
Seleção ideal de segmentos de texto e reorganização de URLs no DeepSearch/DeepResearch

Se você já leu o último e longo artigo clássico de Jina, "TheProjeto e implementação do DeepSearch/DeepResearch", então vale a pena se aprofundar um pouco mais nos detalhes que podem melhorar drasticamente a qualidade de sua resposta. Desta vez, vamos nos concentrar em dois detalhes:
Extração de segmentos de texto ideais de páginas da Web longasComo usar algoritmos de late-chunking para selecionar os trechos de informações mais relevantes de um longo conteúdo da Web. Rearranjo dos URLs coletadosComo usar o Reranker para permitir que o LLM Agent escolha de forma inteligente qual URL rastrear entre centenas de URLs?
Alguns de vocês devem se lembrar de nossa conclusão na postagem anterior de que "No DeepSearch, o modelo Embeddings só é adequado para a desduplicação de consultas para tarefas como STS (Semantic Textual Similarity), e o Reranker nem sequer estava em nossa implementação original de programação do DeepSearch".
Em retrospecto, os dois tipos de modelos de recall ainda têm seu valor, mas não da maneira como normalmente pensamos neles. Sempre seguimos o princípio "80-20" na pesquisa, e não tentamos conectar modelos para cuidar do valor emocional ou para provar nossa presença no mercado como fornecedor de Embeddings e Reranker. Somos muito 80-20, muito pragmáticos.Pragmático a ponto de nos preocuparmos apenas com as necessidades mais essenciais do sistema de busca.
Assim, após semanas de tentativas e iterações, descobrimos algumas aplicações não convencionais, mas muito eficazes, de Embeddings e Reranker no sistema DeepSearch/DeepResearch. Depois de usar esses métodos, melhoramos significativamente a qualidade do Jina DeepSearch (você está convidado a experimentá-los). Também queremos compartilhar essas experiências com nossos colegas que estão trabalhando juntos nesse campo.
Seleção de segmentos de texto ideais a partir de um texto longo
O problema é o seguinte: com Jina Reader Depois de ler o conteúdo da página da Web, precisamos inseri-lo no contexto do agente como uma parte do conhecimento para que ele raciocine. Embora colocar todo o conteúdo no contexto do LLM de uma só vez seja a maneira menos complicada de fazer isso, já que o Token Em termos de custo e velocidade de geração, essa certamente não é a melhor opção. Na prática, precisamos identificar as partes do conteúdo que são mais relevantes para o problema e adicionar apenas essas partes como conhecimento ao contexto do agente.
Aqui estamos falando de casos em que o conteúdo ainda é muito longo, mesmo depois de ser transformado em Markdown limpo usando o Jina Reader. Por exemplo, em páginas longas como problemas do GitHub, publicações no Reddit, discussões em fóruns e publicações em blogs.
Os métodos de triagem baseados em LLM têm os mesmos problemas de custo e latência, portanto, teremos que descobrir se há alguma solução de modelo pequeno:Precisamos de modelos menores e mais baratos que ainda suportem vários idiomas.Esse é um fator importante, pois não há garantia de que as perguntas ou a documentação estarão sempre em chinês.
De um lado, temos a pergunta (a consulta original ou a pergunta de "informações insuficientes") e, do outro lado, temos muito conteúdo Markdown, grande parte do qual é irrelevante. Precisamos selecionar as partes mais relevantes para a pergunta. É muito parecido com RAG O problema de fragmentação que a comunidade vem tentando resolver desde 2023 - usando o modelo Retriever para recuperar apenas partes relevantes e colocá-las em uma janela de contexto para resumo.
No entanto, há duas diferenças importantes em nossa situação:
Um número finito de blocos de texto em um número finito de documentos.
Supondo que cada bloco tenha cerca de 500 tokens, um documento longo típico da Web tem cerca de 200.000 a 1.000.000 de tokens (99º percentil). Usamos o Jina Reader para rastrear de 4 a 5 URLs por vez, o que gera algumas centenas de blocos de texto. Isso significa centenas de vetores e centenas de semelhanças de cosseno. Isso é facilmente processado na memória com JavaScript, e não há necessidade de um banco de dados de vetores.
Precisamos de blocos contínuos de texto para formar um resumo eficaz do conhecimento.
