
A Baichuan Intelligence lança o modelo grande omnimodal Baichuan-Omni-1.5, que supera o GPT-4o Mini em várias medições
No final do ano, o campo de modelos grandes nacionais voltou a divulgar boas notícias. A BCinks Intelligence lançou recentemente uma série de produtos de modelos grandes, seguindo o exemplo daModelo de inferência profunda de cena completa Baichuan-M1-previewresponder cantandoModelo de código aberto para aprimoramento médico Baichuan-M1-14BIsso foi seguido pelo relançamento doModelo modal completo Baichuan-Omni-1.5.
O Baichuan-Omni-1.5 é conhecido como "Big Model Generalist", que marca o progresso significativo do big model doméstico na tecnologia de fusão multimodal. O Baichuan-Omni-1.5 é equipado com excelente capacidade de compreensão e geração omnimodal, que não só é capaz de processar simultaneamenteTexto, imagens, áudio, vídeoe outras informações multimodais, além de mais suporte paraTexto e áudioGeração de conteúdo bimodal.
Ao mesmo tempo, a Baichuan Intelligence também abriu o código-fonteOpenMM-Medicalresponder cantandoOpenAudioBenchOs dois conjuntos de dados de avaliação de alta qualidade têm como objetivo promover o desenvolvimento próspero do ecossistema nacional de tecnologia de modelos totalmente modais. De acordo com os resultados abrangentes da avaliação que foram divulgados, o Baichuan-Omni-1.5 possui vários recursos multimodaisO desempenho geral excede o do GPT-4o MiniA inteligência da BCinks tem se aprofundado cada vez mais, especialmente na área médica.As pontuações de revisão de imagens médicas são uma vantagem significativaIsso demonstra plenamente a força e a determinação da BCinks Intelligence como líder no campo de modelos grandes. Isso demonstra plenamente a Baichuan Intelligence como líder nacional no campo de modelos de grande porte, com grande força e firme determinação em inovação tecnológica e aterrissagem de aplicações no setor.
Endereço do peso do modelo:
Baichuan-Omini-1.5: https://huggingface.co/baichuan-inc/Baichuan-Omni-1d5 https://modelers.cn/models/Baichuan/Baichuan-Omni-1d5
Baichuan-Omini-1.5-Base: https://huggingface.co/baichuan-inc/Baichuan-Omni-1d5-Base https://modelers.cn/models/Baichuan/Baichuan- Omni-1d5-Base
Endereço do GitHub: https://github.com/baichuan-inc/Baichuan-Omni-1.5
Relatório técnico: https://github.com/baichuan-inc/Baichuan-Omni-1.5/blob/main/baichuan_omni_1_5.pdf
01 . Avanço abrangente em recursos multimodais: desempenho excepcional na avaliação de processamento de texto, gráficos, áudio e vídeo
Os destaques de desempenho do Baichuan-Omni-1.5 podem ser resumidos como "Recursos abrangentes e alto desempenho". A característica mais notável do modelo é suade forma abrangenteO recurso de compreensão e geração multimodal, especificamente, não apenas compreende conteúdo multimodal, como texto, imagem, vídeo e áudio, mas também oferece suporte à geração bimodal de texto e áudio.
Em termos de compreensão de imagens, de acordo com os resultados dos testes em benchmarks comuns de avaliação de imagens, como MMBench-dev, TextVQA val etc., o Baichuan-Omni-1.5 tem um desempenho deMelhor que o GPT-4o Mini. De particular interesse é o fato de que, além de seus recursos gerais, o modelo totalmente modal da Baichuan Intelligence é particularmente forte no setor de saúde. EmConjunto de dados de revisão de imagens médicas Avaliações no GMAI-MMBench e no Openmm-Medical mostraram que os recursos do Baichuan-Omni-1.5 na compreensão de imagens médicas foramSupera significativamente o desempenho do GPT-4o Mini.
