Ilya Sutskever explode na NeurIPS e declara: o pré-treinamento será encerrado, o aperto de dados está no fim

O raciocínio é imprevisível, portanto, temos que começar com sistemas de IA incríveis e imprevisíveis.
Ilya finalmente apareceu e, logo de cara, tem algo incrível a dizer. Na sexta-feira, Ilya Sutskever, ex-cientista-chefe da OpenAI, disse no Global AI Summit que "chegamos ao fim dos dados que podemos obter e não haverá mais nenhum". 
Ilya Sutskever, cofundador e ex-cientista-chefe da OpenAI, ganhou as manchetes quando deixou a empresa em maio deste ano para iniciar seu próprio laboratório de IA, o Safe Superintelligence. Ele se manteve afastado da mídia desde que deixou a OpenAI, mas fez uma rara aparição pública nesta sexta-feira na NeurIPS 2024, uma conferência sobre sistemas de processamento de informações neurais em Vancouver.
"O pré-treinamento como o conhecemos, sem dúvida, chegará ao fim", disse Sutskever no palco.
No campo da inteligência artificial, os modelos de pré-treinamento em grande escala, como o BERT e o GPT, obtiveram grande sucesso nos últimos anos e se tornaram um marco no caminho do progresso tecnológico.
Devido aos objetivos complexos do pré-treinamento e aos enormes parâmetros do modelo, o pré-treinamento em grande escala pode capturar com eficiência o conhecimento de grandes quantidades de dados rotulados e não rotulados. Ao armazenar o conhecimento em parâmetros enormes e ajustá-lo para uma tarefa específica, o rico conhecimento implicitamente codificado nos parâmetros enormes pode beneficiar uma variedade de tarefas posteriores. O consenso na comunidade de IA agora é adotar o pré-treinamento como a espinha dorsal das tarefas posteriores, em vez de aprender modelos do zero. 
No entanto, em sua palestra no NeurIPS, Ilya Sutskever disse que, embora os dados existentes ainda possam impulsionar a IA, o setor está próximo de ficar sem novos dados que possam ser considerados utilizáveis. Ele observou que essa tendência acabará forçando o setor a mudar a forma como os modelos são treinados atualmente.
Sutskever compara a situação com o esgotamento dos combustíveis fósseis: assim como o petróleo é um recurso finito, o mesmo ocorre com o conteúdo gerado por humanos na Internet.
"Atingimos o pico de dados e não há mais dados por vir", disse Sutskever. "Temos que utilizar os dados que estão disponíveis porque só existe uma Internet."
Sutskever prevê que a próxima geração de modelos "exibirá autonomia de forma real". Por outro lado, Agente tornou-se uma palavra da moda em IA.
Além de serem "autônomos", ele também mencionou que os sistemas futuros terão a capacidade de raciocinar. Ao contrário da IA atual, que depende muito da correspondência de padrões (com base no que o modelo já viu antes), os futuros sistemas de IA poderão resolver problemas passo a passo de forma semelhante ao "pensamento".
Sutskever diz que quanto mais raciocínio um sistema consegue fazer, mais "imprevisível" se torna seu comportamento. Ele compara a imprevisibilidade de "sistemas com poder de raciocínio real" ao desempenho da IA avançada no xadrez - "mesmo os melhores jogadores humanos não conseguem prever seus movimentos".
Esses sistemas serão capazes de entender as coisas a partir de dados limitados e não se confundir", disse ele.
Em sua palestra, ele comparou o escalonamento em sistemas de IA com a biologia evolutiva, citando a relação entre as proporções de peso do cérebro e do corpo entre diferentes espécies no estudo. Ele destacou que a maioria dos mamíferos segue um padrão específico de escalonamento, enquanto a família humana (ancestrais humanos) apresenta uma tendência muito diferente de crescimento nas proporções entre cérebro e corpo em uma escala logarítmica.
Sutskever propõe que, assim como a evolução encontrou um novo paradigma de escala para o cérebro científico humano, a IA pode ir além dos métodos de pré-treinamento existentes e descobrir caminhos de escala totalmente novos. Abaixo está o texto completo da palestra de Ilya Sutskever: 
Gostaria de agradecer aos organizadores da conferência por escolherem um artigo para esse prêmio (o artigo Seq2Seq de Ilya Sutskever et al. foi selecionado para o prêmio NeurIPS 2024 Time Check Award). Isso é ótimo. Também gostaria de agradecer aos meus incríveis coautores Oriol Vinyals e Quoc V. Le, que estão bem na sua frente. 

