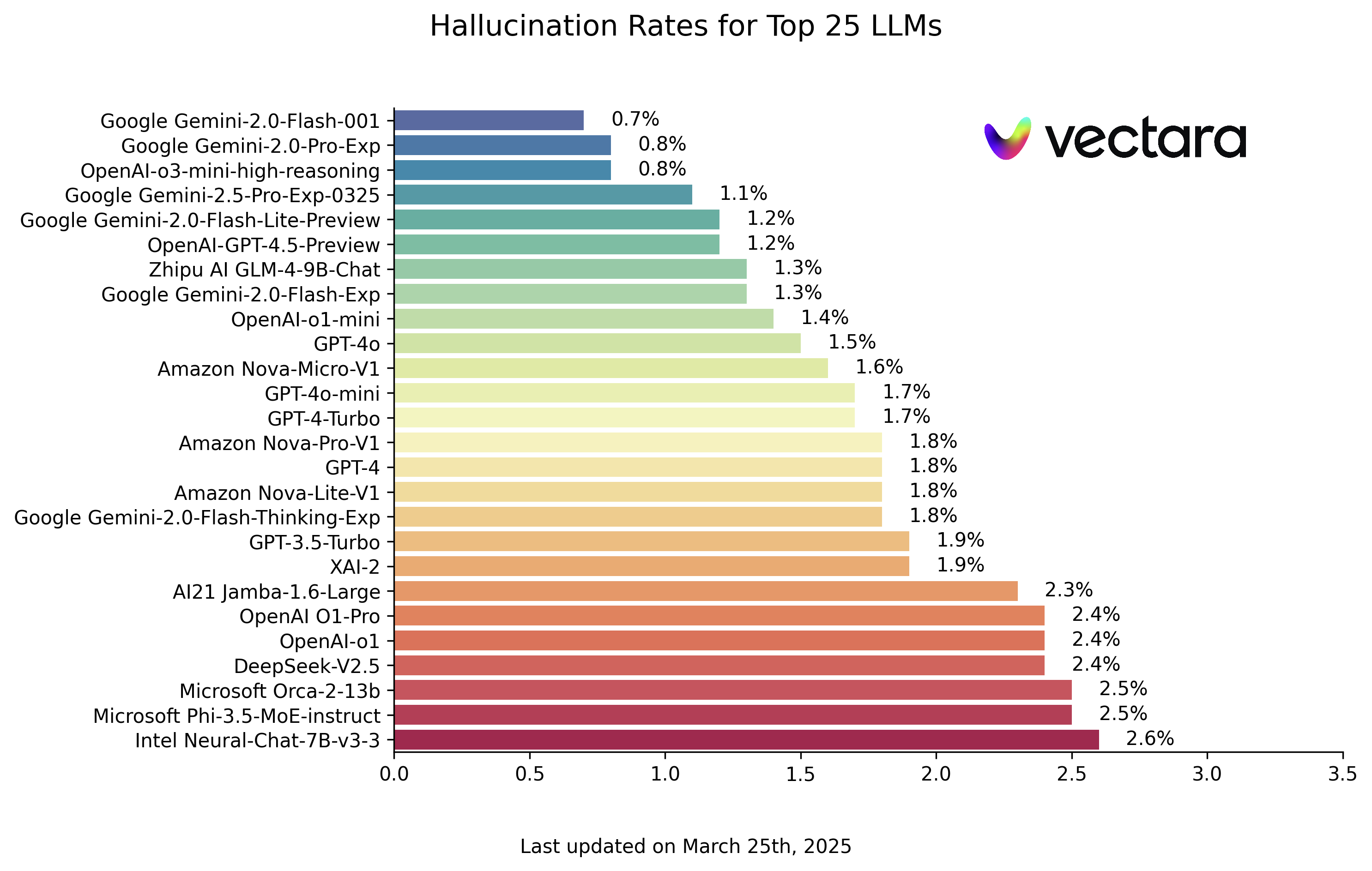
Inventário detalhado de projetos de código aberto de OCR: os 10 principais a não perder em 2025

A tecnologia de OCR é capaz de converter informações textuais de uma imagem em dados de texto editáveis e processáveis. Em termos simples, ela reconhece e extrai texto de imagens.
Em seguida, analisaremos os 10 projetos de código aberto de OCR mais estrelados no GitHub para oferecer a você um guia completo para a escolha de uma ferramenta de OCR.
01 GOT-OCR 2.0: modelo de OCR multimodal de ponta a ponta
GOT-OCR 2.0 é um modelo de OCR multimodal completo de código aberto com um tamanho de modelo de apenas 1,43 GB. Ele não apenas reconhece e extrai texto, mas também processaFórmulas matemáticas, fórmulas moleculares, diagramas, partituras, formas geométricase muitos outros, ampliando consideravelmente o escopo de aplicação da tecnologia OCR.
Características do modelo:
- Suporte multimodal: Além de texto normal, ele pode lidar com uma ampla gama de conteúdo complexo.
- Modelos leves: O tamanho do modelo é de apenas 1,43 GB, o que facilita a implantação.
- Identificação de ponta a ponta: Não há necessidade de procedimentos complexos de pré e pós-processamento.
Vantagens: O GOT-OCR 2.0 tem vantagens óbvias no tratamento de cenários complexos e conteúdos diversificados, e é adequado para cenários de aplicativos que precisam lidar com vários tipos de documentos.
Atualmente, ele tem 7,2 mil estrelas no GitHub!