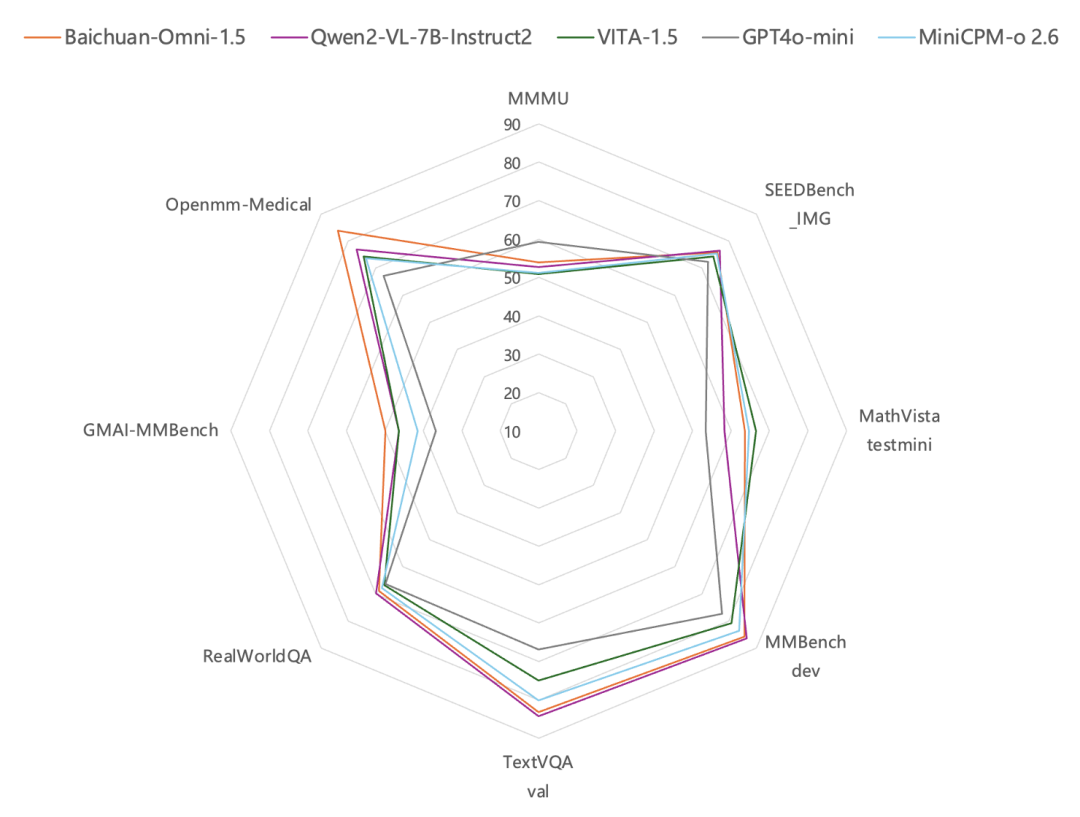
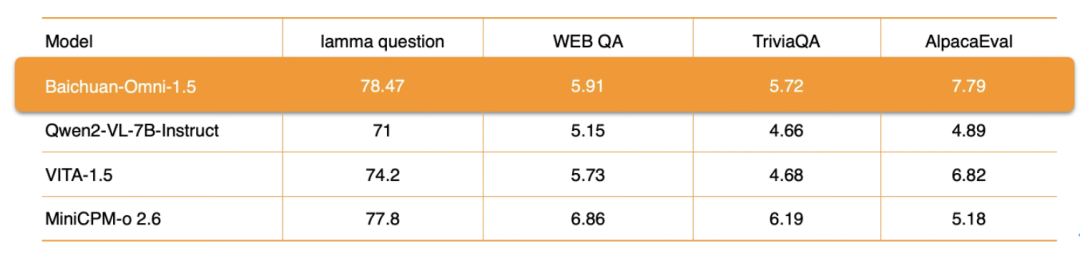
Em termos de processamento de áudio, o Baichuan-Omni-1.5 não só suporta odiálogo multilíngueEle também se baseia em seus recursos de síntese de áudio de ponta a ponta, integrando o ASR (reconhecimento automático de fala) responder cantando TTS (conversão de texto em fala) funções. Além disso, o modelo também oferece suporte à implementação doInteração em tempo real de áudio e vídeo. Em termos de métricas de desempenho específicas, o desempenho geral do Baichuan-Omni-1.5 em conjuntos de dados como lamma question e AlpacaEvalsignificativamente melhor do que Qwen2-VL-2B-Instruct, VITA-1.5 e MiniCPM-o 2.6 são modelos semelhantes.