Você tem uma imagem aqui, uma captura de tela. Houve uma palestra semelhante no NIPS 2014 em Montreal há 10 anos. Era uma época muito mais inocente. Aqui aparecemos na foto. A propósito, essa foi a última vez, a foto abaixo é desta vez.
Agora temos mais experiência e, esperamos, estamos um pouco mais sábios. Mas aqui eu gostaria de falar sobre o exercício em si e talvez fazer uma retrospectiva de 10 anos, porque muitas coisas no exercício estavam certas, mas algumas não estavam tão certas. Podemos olhar para trás e ver o que aconteceu e como isso nos levou ao ponto em que estamos hoje. Então, vamos começar a falar sobre o que fizemos. A primeira coisa que faremos é mostrar slides da mesma apresentação de 10 anos atrás. Ela está resumida em três pontos principais. Um modelo autorregressivo treinado em texto, é uma grande rede neural, é um grande conjunto de dados, e é isso.
Então, vamos começar a falar sobre o que fizemos. A primeira coisa que faremos é mostrar slides da mesma apresentação de 10 anos atrás. Ela está resumida em três pontos principais. Um modelo autorregressivo treinado em texto, é uma grande rede neural, é um grande conjunto de dados, e é isso.
Agora vamos nos aprofundar em mais alguns detalhes. 
Aqui está um slide de 10 anos atrás que parece bom, "The Deep Learning Hypothesis" (A hipótese da aprendizagem profunda). O que estamos dizendo aqui é que, se você tiver uma grande rede neural com 10 camadas, ela poderá fazer qualquer coisa que um ser humano possa fazer em uma fração de segundo. Por que enfatizamos "o que os humanos podem fazer em uma fração de segundo"? Por que isso?
Por que enfatizamos "o que os humanos podem fazer em uma fração de segundo"? Por que isso?
Bem, se você acredita no dogma da aprendizagem profunda de que os neurônios artificiais são semelhantes aos neurônios biológicos, ou pelo menos não muito diferentes, e acredita que três neurônios reais são lentos, então os humanos podem processar qualquer coisa rapidamente. Quero dizer, mesmo que haja apenas uma pessoa no mundo. Se uma pessoa no mundo pode fazer algo em uma fração de segundo, então uma rede neural de 10 camadas pode fazer isso, certo?
Em seguida, basta incorporar suas conexões em uma rede neural artificial.
É tudo uma questão de motivação. Tudo o que um ser humano pode fazer em uma fração de segundo, uma rede neural de 10 camadas também pode.
Nós nos concentramos em redes neurais de 10 camadas porque era assim que sabíamos como treinar naquela época e, se de alguma forma conseguíssemos ir além desse número de camadas, poderíamos fazer mais. Mas, naquela época, só podíamos fazer 10 camadas, e é por isso que enfatizamos tudo o que um ser humano poderia fazer em uma fração de segundo.