开源地址:https://github.com/Ucas-HaoranWei/GOT-OCR2.0
02 InternVL: um poderoso modelo multimodal de código aberto
InternVL é um macromodelo multimodal de código aberto desenvolvido pela equipe do OpenGVLab que tem como objetivo fornecer uma aproximação do GPT-4V e do Gêmeos Uma alternativa ao desempenho de modelos comerciais como o Pro.
Embora a InternVL pertença ao grande modelo visual, o cenário de aplicação é mais amplo, como a compreensão de imagens, e não o modelo vertical do campo de OCR, mas pode ser compatível com a extração de OCR do texto do cenário. Há muitos modelos visuais de código aberto excelentes, este artigo não lista todos eles, apenas o InternVL como exemplo.
Características do modelo:
- Recursos multimodais: Oferece suporte a uma ampla gama de tarefas, como compreensão de imagens e questionários visuais.
- Alto desempenho: Aproximação do desempenho dos modelos comerciais.
- Código aberto aberto: Conveniente para os desenvolvedores para desenvolvimento secundário e personalização.
Vantagens: O InternVL, como um macromodelo visual, tem vantagens no processamento de imagens complexas e na compreensão do conteúdo da imagem, além de atender às necessidades básicas do OCR.
Ele recebeu 7,2 mil estrelas até o momento.

开源地址:https://github.com/OpenGVLab/InternVL
03 olmOCR: o especialista em estruturação de documentos PDF
olmOCR é desenvolvido pela AllenAI e se concentra em Linearização de documentos PDFUm kit de ferramentas que converte PDFs com layout complexo em texto estruturado adequado para treinamento em Modelagem de Linguagem Ampla (LLM).
Seu principal objetivo é gerar dados de texto coerentes, lidando com eficiência com problemas de PDF, como texto e gráficos mistos, layout de várias colunas etc., e melhorar a capacidade do LLM de entender documentos em cenários reais.
Detalhes técnicos:
- Análise de layout: Reconhecer com precisão layouts de várias colunas de texto, imagens, tabelas, etc. em PDF.
- Linearização de texto: Converta layouts complexos em sequências de texto lineares adequadas para o processamento do LLM.
- Reorganização do conteúdo: Resolver problemas como cruzamento de página, cruzamento de coluna etc., para garantir a coerência do texto.
Cenários de aplicativos:
- Análise de trabalhos acadêmicos: Extraia rapidamente as principais informações de seu documento.
- Processamento de documentos jurídicos: Extração estruturada de conteúdo de documentos, como contratos, sentenças, etc.
- Análise de demonstrações financeiras: Extração automatizada de dados financeiros e métricas importantes.
A configuração necessária é uma GPU NVIDIA atualizada (testada em RTX 4090, L40S, A100, H100) com pelo menos 20 GB de RAM de GPU e 30 GB de espaço disponível em disco.
Ele recebeu 9,8 mil estrelas até o momento!


开源地址:https://github.com/allenai/olmocr
在线演示:https://olmocr.allenai.org/
04 Zerox: ferramenta de conversão de documentos estruturados orientada por IA
Zerox É uma ferramenta de extração de documentos orientada por IA desenvolvida pela equipe da Omni-AI que converte documentos em PDF, imagem, Docx, etc. em arquivos Markdown estruturados.
Vantagens:
- Não é necessário treinamento: Ao contrário das ferramentas tradicionais de OCR, a Zerox pode lidar com layouts complexos sem precisar treinar o modelo antecipadamente.
- Geração direta de conteúdo estruturado: Implemente o OCR com base em um modelo visual (por exemplo, GPT-4o-mini) e gere conteúdo estruturado diretamente.
- Manter a estrutura lógica: Reconheça o layout colunar de trabalhos acadêmicos, blocos de código em documentos técnicos, formulários de contratos, fórmulas de testes, etc. e gere um Markdown organizado.
- Comparação com o OCR tradicional Zerox: O Zerox omite as etapas tradicionais de análise de layout, redução da estrutura da tabela, etc. e gera resultados de Markdown diretamente.
Atualmente, está recebendo 10,3 mil estrelas!

