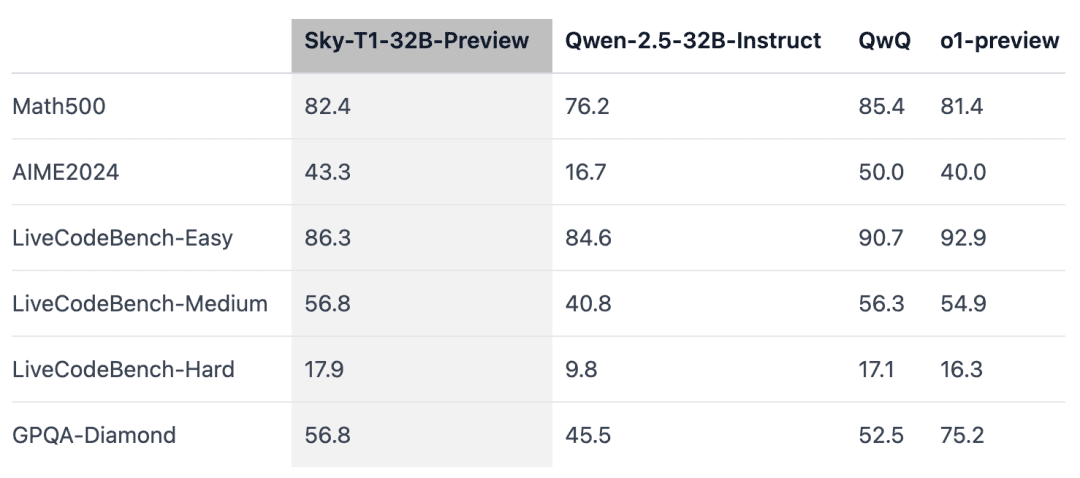
Sky-T1 übertraf eine frühere Vorabversion von o1 bei MATH500, einer Mathematikaufgabe auf Wettbewerbsniveau, und schlug auch eine Vorabversion von o1 bei einer Reihe von Rätseln von LiveCodeBench, einer Bewertung von Programmieraufgaben. Sky-T1 ist jedoch nicht so gut wie die Vorabversion von o1 bei GPQA-Diamond, das Aufgaben aus den Bereichen Physik, Biologie und Chemie enthält, die Promovierte kennen sollten.
OpenAIs o1 GA-Version ist jedoch leistungsfähiger als die Vorabversion von o1, und OpenAI wird voraussichtlich in den kommenden Wochen ein leistungsfähigeres Inferenzmodell, o3, veröffentlichen.
Neue Erkenntnisse, die Aufmerksamkeit verdienen
Die Größe des Modells ist wichtig.Das Team versuchte zunächst, mit kleineren Modellen (7B und 14B) zu trainieren, stellte aber nur geringe Verbesserungen fest. Das Training von Qwen2.5-14B-Coder-Instruct auf dem APPs-Datensatz zeigte beispielsweise eine leichte Verbesserung der Leistung im LiveCodeBench von 42,6% auf 46,3%. Bei der manuellen Prüfung der Ausgabe der kleineren Modelle (kleiner als 32B) stellte das Team jedoch fest, dass sie häufig doppelte Inhalte generierten, was die Effektivität ihre Effektivität einschränkte.
Die Datenvermischung ist wichtig.Das Team trainierte das 32B-Modell zunächst mit 3-4K Mathematikaufgaben aus dem Numina-Datensatz (bereitgestellt von STILL-2), und die Genauigkeit von AIME24 verbesserte sich signifikant von 16,7% auf 43,3%. Als jedoch Programmierdaten aus dem APPs-Datensatz in den Trainingsprozess einbezogen wurden, sank die Genauigkeit von AIME24 auf 36,7%. Es ist möglich, dass dieser Rückgang auf die unterschiedlichen Inferenzmethoden zurückzuführen ist, die für die Mathematik- und Programmieraufgaben erforderlich sind.
Die Argumentation in der Programmierung umfasst in der Regel zusätzliche logische Schritte wie die Simulation von Testeingaben oder die interne Ausführung von generiertem Code, während die Argumentation bei mathematischen Problemen in der Regel einfacher und strukturierter ist.Um diese Unterschiede auszugleichen, reicherte das Team die Trainingsdaten mit anspruchsvollen mathematischen Problemen aus dem NuminaMath-Datensatz und komplexen Programmieraufgaben aus dem TACO-Datensatz an. Diese ausgewogene Mischung von Daten ermöglichte es dem Modell, in beiden Bereichen zu glänzen und eine Genauigkeit von 43,3% bei AIME24 zu erreichen und gleichzeitig seine Programmierfähigkeiten zu verbessern.
Gleichzeitig haben sich einige Forscher skeptisch geäußert:


Was denken die Leute darüber? Diskutieren Sie darüber im Kommentarbereich.
Referenzlink: https://www.reddit.com/r/LocalLLaMA/comments/1hys13h/new_model_from_httpsnovaskyaigithubio/
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...