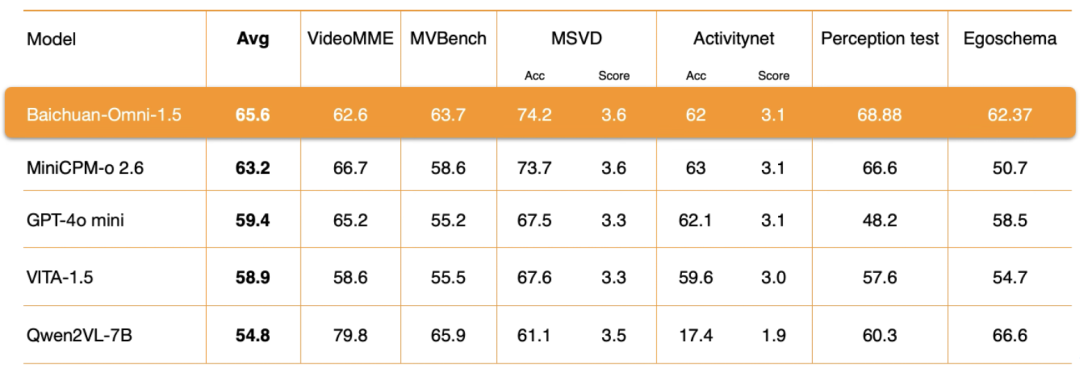
Compreensão de vídeoNo nível do Baichuan-Omni-1.5, a Baichuan Intelligence realizou uma otimização profunda em vários aspectos importantes, como a arquitetura do codificador, a qualidade dos dados de treinamento e a estratégia do método de treinamento. Os resultados da avaliação mostram que sua compreensão de vídeoO desempenho geral também é significativamente superior ao do GPT-4o-mini..
Em resumo, o Baichuan-Omni-1.5 não só supera o GPT4o-mini em termos de capacidade de uso geral como um todo, mas, o que é mais importante, realiza aUnidade de geração e compreensão modal completaque estabelece a base para a criação de sistemas de IA mais generalizados.
Para avançar ainda mais na pesquisa de modelagem multimodal, a Baichuan Intelligence abriu dois conjuntos de dados de avaliação profissional:OpenMM-Medical e OpenAudioBench. Entre eles OpenMM-Medical conjunto de dadosProjetado para avaliar o desempenho do modelo em tarefas médicas multimodaisEle integra dados de 42 conjuntos de dados de imagens médicas disponíveis publicamente, como ACRIMA (imagens de fundo de olho), BioMediTech (imagens de microscopia) e CoronaHack (raios X), em um total de 88.996 imagens.
Endereço para download:
https://huggingface.co/datasets/baichuan-inc/OpenMM_Medical
OpenAudioBench então é umUma plataforma de avaliação abrangente para avaliar com eficiência as habilidades de compreensão de áudio do modeloEle contém 5 subconjuntos de avaliação para compreensão de áudio de ponta a ponta, 4 dos quais são derivados de conjuntos de dados de avaliação pública (Llama Question, WEB QA, TriviaQA, AlpacaEval), e o outro é um conjunto de avaliação de raciocínio lógico de fala autoconstruído pela Baichuan Intelligence, que contém 2.701 dados.
Endereço para download:
https://huggingface.co/datasets/baichuan-inc/OpenAudioBench
A BCinks Intelligence tem participado ativamente e promovido a construção e a prosperidade do ecossistema nacional de código aberto. O conjunto de dados de avaliação de código aberto oferece aos pesquisadores e desenvolvedores uma ferramenta de avaliação unificada e padronizada, que ajuda a realizar uma análise comparativa objetiva e justa do desempenho de diferentes modelos multimodais, promovendo assim o desenvolvimento inovador de algoritmos de compreensão de linguagem de nova geração e arquiteturas de modelos.