开源地址:https://github.com/getomni-ai/zerox
体验地址:https://getomni.ai/ocr-demo
05 Surya: reconhecimento de textos multilíngues e de estruturas complexas de documentos
Surya Concentra-se no reconhecimento de textos multilíngues e estruturas complexas de documentos, com especialização especial em reconhecimento de tabelas.
Palavras-chave: detecção de texto em nível de linha, análise de layout (detecção de tabelas, imagens, legendas, etc.), detecção de ordem de leitura, reconhecimento de tabela (detecção de linhas/colunas), LaTeX OCR
Principais recursos:
- Suporte multilíngue: Suporte a mais de 90 idiomas, incluindo scripts complexos, como chinês, japonês e árabe, além dos principais idiomas, como inglês e espanhol, para processamento de documentos em cenários globalizados.
- Otimização do reconhecimento de formas: É capaz de identificar com precisão as linhas, as colunas e a estrutura celular da tabela, inclusive o layout rotativo ou complexo da tabela, com desempenho melhor do que os principais modelos de código aberto atuais (como o Table Transformer).
- Análise de documentos complexos: Ele pode detectar o título, as imagens, os parágrafos e outros elementos no documento e julgar de forma inteligente a ordem de leitura para evitar a confusão do conteúdo de saída.
Exemplo de cenário de aplicativo:
- Digitalização de documentos multilíngues: Contratos multilíngues, relatórios, etc. são gerenciados por empresas multinacionais.
- Digitalização de arquivos históricos: Lidar com documentos históricos que contêm tabelas e layouts complexos.
- Extração de dados científicos: Extração de dados tabulares de artigos acadêmicos.
O Surya é compatível com a operação de CPU/GPU e melhora significativamente a velocidade de reconhecimento por meio de processamento em lote e otimizações de pré-processamento de imagens (por exemplo, denoising, escala de cinza) para as necessidades de digitalização de documentos em nível empresarial.
Atualmente, ele tem 16,8 mil estrelas no GitHub!


开源地址:https://github.com/VikParuchuri/surya
06 OCRmyPDF: adicione uma camada de texto pesquisável a PDFs digitalizados
Essa ferramenta de código aberto, projetada para documentos PDF digitalizados (ou seja, o PDF está cheio de imagens, as imagens no texto não podem ser copiadas) para adicionar uma camada de texto pesquisável e copiável.
Cenários de aplicativos:
- Digitalização de arquivos: Converta documentos digitalizados em papel para PDF pesquisável.
- Acessibilidade: Documentos PDF acessíveis para pessoas com deficiência visual.
- Recuperação de informações: Fácil de encontrar informações em um grande número de documentos digitalizados.
Vantagens:
- Identificação precisa: Suporte para mais de 100 idiomas usando o mecanismo de OCR do Tesseract.
- Otimização de imagens: Corrige automaticamente páginas distorcidas e páginas erradas giradas para melhorar as taxas de reconhecimento.
- Processamento em lote: Processe com eficiência milhares de páginas de documentos com aceleração de CPU de vários núcleos.
O OCRmyPDF tem uma clara vantagem no processamento de PDFs digitalizados, é fácil de instalar e usar e é compatível com Linux, Windows, macOS e Docker, oferecendo uma solução mais conveniente do que outras ferramentas que exigem o processamento manual de documentos digitalizados.
Atualmente, ele recebeu 20,7 mil estrelas no GitHub!
Ao abrir um PDF baseado em imagem, você descobrirá que o texto na imagem não pode ser copiado e pesquisado. O OCRmyPDF pode incorporar a camada de texto de OCR sob a imagem, suportando cópia e pesquisa de alta precisão.

开源地址:https://github.com/ocrmypdf/OCRmyPDF
接入文档:https://ocrmypdf.readthedocs.io/en/latest/
07 Marker: conversão de PDF, imagens e outros documentos em vários formatos
Marcador É uma ferramenta eficiente de conversão de documentos desenvolvida por Vik Paruchuri que pode converter rapidamente PDF, imagens, documentos do Office e formatos EPUB em Markdown, JSON ou HTML.
Vantagens: Marcador Ele se destaca na análise de conteúdo complexo (por exemplo, tabelas, fórmulas matemáticas, blocos de código) com alta precisão e excelente velocidade de processamento, suporta aceleração de GPU e supera serviços de nuvem comparáveis (por exemplo, Llamaparse, Mathpix).
Aplicativos:
- Conversão de artigos acadêmicos: Converta documentos PDF em Markdown para facilitar a edição e a citação.
- Geração de documentação técnica: Converta documentos que contenham códigos e diagramas em um formato HTML fácil de publicar.
- Extração de dados: Extraia dados de tabelas e formulários para o formato JSON para facilitar o processamento subsequente.
O Marker pode recorrer a grandes modelos de linguagem (por exemplo, Gemini, Ollama) para otimizar os resultados, como mesclagem de tabelas entre páginas, formatação de fórmulas e extração de dados de formulários.
Atualmente, ele tem 22,8 mil estrelas no GitHub.