O outro slide daquele ano ilustra nossa ideia principal de que você pode ser capaz de identificar duas coisas, ou pelo menos uma coisa, você pode ser capaz de identificar que a autorregressão está acontecendo aqui. 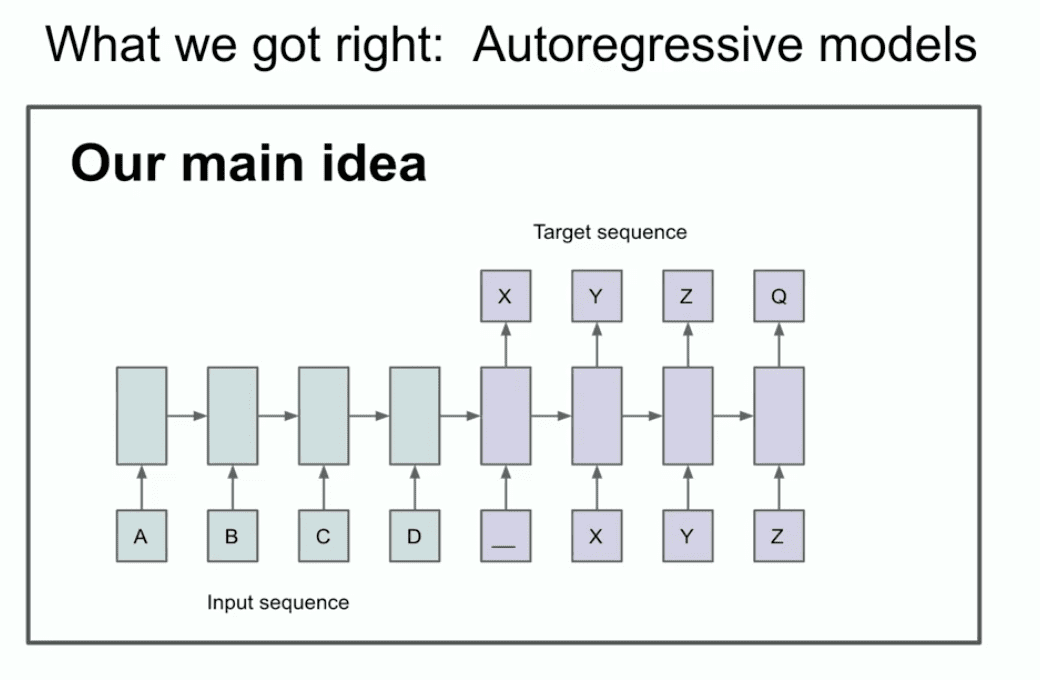
O que diabos ele está dizendo? O que esse slide realmente diz? Esse slide diz que, se você tiver um modelo autorregressivo e ele prever o próximo token bom o suficiente, então ele realmente agarrará, capturará e manterá a distribuição correta de qualquer sequência que aparecer em seguida.
É uma coisa relativamente nova, não é a primeira rede autorregressiva, mas acho que é a primeira rede neural autorregressiva. Nós realmente acreditávamos que, se você a treinasse bem, conseguiria o que quisesse. Em nosso caso, era uma tarefa de tradução automática que parece conservadora agora e parecia muito ousada na época. Agora vou lhes mostrar uma história antiga que muitos de vocês provavelmente nunca viram antes, chamada LSTM.
Para aqueles que não estão familiarizados, o LSTM é o pesquisador de aprendizagem profunda mais pobre do mundo. Transformador O que foi feito antes.
É basicamente uma ResNet, mas girada 90 graus, portanto, é uma LSTM. Portanto, é um LSTM. Um LSTM é como um ResNet um pouco mais complexo. Você pode ver o integrador, que agora é chamado de fluxo residual, mas há alguma multiplicação em andamento. É um pouco complicado, mas é isso que estamos fazendo. Esta é uma ResNet girada em 90 graus. 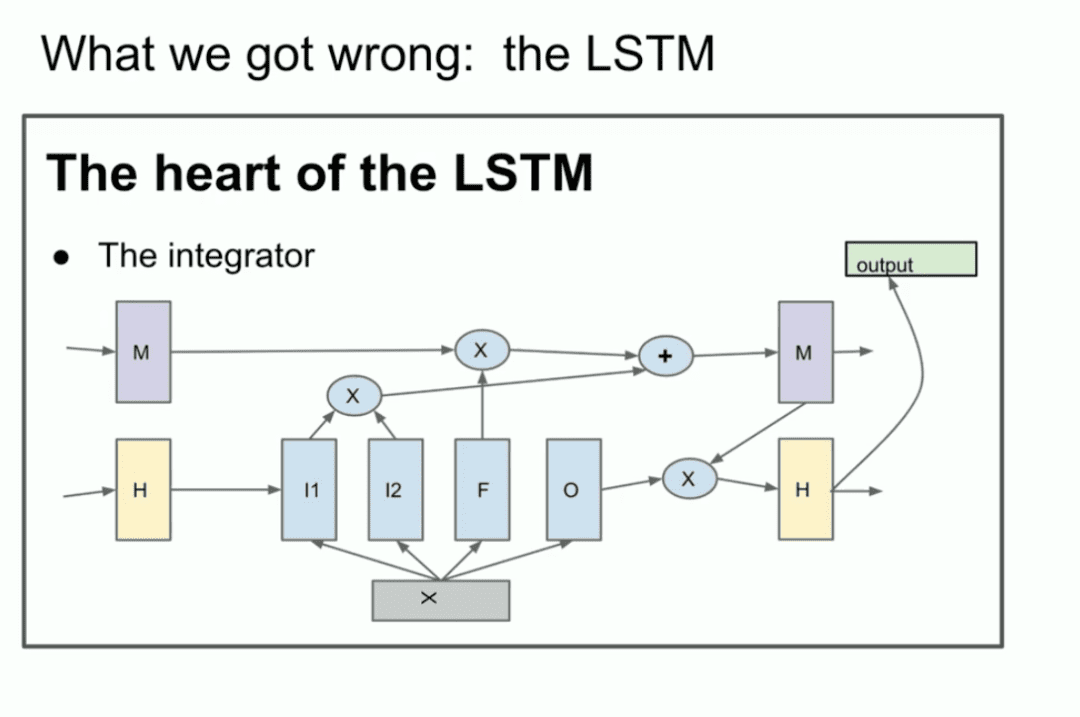
Outro ponto importante que eu queria enfatizar naquela palestra antiga era que usávamos a paralelização, mas não apenas a paralelização.