Não podemos aceitar resumos como [1-2, 6-7, 9, 14, 17, ...] Resumos que consistem em frases dispersas como essa. Um resumo de conhecimento mais útil seria algo como [3-15, 17-24, ...]. que manteria melhor a coerência do texto. Isso tornaria mais fácil para o LLM copiar e citar fontes de conhecimento e também reduziria o número de "ilusões".
O restante são as mesmas ressalvas das quais os desenvolvedores se queixam: cada bloco de texto não pode ser muito longo porque o modelo vetorial não consegue lidar com um contexto muito longo; a fragmentação leva à perda de contexto e faz com que os vetores em cada bloco de texto sejam distribuídos de forma independente e idêntica; e como encontrar os limites ideais que preservem a legibilidade e a semântica? Se você sabe do que estamos falando, é provável que também tenha sido atormentado por esses problemas em suas implementações de RAG.
Mas, resumindo, use jina-embeddings-v3 (usado em uma expressão nominal) Chunking tardioEle resolve os três problemas perfeitamente. A "divisão tardia" preserva as informações contextuais de cada bloco, não é sensível a limites e jina-embeddings-v3 em tarefas de recuperação multilíngue assimétrica. Os leitores interessados podem acompanhar a publicação no blog ou o artigo de Jina para obter detalhes sobre a implementação geral.
🔗 https://arxiv.org/pdf/2409.04701

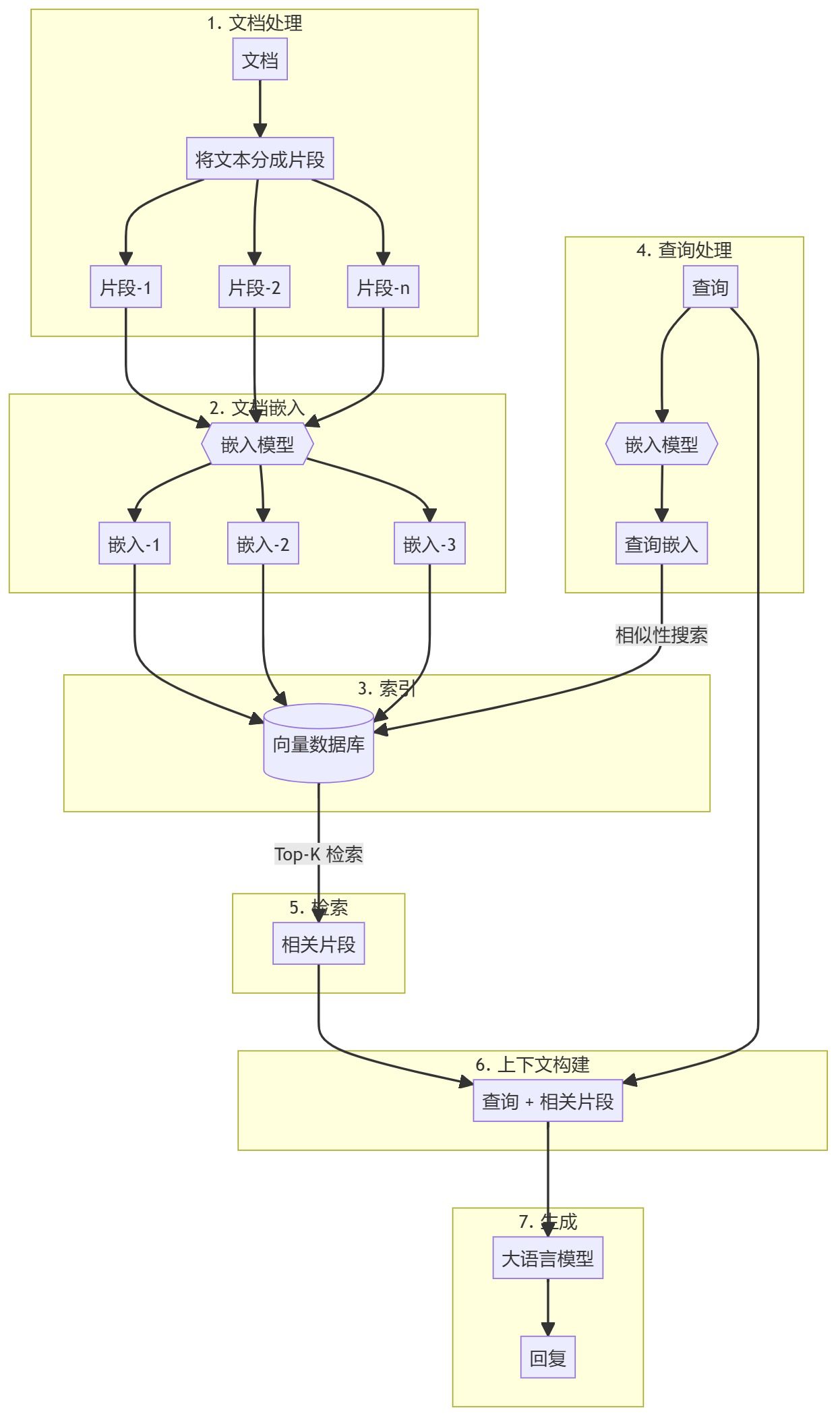
Fluxograma da seleção de fragmentos usando pontuações tardias
Esta figura ilustra o algoritmo de seleção de resumo, que funciona como uma convolução unidimensional (Conv1D). O processo primeiro divide um documento longo em partes de comprimento fixo e, em seguida, usa um algoritmo de seleção de resumo habilitado para particionamento tardio. jina-embeddings-v3 vetorizar esses blocos de texto. Depois de calcular as pontuações de similaridade entre cada bloco e a pergunta, uma janela deslizante se move sobre essas pontuações de similaridade para encontrar a janela com a média mais alta.
