
A Sesame lança o modelo de fala conversacional CSM: tornando a interação de voz com IA mais natural
Uma publicação recente no blog de Brendan Iribe, Ankit Kumar e a equipe da Sesame descreve a mais recente pesquisa da empresa no campo da geração de fala conversacional, o Conversational Speech Model (CSM). CSM). O modelo foi projetado para lidar com a falta de emoção e naturalidade nas interações atuais com assistentes de voz, aproximando as interações de voz com IA do nível humano.
Atravessando o "Vale do Terror" na busca por "presença de voz".
A equipe da Sesame acredita que a voz é o meio de comunicação mais íntimo dos seres humanos e contém uma grande quantidade de informações que vão muito além do significado literal. No entanto, os assistentes de voz existentes geralmente carecem de expressão emocional e têm um tom monótono, o que dificulta o estabelecimento de uma conexão profunda com os usuários. Ao usar esses assistentes de voz por um longo período de tempo, os usuários não só se sentirão decepcionados, mas também cansados.
Para resolver esse problema, a Sesame desenvolveu o conceito de "presença de voz", o que significa que as interações de voz parecem reais, compreendidas e valorizadas, e o modelo CSM é uma etapa fundamental para atingir esse objetivo. A equipe da Sesame enfatiza que não está apenas criando uma ferramenta, mas um parceiro de diálogo que constrói uma relação de confiança com o usuário.
Conseguir "presença de voz" não é uma tarefa fácil e requer uma combinação dos seguintes elementos-chave:
- Inteligência emocional: Reconhecer e responder a mudanças no humor do usuário.
- Dinâmica do diálogo: Compreender o ritmo natural do diálogo, inclusive a velocidade da fala, as pausas, as interrupções e a ênfase.
- Consciência situacional: Ajuste do tom e da expressão para diferentes cenários de diálogo.
- Personalidade consistente: Manter a consistência e a confiabilidade da personalidade do assistente de IA.
Modelo CSM: estágio único, multimodal, mais eficiente
Para atingir esses objetivos, a equipe da Sesame propôs um novo modelo de fala conversacional, o CSM, que usa uma estrutura de aprendizado multimodal de ponta a ponta para gerar uma fala mais natural e coerente usando informações do histórico da conversa.
Diferentemente dos modelos tradicionais de conversão de texto em fala (TTS), o modelo CSM opera diretamente em tokens RVQ (residual vector quantisation). Esse design evita o gargalo de informações que pode ser causado por tokens semânticos em modelos TTS tradicionais, capturando melhor as nuances da fala.
CSM O projeto arquitetônico do modelo também é bastante impressionante. Ele emprega dois transformadores autorregressivos:
- Backbone multimodal: Processamento de informações de texto e áudio intercaladas para prever a camada zero do livro de códigos RVQ.
- Decodificador de áudio: Usando um cabeçalho linear diferente para cada livro de códigos, as N-1 camadas restantes são previstas para reconstruir a fala.
Esse design permite que o decodificador seja muito menor que o tronco, resultando em geração de fala de baixa latência e mantendo o modelo de ponta a ponta.

Processo de inferência do modelo CSM
Além disso, para resolver o problema do gargalo de memória durante o processo de treinamento, a equipe do Sesame propôs um esquema de distribuição computacional. Esse esquema treina o decodificador de áudio somente em um subconjunto aleatório de quadros de áudio, o que reduz significativamente o consumo de memória sem afetar o desempenho do modelo.

Distribuição do processo de treinamento
Resultados experimentais: próximo ao nível humano, mas ainda há uma lacuna
A equipe da Sesame treinou o modelo CSM em um conjunto de dados que contém cerca de 1 milhão de horas de áudio em inglês e usou uma variedade de métricas para avaliar minuciosamente o desempenho do modelo.
Os resultados da avaliação mostram que o modelo CSM está próximo do nível humano nas métricas tradicionais de Taxa de Erro de Palavras (WER) e Similaridade do Falante (SIM).