Usamos pipelining, alocando uma GPU por camada de rede neural, o que, como sabemos agora, não é uma estratégia inteligente, mas não éramos muito inteligentes na época. Então, usamos essa estratégia e conseguimos ser 3,5 vezes mais rápidos com 8 GPUs. 
A conclusão final é o slide mais importante. Ele esclarece o que pode ser o início das Leis de Escala. Se você tiver um conjunto de dados muito grande e treinar uma rede neural muito grande, o sucesso é garantido. Poderíamos argumentar que, se formos generosos, é isso que realmente está acontecendo. 
Agora, quero mencionar outra ideia que acho que realmente resistiu ao teste do tempo. É a ideia central da própria aprendizagem profunda. É a ideia do conexionismo. A ideia é que se você acredita que os neurônios artificiais são como os neurônios biológicos. Se você acredita que um é um pouco parecido com o outro, então isso lhe dá confiança para acreditar em redes neurais de hiperescala. Elas não precisam ser realmente da escala de um cérebro humano, podem ser um pouco menores, mas você pode configurá-las para fazer praticamente tudo o que fazemos.
Mas ainda há uma diferença entre isso e os seres humanos, porque o cérebro humano descobre como se reconfigurar, e estamos usando os melhores algoritmos de aprendizado que temos, o que requer tantos pontos de dados quanto parâmetros. Os seres humanos fazem um trabalho muito melhor. Tudo isso é voltado para o que eu poderia chamar de era pré-treinamento.
Tudo isso é voltado para o que eu poderia chamar de era pré-treinamento.
E depois temos o que chamamos de modelo GPT-2, o modelo GPT-3, as leis de escala, e eu gostaria de fazer uma menção especial ao meu ex-colaborador Alec Radford, bem como a Jared Kaplan e Dario Amodei, cujos esforços tornaram todo esse trabalho possível. 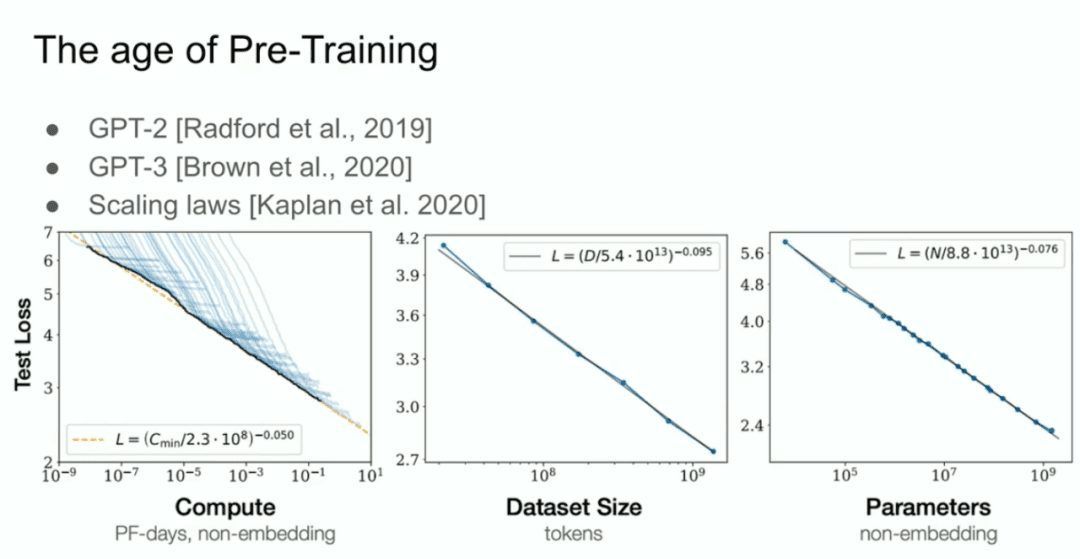 Essa é a era do pré-treinamento, e é isso que está impulsionando todos os avanços, todos os avanços que estamos vendo hoje, redes mega-neurais, redes mega-neurais treinadas em enormes conjuntos de dados.