Aqui está o código esquemático: usando o particionamento tardio e o agrupamento médio semelhante à "convolução 1D" para selecionar as passagens mais relevantes para o problema.
function cherryPick(question, longContext, options) {
if (longContext.length < options.snippetLength * options.numSnippets)
return longContext;
const chunks = splitIntoChunks(longContext, options.chunkSize);
const chunkEmbeddings = getEmbeddings(chunks, "retrieval.passage");
const questionEmbedding = getEmbeddings([question], "retrieval.query")[0];
const similarities = chunkEmbeddings.map(embed =>
cosineSimilarity(questionEmbedding, embed));
const chunksPerSnippet = Math.ceil(options.snippetLength / options.chunkSize);
const snippets = [];
const similaritiesCopy = [...similarities];
for (let i = 0; i < options.numSnippets; i++) {
let bestStartIndex = 0;
let bestScore = -Infinity;
for (let j = 0; j <= similarities.length - chunksPerSnippet; j++) {
const windowScores = similaritiesCopy.slice(j, j + chunksPerSnippet);
const windowScore = average(windowScores);
if (windowScore > bestScore) {
bestScore = windowScore;
bestStartIndex = j;
}
}
const startIndex = bestStartIndex * options.chunkSize;
const endIndex = Math.min(startIndex + options.snippetLength, longContext.length);
snippets.push(longContext.substring(startIndex, endIndex));
for (let k = bestStartIndex; k < bestStartIndex + chunksPerSnippet; k++)
similaritiesCopy[k] = -Infinity;
}
return snippets.join("\n\n");
}
Ao chamar a API Jina Embeddings, lembre-se de definir o parâmetro task Definido para recuperação, abra o late_chunking(matemática) gênerotruncate Configure-o também como abaixo:
await axios.post(
'https://api.jina.ai/v1/embeddings',
{
model: "jina-embeddings-v3",
task: "retrieval.passage",
late_chunking: true,
input: chunks,
truncate: true
},
{ headers });
Se o problema tiver que ser vetorizado, lembre-se de colocar task trocar (algo) por (algo mais) retrieval.queryEm seguida, desligue-o. late_chunking.