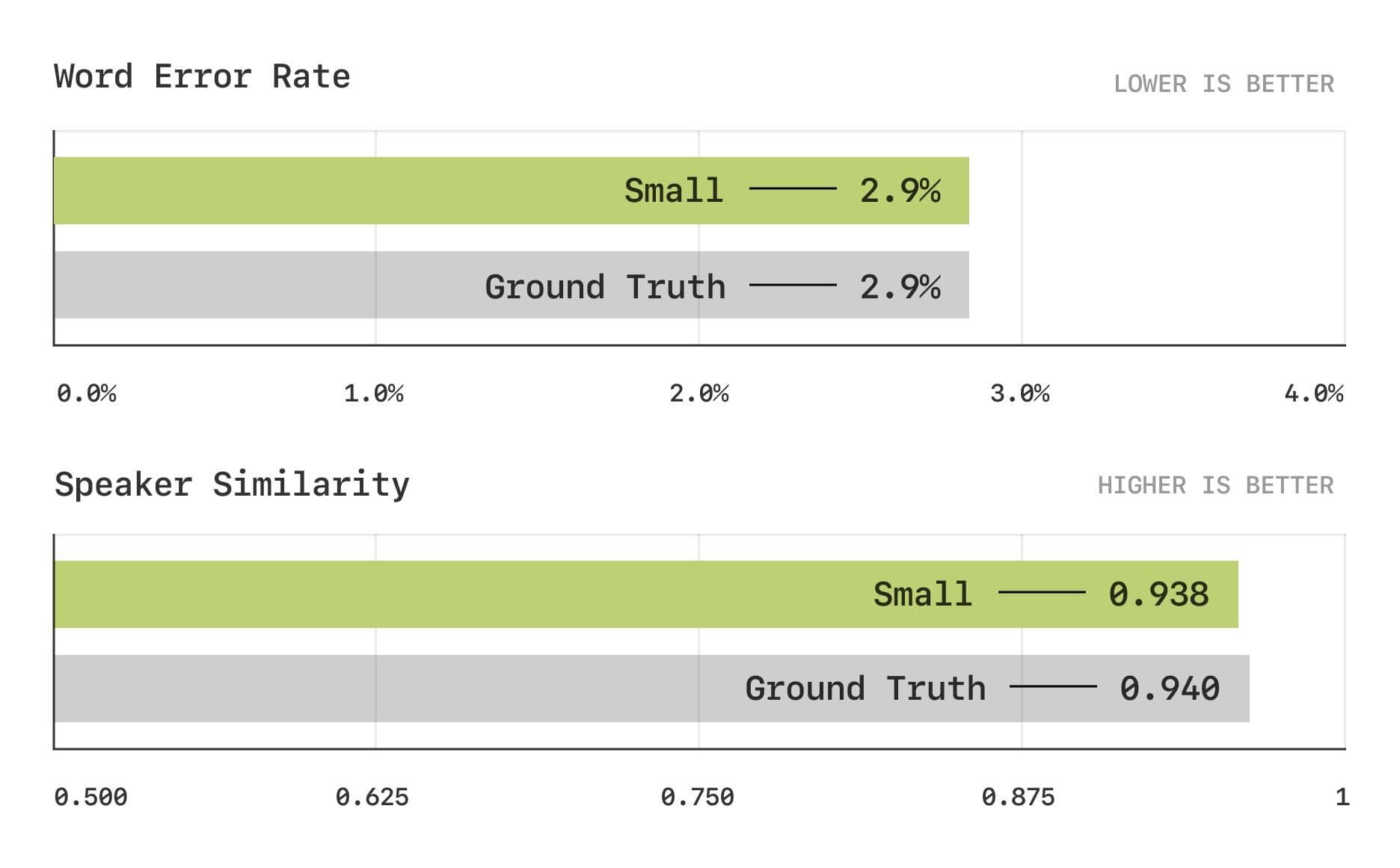
Taxa de erro de palavras e testes de similaridade de locutor
Para avaliar com mais profundidade os recursos do modelo em pronúncia e compreensão de contexto, a equipe do Sesame também introduziu um novo conjunto de testes de benchmark baseados em transcrição de fala, incluindo testes de desambiguação de homófonos e de consistência de pronúncia. Os resultados mostram que o modelo CSM também apresenta bom desempenho nessas áreas e que o desempenho melhora à medida que o tamanho do modelo aumenta.