Essa é a era do pré-treinamento, e é isso que está impulsionando todos os avanços, todos os avanços que estamos vendo hoje, redes mega-neurais, redes mega-neurais treinadas em enormes conjuntos de dados.
Mas a rota de pré-treinamento como a conhecemos, sem dúvida, acabará. Por que acabará? Porque os computadores continuam crescendo por meio de melhor hardware, melhores algoritmos e clusters de lógica, e todas essas coisas continuam aumentando seu poder de computação, e os dados não estão crescendo porque tudo o que temos é uma Internet. 
Pode-se até dizer que os dados são o combustível fóssil da IA. É como se eles tivessem sido criados de uma determinada maneira e, agora que os estamos usando, maximizamos o uso dos dados e não há como melhorar. Nós descobrimos o que precisamos fazer com os dados que temos agora. Ainda vou trabalhar nisso, e isso ainda nos leva muito longe, mas o problema é que só existe uma Internet.
Portanto, aqui vou me aventurar a especular sobre o que acontecerá em seguida. Na verdade, nem preciso especular porque muitos outros também estão especulando, e mencionarei as especulações deles.
- Você já deve ter ouvido a frase "Agente Corporal Inteligente", que é bastante comum e tenho certeza de que, em algum momento, acontecerá algo em que as pessoas sentirão que os corpos inteligentes são o futuro.
- Mais especificamente, mas também de forma um tanto vaga, dados sintéticos. Mas o que significam os dados sintéticos? Descobrir isso é um grande desafio, e tenho certeza de que várias pessoas estão fazendo todo tipo de progresso interessante nesse sentido.
- Há também a computação do tempo de inferência ou, talvez mais recentemente (da OpenAI), o1, o modelo o1 que demonstra mais claramente as pessoas tentando descobrir o que fazer após o pré-treinamento.
Todos esses aspectos são muito bons. 
Gostaria de mencionar outro exemplo da biologia que considero muito legal. Há muitos anos, nesta conferência, também vi uma apresentação em que alguém mostrou este gráfico que mostrava a relação entre o tamanho do corpo e o tamanho do cérebro em mamíferos. Nesse caso, ele era enorme. Naquela palestra, eu me lembro claramente, eles disseram que na biologia tudo é confuso, mas aqui temos um exemplo raro de uma relação muito forte entre o tamanho do corpo de um animal e seu cérebro.
Por acaso, fiquei curioso sobre essa foto.  Então, fui ao Google e pesquisei por imagem.
Então, fui ao Google e pesquisei por imagem.
Nessa imagem, estão listados vários mamíferos, além de não primatas, mas em grande parte iguais, e primitivos. Pelo que sei, os primitivos eram parentes próximos dos humanos em sua evolução, como os neandertais. Por exemplo, o "Homem Energizado". É interessante notar que eles têm diferentes inclinações do índice de proporção entre cérebro e corpo. Muito interessante.
Isso significa que há um caso, há um caso para a biologia descobrir algum tipo de escala diferente. Obviamente, algo é diferente. A propósito, quero enfatizar que esse eixo x é uma escala logarítmica. São 100, 1.000, 10.000, 100.000, novamente em gramas, 1 grama, 10 gramas, 100 gramas, um quilograma. Portanto, é possível que as coisas sejam diferentes.