O código de implementação completo pode ser encontrado no GitHub:https://github.com/jina-ai/node-DeepResearch/blob/main/src/tools/jina-latechunk.ts
Classificação de URL para "Ler a seguir"
O problema é o seguinte: em cada processo longo do DeepSearch, você pode coletar vários URLs da página de resultados do mecanismo de busca (SERP) e, toda vez que abrir uma página da Web, poderá descobrir vários links novos ao longo do caminho, mesmo depois de retirar a ênfase, ainda são facilmente algumas centenas de URLs. Da mesma forma, encher os LLMs com todos esses URLs não vai funcionar, é um desperdício de comprimento contextual valioso e, pior, descobrimos que os LLMs estão basicamente escolhendo às cegas. Portanto, tivemos que encontrar uma maneira de orientar o LLM a escolher os URLs com maior probabilidade de conter a resposta.
curl https://r.jina.ai/https://example.com \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
-H "X-Retain-Images: none" \
-H "X-Md-Link-Style: discarded" \
-H "X-Timeout: 20" \
-H "X-With-Links-Summary: all"
Essa é a melhor maneira de configurar o Jina Reader para rastrear uma página no DeepSearch. Ele selecionará todos os links da página, os colocará no campo de links e os excluirá do campo de conteúdo.
Você pode pensar nisso como um "PageRank no contexto", exceto pelo fato de que estamos pontuando centenas de URLs em uma única sessão.
Levamos em conta vários fatores: hora da última atualização, frequência de ocorrência do nome de domínio, estrutura do caminho da página e, o mais importante, relevância semântica para a pergunta, para calcular uma pontuação composta. No entanto, só podemos usar as informações que estão disponíveis antes mesmo de clicarmos no URL.

1. sinais de frequênciaSe um URL aparecer várias vezes em diferentes fontes, ele terá mais peso. Além disso, se um nome de domínio aparecer com frequência nos resultados de pesquisa, os URLs desse domínio receberão pontos extras. Isso ocorre porque, em geral, os domínios populares tendem a conter conteúdo mais confiável.
2. estrutura da rotaAnálise da estrutura de caminho dos URLs: Analisaremos a estrutura de caminho dos URLs para determinar qual conteúdo está agrupado. Se vários URLs pertencerem à mesma hierarquia de caminho, eles terão uma pontuação mais alta; no entanto, quanto mais profundo for o caminho, o bônus de pontuação diminuirá gradualmente.
3. relevância semântica: usamos jina-reranker-v2-base-multilingual para avaliar a relevância semântica da pergunta e as informações textuais (por exemplo, título e resumo) de cada URL, que é um problema típico de reordenação. As informações textuais de cada URL vêm de vários lugares:
API Search Engine Results Page (SERP) Retorna título e resumo (https://s.jina.ai/ Essa interface, com 'X-Respond-With': 'no-content', retorna apenas o título e o resumo, não o conteúdo específico). Texto âncora para URLs na página (usando a interface https://r.jina.ai e configurando 'X-With-Links-Summary': 'all' retorna informações resumidas, ou texto âncora, para todos os links na página).
4. última atualizaçãoAlgumas das consultas do DeepSearch têm altos requisitos de atualidade, portanto, em geral, quanto mais recente for o URL, maior será o valor. No entanto, sem o recurso de indexação em larga escala do Google, é difícil determinar com precisão a hora da última atualização de uma página da Web. Usamos uma combinação dos seguintes sinais para fornecer um registro de data e hora com uma pontuação de confiança para que possamos priorizar a exibição do conteúdo mais recente quando necessário:
Funções de filtragem fornecidas pela API SERP (por exemplo, o parâmetro tbs de s.jina.ai, que permite a filtragem por tempo). Análise das informações do cabeçalho HTTP (como os campos Last-Modified e ETag). Extração de metadados (por exemplo, meta tags e carimbos de data e hora do Schema.org). Reconhecimento de padrões de conteúdo (reconhece datas visíveis em HTML). Métricas para plataformas CMS específicas (por exemplo, WordPress, Drupal, Ghost, etc.)
5. conteúdo restritoAlgumas plataformas de mídia social têm conteúdo restrito ou que requer pagamento para ser acessado. Não há como acessar legalmente esse conteúdo sem fazer login. Portanto, mantemos ativamente uma lista negra desses URLs e domínios problemáticos, diminuindo suas classificações e evitando o desperdício de recursos de computação com esse conteúdo inacessível.
6. diversidade de nomes de domínioÀs vezes, os principais URLs são todos do mesmo domínio, o que pode fazer com que o DeepSearch caia em um "ótimo local", afetando a qualidade dos resultados finais. Conforme mencionado anteriormente, os principais URLs são todos do StackOverflow, portanto, para aumentar a diversidade dos resultados, podemos usar uma estratégia de "explorar e explorar": selecionar os K principais URLs de cada domínio.