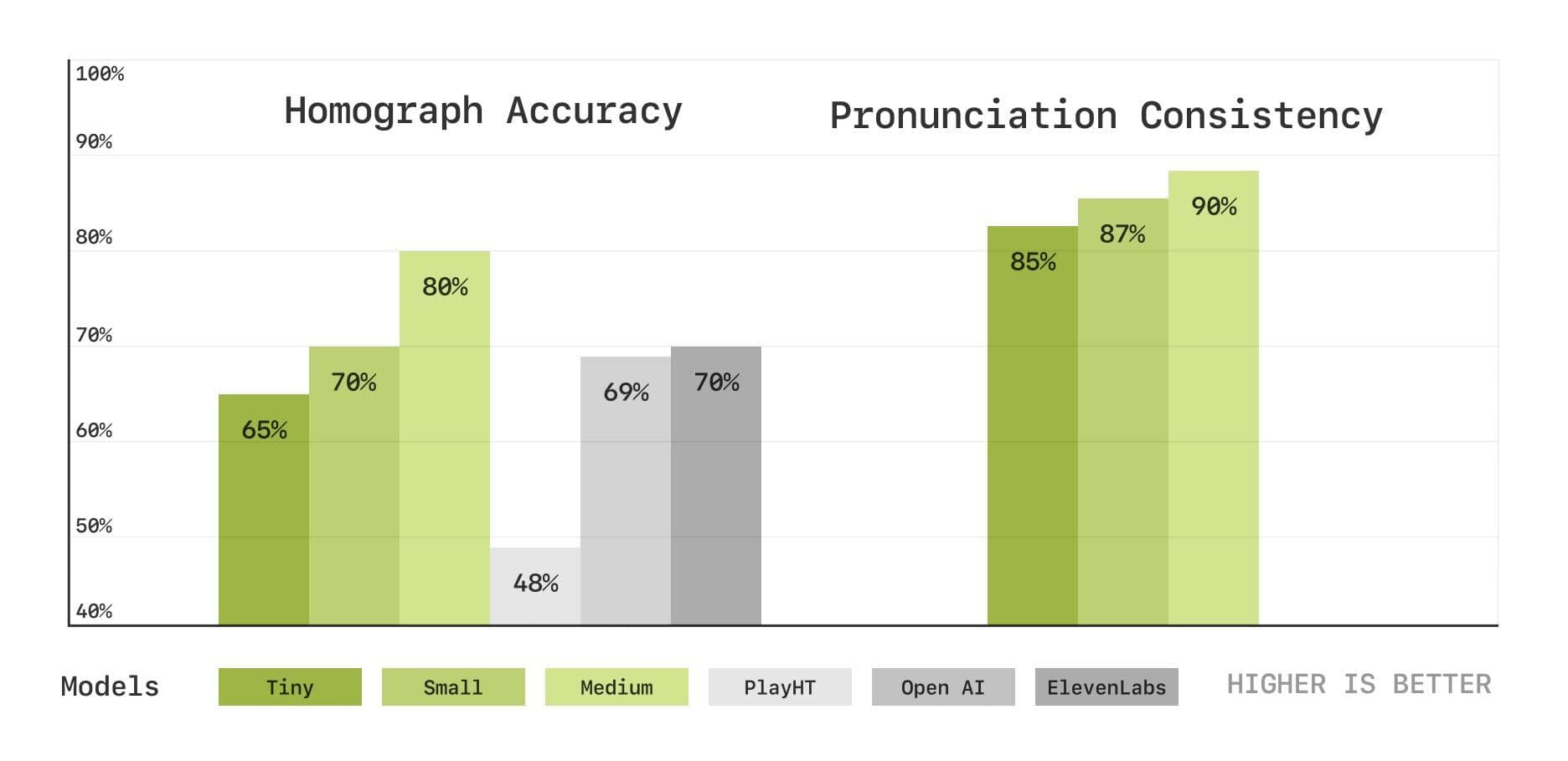
Desambiguação de homófonos e testes de consistência de pronúncia
No entanto, ainda há uma lacuna entre o modelo CSM e a fala humana real em termos de avaliação subjetiva. A equipe da Sesame realizou dois estudos de Comparative Mean Opinion Score (CMOS) usando o conjunto de dados do Expresso. Os resultados mostraram que, sem contexto, os ouvintes tinham preferências comparáveis para a fala gerada pelo CSM e a fala humana real. No entanto, quando as informações contextuais eram fornecidas, os ouvintes preferiam significativamente a fala humana real. Isso sugere que ainda há espaço para melhorias no modelo CSM na captura de mudanças rítmicas sutis no diálogo.