O que estamos fazendo, o que temos feito até agora em termos de escalonamento, na verdade estamos descobrindo que a forma como escalonamos se torna a prioridade número um. Neste espaço, não há dúvida de que todos que trabalham aqui descobrirão o que fazer. Mas quero falar sobre isso aqui. Quero reservar alguns minutos para fazer uma projeção de longo prazo, algo que todos nós enfrentamos, certo?  Todo o progresso que estamos fazendo é um progresso incrível. Aqueles que trabalharam nesse campo há 10 anos se lembram de como tudo era impotente. Se você entrou para o campo da aprendizagem profunda nos últimos dois anos, provavelmente não consegue se identificar.
Todo o progresso que estamos fazendo é um progresso incrível. Aqueles que trabalharam nesse campo há 10 anos se lembram de como tudo era impotente. Se você entrou para o campo da aprendizagem profunda nos últimos dois anos, provavelmente não consegue se identificar.
Quero falar um pouco sobre "superinteligência", porque é claramente para onde o campo está indo e o que o campo está tentando construir.
Embora os modelos de linguagem tenham recursos incríveis no momento, eles também não são muito confiáveis. Não está claro como conciliar isso, mas, mais cedo ou mais tarde, o objetivo será alcançado: esses sistemas se tornarão inteligências de fato. No momento, esses sistemas não são inteligências perceptuais poderosas e significativas; na verdade, eles estão apenas começando a raciocinar. A propósito, quanto mais um sistema raciocina, mais imprevisível ele se torna.
Estamos acostumados a que toda a aprendizagem profunda seja muito previsível. Porque se você está trabalhando para replicar a intuição humana, voltando a um tempo de reação de 0,1 segundo, que tipo de processamento nosso cérebro faz? Isso é intuição, e demos ao AIS um pouco dessa intuição.
Mas no raciocínio, você vê alguns sinais iniciais de que o raciocínio é imprevisível. O xadrez, por exemplo, é imprevisível para os melhores jogadores humanos. Portanto, teremos de lidar com sistemas de IA muito imprevisíveis. Eles entenderão as coisas com base em dados limitados e não ficarão confusos.
Tudo isso é muito limitador. A propósito, eu não disse como ou quando isso aconteceria e quando todas essas coisas aconteceriam com a "autoconsciência", porque por que a "autoconsciência" não seria útil? Nós mesmos fazemos parte do modelo de nosso próprio mundo.
Quando todas essas coisas se juntarem, teremos sistemas com qualidades e atributos completamente diferentes dos que existem hoje. Eles terão, é claro, recursos incríveis e surpreendentes. Mas o problema de um sistema como esse é que suspeito que ele será muito diferente.
Eu diria que prever o futuro também é certamente impossível. Realmente, todo tipo de coisa é possível. Obrigado a todos vocês.
Após uma rodada de aplausos na conferência da Neurlps, Ilya respondeu a algumas perguntas curtas de vários participantes.
P: Em 2024, você acha que há outras estruturas biológicas relevantes para a cognição humana que valem a pena ser exploradas de maneira semelhante ou há outras áreas de interesse para você?
Ilya:Eu responderia à pergunta da seguinte forma: se você ou alguém tiver uma percepção de um problema específico, como "ei, estamos claramente ignorando que o cérebro está fazendo algo e não estamos fazendo", e isso for possível, então eles devem se aprofundar nessa direção. Pessoalmente, não tenho essa percepção. É claro que isso também depende do nível de abstração da pesquisa em que você está se concentrando. Muitas pessoas aspiram a desenvolver uma IA de inspiração biológica. De certa forma, pode-se argumentar que a IA de inspiração biológica tem sido um grande sucesso - afinal, toda a base da aprendizagem profunda é a IA de inspiração biológica. Basicamente, é apenas "vamos usar neurônios" - isso é tudo que a inspiração biológica é. Níveis mais detalhados e profundos de bioinspiração são mais difíceis de alcançar, mas eu não descartaria essa possibilidade. Acho que pode ser muito valioso se alguém com uma visão especial puder descobrir um novo ângulo. P: Gostaria de fazer uma pergunta sobre autocorreção.
