Como escolher o modelo de incorporação correto?
Retrieval Augmented Generation (RAG) é uma classe de aplicativos em IA generativa (GenAI) que suporta o uso dos próprios dados para aumentar o conhecimento de um modelo LLM (por exemplo, ChatGPT).
RAG Três modelos diferentes de IA são comumente usados, a saber, o modelo Embedding, o modelo Rerankear e o modelo Big Language. Neste artigo, abordaremos como escolher o modelo de incorporação correto com base em seu tipo de dados, bem como em seu idioma ou domínio específico (por exemplo, jurídico).
1. dados de texto: classificação do MTEB
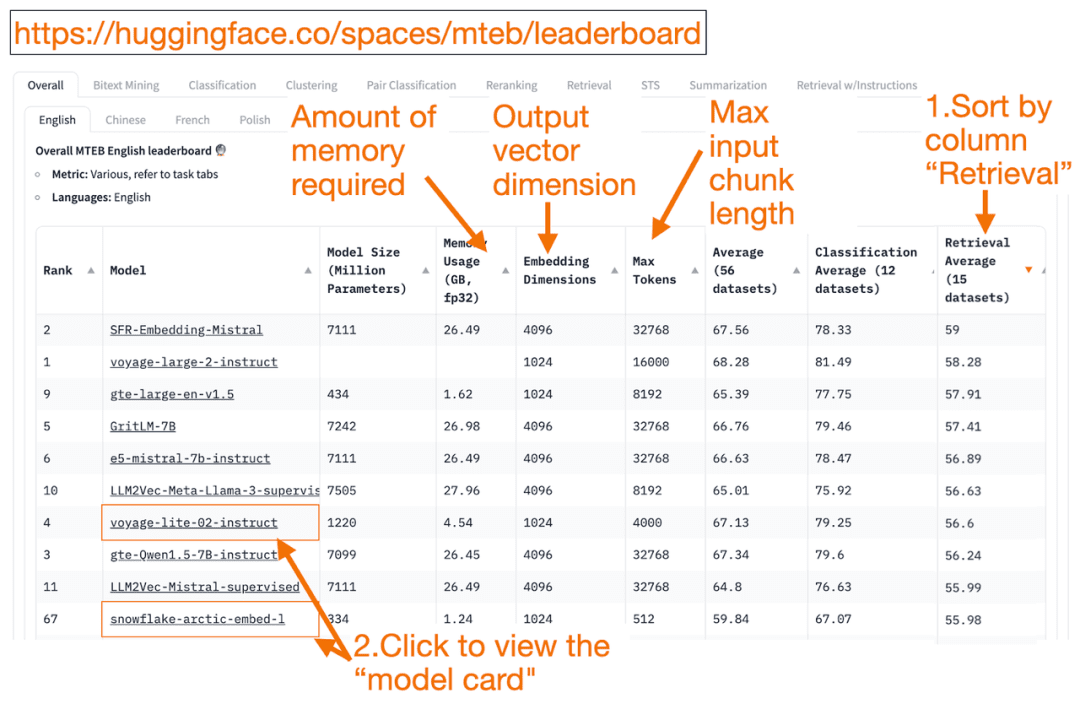
HuggingFace Tabela de classificação do MTEB é uma lista completa de modelos de incorporação de texto! Você pode descobrir o desempenho médio de cada modelo.
Você pode classificar a coluna "Retrieval Average" (média de recuperação) em ordem decrescente, pois isso se ajusta melhor à tarefa de pesquisa de vetores. Em seguida, procure o modelo mais bem classificado com o menor consumo de memória.
- A dimensão do vetor de incorporação é o comprimento do vetor, ou seja, y em f(x)=y, que o modelo produzirá.
- maior Token O número é o comprimento do bloco de texto de entrada, ou seja, x em f(x)=y , que você pode inserir no modelo.
Além de passar o Recuperação Além de classificar as tarefas, você também pode filtrar pelos seguintes critérios:
- Idioma: francês, inglês, chinês e polonês são suportados. (por exemplo: task=recuperação.
Idioma=chinês)
- Textos no campo jurídico.
(por exemplo, task=recuperação, idioma=lei)
É importante observar que, como alguns dos dados de treinamento só foram disponibilizados publicamente recentemente, alguns dos modelos de incorporação no MTEB podem seraparentemente adequadoNo entanto, modelos realmente inadequados com classificações infladas podem ter um desempenho diferente. Como resultado, a HuggingFace postou umablog (palavra emprestada)Ele descreve os principais pontos para determinar se uma classificação de modelo é confiável ou não. Depois de clicar em um link de modelo (chamado de "cartão de modelo"):
- Procure blogs e artigos que expliquem como os modelos são treinados e avaliados. Observe atentamente a linguagem, os dados e as tarefas usadas para o treinamento do modelo. Além disso, procure modelos criados por empresas conhecidas. Por exemplo, no cartão do modelo voyage-lite-02-instruct, você verá outros modelos da VoyageAI listados, mas não esse. Isso é uma dica! Esse modelo é um modelo de ajuste excessivo e não deve ser usado!
- Na captura de tela abaixo, tentarei o novo modelo "snowflake-arctic-embed-1" do Snowflake porque ele é altamente classificado, pequeno o suficiente para ser executado no meu laptop e tem links para blogs e documentos no cartão do modelo.