开源地址:https://github.com/vikParuchuri/marker
08 EasyOCR: uma biblioteca de ferramentas de reconhecimento de texto multilíngue
EasyOCR É uma biblioteca de ferramentas de OCR de código aberto desenvolvida pela JaidedAI, que insere uma imagem e retorna o texto extraído, as coordenadas do local correspondente e o nível de confiança.
Características:
- Suporte multilíngue: Suporte para mais de 80 idiomas e vários sistemas de escrita (por exemplo, chinês, latim, árabe).
- Pronto para uso: Fornece modelos pré-treinados para implantação rápida sem treinamento adicional.
- Entrada flexível: Oferece suporte a vários formulários de entrada, como imagens, fluxos de bytes, URLs etc.
- API de simplicidade: Emita conteúdo de texto, posição e confiança por meio de uma API concisa.
- Compatível com CPU/GPU: O ambiente operacional pode ser selecionado com flexibilidade de acordo com as condições do hardware.
Treinamento de modelos: O EasyOCR é baseado na estrutura de aprendizagem profunda do PyTorch e usa uma estrutura de modelo CRNN (Convolutional Recurrent Neural Network) combinada com uma função de perda CTC (Connectionist Temporal Classification) para treinamento.
Cenários de aplicativos:
- Reconhecimento de documentos multilíngues: Ideal para trabalhar com documentos que contêm vários idiomas.
- Reconhecimento de texto de cena natural: Ele pode ser usado para reconhecer texto em cenas naturais, como placas de trânsito e placas de carro.
- OCR móvel: O modelo é leve e adequado para implantação em dispositivos móveis.
O EasyOCR combina a facilidade de desenvolvimento e os requisitos de aplicativos de nível industrial para cenários de OCR, como documentos multilíngues e textos de cenas naturais.
Atualmente, ele tem 26 mil estrelas no GitHub.



开源地址:https://github.com/JaidedAI/EasyOCR
Demo 地址:https://www.jaided.ai/documentai/demo
09 Umi-OCR: software de OCR off-line que se instala e funciona imediatamente
Este é um software de reconhecimento de texto OCR off-line, gratuito e de código aberto, compatível com os sistemas Windows 7+ x64 e Linux x64, sem necessidade de rede, que pode ser baixado e executado localmente.
Palavras-chave: software local, descompactar e executar off-line; OCR de captura de tela; OCR em lote;
Vantagens:
- Execução off-line: Não é necessária conexão com a Internet para proteger a privacidade do usuário.
- Simples de usar: Oferece uma interface gráfica para facilitar a operação.
- Rico em recursos: Suporta OCR de captura de tela, OCR em lote e muitas outras funções.
- Compare isso com outras ferramentas off-line: Apresenta fácil instalação e não há necessidade de configurar o ambiente operacional.
Até o momento, ele ganhou 30,8 mil estrelas.



开源地址:https://github.com/hiroi-sora/Umi-OCR
10 Tesseract: Deuses antigos do campo de OCR
Tesseract é um mecanismo de OCR de código aberto avançado e amplamente usado que converte texto em imagens em texto editável.
Contexto histórico:
- Desenvolvido pela Hewlett-Packard Laboratories entre 1985 e 1994.
- Ele foi portado para o Windows depois de 1996.
- A HP tornou-o de código aberto em 2005.
- Patrocinado pelo Google, ele é um dos sistemas de OCR de código aberto mais conhecidos.
Características técnicas:
- Técnicas de aprendizagem profunda: O reconhecimento de caracteres usando técnicas avançadas de aprendizagem profunda (por exemplo, redes neurais convolucionais) é altamente preciso e tem bom desempenho, especialmente ao lidar com imagens digitalizadas de melhor qualidade.
- Suporte multilíngue: Reconhecimento de texto em mais de 100 idiomas.
Compare-o com outros mecanismos: O Tesseract tem uma longa história, uma comunidade ativa e está bem documentado, mas pode não ser tão bom quanto alguns dos mecanismos de OCR emergentes para lidar com layouts complexos e imagens de baixa qualidade.
Há também uma versão em JavaScript do Tesseract OCR: Tesseract.js, mas, após testes reais, descobriu-se que a versão em JS não é muito compatível com o idioma chinês.
Ele recebeu 65,3 mil estrelas no GitHub até o momento.

开源地址:https://github.com/tesseract-ocr/tesseract
开源地址:https://github.com/naptha/tesseract.js

© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados


Nenhum comentário...