Você mencionou que a inferência pode ser uma das principais direções de desenvolvimento de modelos no futuro e pode ser um recurso diferenciador. Em algumas das sessões de apresentação de pôsteres, vimos que há uma "ilusão" dos modelos atuais. Nosso método atual de analisar se os modelos são alucinantes (corrija-me se eu tiver entendido errado, pois você é o especialista nessa área) baseia-se principalmente em análises estatísticas, por exemplo, determinando se há um desvio da média por algum desvio do desvio padrão. No futuro, você acha que se o modelo tiver a capacidade de raciocinar, ele será capaz de se autocorrigir como a autocorreção e, assim, se tornará um recurso essencial de modelos futuros? Dessa forma, o modelo não teria tantas alucinações porque seria capaz de reconhecer situações em que gera seu próprio conteúdo alucinatório. Essa pode ser uma pergunta mais complexa, mas você acha que os modelos futuros serão capazes de entender e detectar a ocorrência de alucinações por meio do raciocínio?
Ilya:Resposta: Sim.
Acho que a situação que você descreve é muito provável. Embora eu não tenha certeza, sugiro que você verifique, e esse cenário pode já ter ocorrido em alguns modelos iniciais de raciocínio. Mas, a longo prazo, por que não seria possível?
P: Quero dizer, é como o recurso de autocorreção do Microsoft Word, é um recurso essencial.
Ilya:Sim, acho que chamá-lo de "autocorreção" é, na verdade, um pouco exagerado. Quando você menciona "autocorreção", evoca imagens de recursos relativamente simples, mas o conceito vai muito além da autocorreção. De modo geral, porém, a resposta é sim.
PERGUNTADOR: Obrigado. A seguir, o segundo questionador.
P: Olá, Ilya. Gostei muito do final com o misterioso apagão. As IAs vão nos substituir ou são superiores a nós? Elas precisam de direitos? É uma espécie totalmente nova. O Homo sapiens (Homo sapiens) deu origem a essa inteligência, e acho que o pessoal do Reinforcement Learning pode pensar que precisamos de direitos para esses seres.
Tenho uma pergunta não relacionada: como criamos os incentivos certos para que os seres humanos os criem de uma forma que lhes permita desfrutar das mesmas liberdades que nós, Homo sapiens, desfrutamos?
Ilya:Acho que, de certa forma, essas são perguntas sobre as quais as pessoas deveriam pensar e refletir mais. Mas quanto à sua pergunta sobre que tipo de incentivos devemos criar, acho que não posso responder com confiança a uma pergunta como essa. Parece que estamos falando de criar algum tipo de estrutura ou modelo de governança de cima para baixo, mas não tenho muita certeza disso.
O próximo é o último questionador.
P: Olá, Ilya, obrigado pela excelente apresentação. Sou da Universidade de Toronto. Obrigado por todo o trabalho que você fez. Gostaria de perguntar se você acha que os LLMs são capazes de generalizar a inferência multihop fora da distribuição?
Ilya:Ok, essa pergunta pressupõe que a resposta seja "sim" ou "não", mas na verdade não deveria ser respondida dessa forma. Porque precisamos descobrir primeiro: o que significa de fato a generalização fora da distribuição? O que é intra-distributivo? O que é fora da distribuição? Porque esta é uma conversa sobre "teste de tempo". Eu diria que há muito, muito tempo, antes da aprendizagem profunda, as pessoas estavam usando correspondência de strings e n-gramas para fazer tradução automática. Naquela época, as pessoas confiavam em tabelas estatísticas de frases. Você consegue imaginar? Esses métodos tinham dezenas de milhares de linhas de complexidade de código, uma complexidade realmente inimaginável. E, naquela época, a generalização era definida como se o resultado da tradução não fosse literalmente idêntico à representação da frase no conjunto de dados. Agora, podemos dizer: "Meu modelo obteve uma pontuação alta em uma competição de matemática, mas talvez algumas das ideias para essas perguntas de matemática tenham sido discutidas em algum fórum na Internet em algum momento, então o modelo pode ter se lembrado delas". Bem, você poderia argumentar que isso pode estar dentro da distribuição ou pode ser o resultado da memorização. Mas acho que é verdade que nossos padrões de generalização aumentaram drasticamente - pode-se até dizer que de forma significativa e inconcebível.
Portanto, minha resposta é: até certo ponto, os modelos provavelmente não são tão bons em generalização quanto os humanos. Acho que os seres humanos são muito melhores em generalização. Mas, ao mesmo tempo, também é verdade que os modelos de IA são capazes de generalizar fora da distribuição até certo ponto. Espero que essa resposta seja útil para você, mesmo que pareça um pouco redundante.
P: Obrigado.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Publicações relacionadas




Nenhum comentário...