A implementação completa do código da classificação de URLs pode ser encontrada em nosso Github: https://github.com/jina-ai/node-DeepResearch/blob/main/src/utils/url-tools.ts#L192
<action-visit>
- Crawl and read full content from URLs, you can get the fulltext, last updated datetime etc of any URL.
- Must check URLs mentioned in <question> if any
- Choose and visit relevant URLs below for more knowledge. higher weight suggests more relevant:
<url-list>
+ weight: 0.20 "https://huggingface.co/docs/datasets/en/loading": "Load - Hugging FaceThis saves time because instead of waiting for the Dataset builder download to time out, Datasets will look directly in the cache. Set the environment ...Some datasets may have more than one version based on Git tags, branches, or commits. Use the revision parameter to specify the dataset version you want to load ..."
+ weight: 0.20 "https://huggingface.co/docs/datasets/en/index": "Datasets - Hugging Face🤗 Datasets is a library for easily accessing and sharing datasets for Audio, Computer Vision, and Natural Language Processing (NLP) tasks. Load a dataset in a ..."
+ weight: 0.17 "https://github.com/huggingface/datasets/issues/7175": "[FSTimeoutError] load_dataset · Issue #7175 · huggingface/datasetsWhen using load_dataset to load HuggingFaceM4/VQAv2, I am getting FSTimeoutError. Error TimeoutError: The above exception was the direct cause of the following ..."
+ weight: 0.15 "https://github.com/huggingface/datasets/issues/6465": "`load_dataset` uses out-of-date cache instead of re-downloading a ...When a dataset is updated on the hub, using load_dataset will load the locally cached dataset instead of re-downloading the updated dataset."
+ weight: 0.12 "https://stackoverflow.com/questions/76923802/hugging-face-http-request-on-data-from-parquet-format-when-the-only-way-to-get-i": "Hugging face HTTP request on data from parquet format when the ...I've had to get the data from their data viewer using the parquet option. But when I try to run it, there is some sort of HTTP error. I've tried downloading ..."
</url-list>
</action-visit>
resumos
Desde que o DeepSearch da Jina foi disponibilizado em 2 de fevereiro de 2025, foram descobertos dois detalhes de engenharia que podem melhorar drasticamente a qualidade.É interessante notar que ambos os detalhes utilizam modelos multilíngues de incorporação e classificação em uma "janela no contexto".Isso não é nada comparado aos enormes índices pré-computados que esses modelos normalmente exigem.
Isso pode ser um prenúncio de que o futuro da tecnologia de busca se moverá em uma direção polarizada. Podemos tomar emprestada a teoria de processos duplos de Kahneman para entender essa tendência:
Pense rápido. Pensamento rápido (grep, BM25, SQL): correspondência de padrões rápida e baseada em regras com computação mínima. pensar lentamente Pensamento lento (LLM): raciocínio abrangente com profundo entendimento contextual, mas com uso intensivo de computação. médiobanda Pensamento médio (Embedding, Reranker et al. Recall Model): tem algum entendimento semântico, melhor do que a simples correspondência de padrões, mas muito menos inferência do que o LLM.
Uma possibilidade é:As arquiteturas de pesquisa em duas camadas estão se tornando cada vez mais popularesO SQL/BM25, leve e eficiente, cuida da entrada da recuperação e, em seguida, alimenta os resultados diretamente no LLM para a recuperação da saída. O valor residual do modelo de camada intermediária é então transferido para tarefas dentro de uma janela de contexto específica: por exemplo, filtragem, eliminação de duplicação, classificação e assim por diante. Nesses cenários, seria ineficiente fazer o raciocínio completo com o LLM.
Mas enfim.Seleção dos principais clipes responder cantando Classificação de URLs Ainda é o aspecto fundamental que afeta diretamente a qualidade de um sistema DeepSearch/DeepResearch. Esperamos que nossas descobertas o ajudem a aprimorar seu próprio sistema.
A expansão da consulta é outro fator importante para determinar a qualidade.Vegetais.Estamos avaliando ativamente uma variedade de abordagens, que vão desde simples reescritas baseadas em Prompt, passando por modelos pequenos, até abordagens baseadas em inferência. Aguarde os resultados de nossas pesquisas subsequentes nesse sentido!
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados


Nenhum comentário...