02 . Otimização completa da tecnologia: sinergia de dados, arquitetura e processos para superar o gargalo dos modelos multimodais
Desde o desenvolvimento inicial de modelos unimodais até a fusão multimodal e, em seguida, os atuais modelos totalmente modais, essa jornada de evolução tecnológica expandiu um espaço mais amplo para a aplicação básica da tecnologia de IA em vários setores. No entanto, com o desenvolvimento aprofundado da tecnologia de IA, aComo alcançar efetivamente a unidade de compreensão e geração em modelos multimodais tornou-se um ponto importante e uma dificuldade técnica na pesquisa atual no campo da multimodalidade..
Por um lado, a unidade de compreensão e geração é a chave para simular a interação humana natural e obter uma comunicação humano-computador mais natural e eficiente, bem como um importante vínculo com a inteligência artificial geral (AGI); por outro lado, há diferenças significativas entre os diferentes dados modais em termos de representações de recursos, estruturas de dados e conotações semânticas, etc., portanto, como extrair efetivamente os recursos multimodais e obter interação e fusão eficazes de informações multimodais é reconhecido como um dos um dos maiores desafios enfrentados pelo treinamento de modelos totalmente modais.
O lançamento do Baichuan-Omni-1.5 mostra que a Baichuan Intelligence fez um progresso significativo na solução dos problemas técnicos acima e explorou um caminho técnico eficaz. Para superar o problema comum de "degradação intelectual" no treinamento de modelos omnimodais, a equipe de pesquisa da Baichuan realizou uma otimização profunda de todo o processo, desde o design da estrutura do modelo, a otimização da estratégia de treinamento e a construção dos dados de treinamento e, por fim, conseguiu a unificação efetiva da compreensão e da geração.
primeiro emmodelagemPor outro lado, a camada de entrada do Baichuan-Omni-1.5 suporta uma variedade de dados modais, que são alimentados no modelo de linguagem em larga escala para processamento por meio do codificador/tokenizador correspondente; na camada de saída, o modelo adota um design de saída intercalado de texto e áudio, que pode gerar simultaneamente conteúdo de texto e áudio por meio do Tokenizador de Texto e do Decodificador de Áudio. Na camada de saída, o modelo adota um design de saída intercalada de texto e áudio, por meio do Tokenizador de Texto e do Decodificador de Áudio, que podem gerar simultaneamente as modalidades de texto e áudio. O Tokenizer de áudio é baseado no modelo de tradução e reconhecimento de fala de código aberto OpenAI. Sussurro O treinamento incremental é realizado para fornecer extração semântica avançada e reconstrução de áudio de alta fidelidade. Para permitir que o modelo lide com imagens de diferentes resoluções, o Baichuan-Omni-1.5 apresenta o modelo NaViT, que suporta entradas de imagens com resolução de até 4K e inferência de várias imagens, garantindo assim que o modelo possa capturar totalmente as informações da imagem e compreender com precisão o conteúdo da imagem.