A vantagem de usar o HuggingFace é que, se você precisar alterar o modelo depois de selecionar o modelo Embedding, basta alterar o model_name no código!
import torch
from sentence_transformers import SentenceTransformer
# Initialize torch settings
torch.backends.cudnn.deterministic = True
DEVICE = torch.device('cuda:3' if torch.cuda.is_available() else 'cpu')
# Load the model from Huggingface
model_name = "WhereIsAI/UAE-Large-V1" # Just change model_name to use a different model!
encoder = SentenceTransformer(model_name, device=DEVICE)
# Get the model parameters and save for later
EMBEDDING_DIM = encoder.get_sentence_embedding_dimension()
MAX_SEQ_LENGTH_IN_TOKENS = encoder.get_max_seq_length()
# Print model parameters
print(f"model_name: {model_name}")
print(f"EMBEDDING_DIM: {EMBEDDING_DIM}")
print(f"MAX_SEQ_LENGTH: {MAX_SEQ_LENGTH_IN_TOKENS}")

2) Dados da imagem: ResNet50
Às vezes, você pode querer pesquisar imagens que sejam semelhantes à imagem inserida. Por exemplo, você pode estar procurando mais imagens de gatos Scottish Fold. Nesse caso, você pode carregar uma foto de um gato Scottish Fold e pedir ao mecanismo de busca que encontre imagens semelhantes.
ResNet50 é um modelo CNN popular originalmente treinado pela Microsoft em 2015 usando dados do ImageNet.
Da mesma forma, paraPesquisa de vídeoNesse caso, o ResNet50 ainda pode converter o vídeo em vetores de incorporação. Em seguida, é realizada uma pesquisa de similaridade nos quadros de vídeo estáticos e o vídeo mais semelhante é retornado ao usuário como a melhor correspondência.
3. dados de áudio: PANNs
Semelhante à pesquisa de imagens, você também pode pesquisar áudio semelhante com base em clipes de áudio de entrada.
PANNs(Redes neurais de áudio pré-treinadas) são comumente usadas como modelos de incorporação para pesquisa de áudio porque as PANNs são pré-treinadas em conjuntos de dados de áudio em grande escala e são excelentes em tarefas como classificação e rotulagem de áudio.
4. dados multimodais de imagem e texto:
SigLIP ou Unum
Nos últimos anos, surgiram vários modelos de incorporação treinados em uma mistura de dados não estruturados (texto, imagens, áudio ou vídeo). Esses modelos são capazes de capturar a semântica de vários tipos de dados não estruturados simultaneamente no mesmo espaço vetorial.
O modelo multimodal Embedding suporta a pesquisa de imagens usando texto, gerando descrições de texto para imagens ou pesquisando imagens.
OpenAI lançado em 2021 CLIP é o modelo padrão de incorporação. Mas como era difícil de usar, pois exigia que os usuários fizessem o ajuste fino, em 2024, o Google introduziu o modelo SigLIP(Sigmoidal-CLIP). O modelo obteve bom desempenho ao usar o prompt de disparo zero.
Os modelos pequenos de LLM estão se tornando cada vez mais populares atualmente. Isso ocorre porque esses modelos não exigem grandes clusters de nuvem e podem ser executados em laptops. Os modelos menores ocupam menos memória, têm menor latência e são executados mais rapidamente do que os modelos maiores.Unum São fornecidos modelos de mini-Embedding multimodais.
5. dados multimodais de texto, áudio e vídeo
A maioria dos sistemas RAG multimodais de texto para áudio usa LLMs generativos multimodais, que primeiro convertem o som em texto, geram pares som-texto e, em seguida, convertem o texto em vetores de incorporação. Em seguida, você pode usar o RAG para recuperar o texto como de costume. Na última etapa, o texto é mapeado de volta para o áudio.
OpenAI Sussurro pode transcrever a fala para texto. Além disso, a tecnologia Conversão de texto em fala (TTS) Os modelos também podem converter texto em áudio.
O sistema RAG multimodal de texto-vídeo usa uma abordagem semelhante para primeiro mapear o vídeo para texto, convertê-lo em um vetor de incorporação, pesquisar o texto e retornar o vídeo como resultado da pesquisa.
OpenAI Sora O texto pode ser convertido em vídeo. Semelhante ao Dall-e, você fornece avisos de texto enquanto o LLM gera o vídeo. O Sora também pode gerar vídeos a partir de imagens estáticas ou outros vídeos.
O Milvus já integrou o modelo de incorporação convencional, e você está convidado a experimentá-lo:https://milvus.io/docs/embeddings.md
consulta
Tabela de classificação do MTEB: https://huggingface.co/spaces/mteb/leaderboard
Melhores práticas do MTEB: https://huggingface.co/blog/lyon-nlp-group/mteb-leaderboard-best-practices
Pesquisa de imagens semelhantes: https://milvus.io/docs/image_similarity_search.md
Pesquisa de imagem e vídeo: https://milvus.io/docs/video_similarity_search.md
Pesquisas de áudio semelhantes: https://milvus.io/docs/audio_similarity_search.md
Pesquisa de imagens de texto: https://milvus.io/docs/text_image_search.md
2024 SigLIP (sigmoid loss CLIP) Papel: https://arxiv.org/pdf/2401.06167v1
Modelo de incorporação multimodal Unum:
https://github.com/unum-cloud/uform
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados



Nenhum comentário...