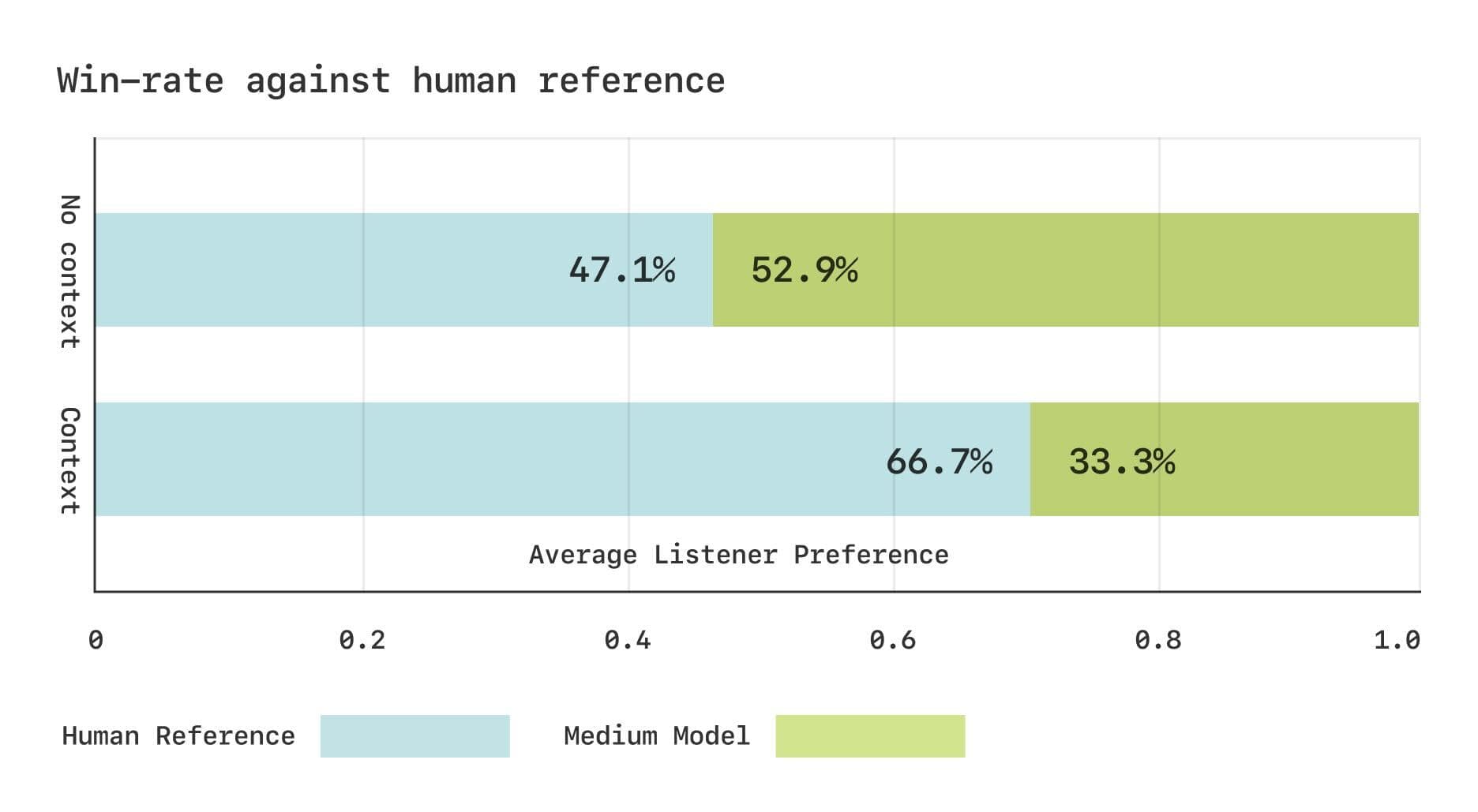
Resultados da avaliação subjetiva do conjunto de dados do Expresso
Compartilhamento de código aberto, perspectivas futuras
No espírito do código-fonte aberto, a equipe do Sesame planeja abrir os principais componentes do modelo CSM para o desenvolvimento mútuo da comunidade.
https://github.com/SesameAILabs/csm
Embora o modelo CSM tenha feito um progresso significativo, ele ainda tem algumas limitações, como o suporte principalmente ao inglês, com recursos multilíngues que precisam ser aprimorados. A equipe da Sesame disse que, no futuro, eles continuarão a expandir o tamanho do modelo, aumentar a capacidade do conjunto de dados, expandir o suporte a idiomas e explorar o uso de modelos de idiomas de pré-treinamento para melhorar ainda mais o desempenho do modelo CSM. A equipe da Sesame está confiante de que o futuro do diálogo de IA está nos modelos full duplex, ou seja, modelos que podem aprender implicitamente a dinâmica do diálogo a partir dos dados.
De modo geral, o modelo CSM lançado pela Sesame é um importante passo à frente no campo da geração de fala conversacional, fornecendo novas ideias para a criação de interações de voz de IA mais naturais e emocionais. Embora ainda haja espaço para melhorias, vale a pena aguardar o espírito de código aberto da equipe da Sesame e os planos para o futuro.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados




Nenhum comentário...