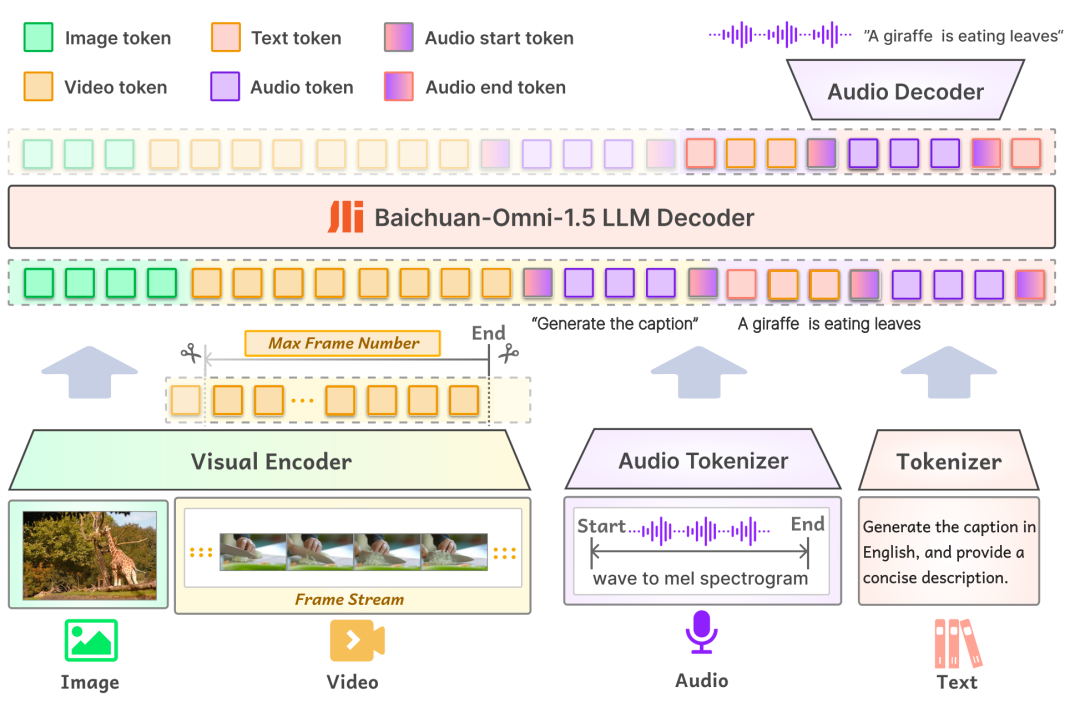
Em segundo lugar, emNível de dadosA BCI construiu um enorme banco de dados com 340 milhões de dados de imagem/vídeo-texto de alta qualidade e quase 1 milhão de horas de dados de áudio, dos quais 17 milhões de dados totalmente modais foram selecionados para a fase SFT (ajuste fino supervisionado) do modelo. Diferentemente da composição de dados dos modelos tradicionais, o treinamento de modelos omnimodais exige não apenas um grande tamanho de dados, mas também uma diversidade de tipos de dados e intermodalidade. No mundo real, as informações geralmente são apresentadas como uma fusão de várias modalidades, e os dados de diferentes modalidades contêm informações complementares, e a fusão eficaz de dados multimodais ajuda o modelo a aprender padrões e leis mais gerais, melhorando assim a capacidade de generalização do modelo. Esse é um dos principais elementos na criação de modelos totalmente modais de alto desempenho.
Para aprimorar a capacidade de compreensão multimodal do modelo, a Baichuan Intelligence criou dados intercalados de áudio-visual-texto de alta qualidade e treinou o modelo com alinhamento usando 16 milhões de dados gráficos, 300.000 dados de texto simples, 400.000 dados de áudio, bem como os dados multimodais mencionados acima. Além disso, para permitir que o modelo execute simultaneamente diversas tarefas de áudio, como ASR, TTS, comutação de timbre e Q&A de ponta a ponta de áudio, a equipe de pesquisa também criou amostras de dados especificamente relacionadas a essas tarefas nos dados alinhados.
O terceiro ponto-chave da tecnologia éProcesso de treinamentoO projeto ideal do modelo é o elo principal para garantir que os dados de alta qualidade possam melhorar efetivamente o desempenho do modelo. O BCinks Intelligence adota um esquema de treinamento em vários estágios nas fases de pré-treinamento e SFT para melhorar de forma abrangente o efeito do modelo. O processo de treinamento é dividido em quatro fases: a primeira fase é baseada no treinamento de dados gráficos; a segunda fase adiciona dados de áudio para pré-treinamento; a terceira fase introduz dados de vídeo para treinamento; e a última fase é a fase de alinhamento multimodal, que, em última análise, permite que o modelo tenha a capacidade de compreender de forma abrangente o conteúdo multimodal.
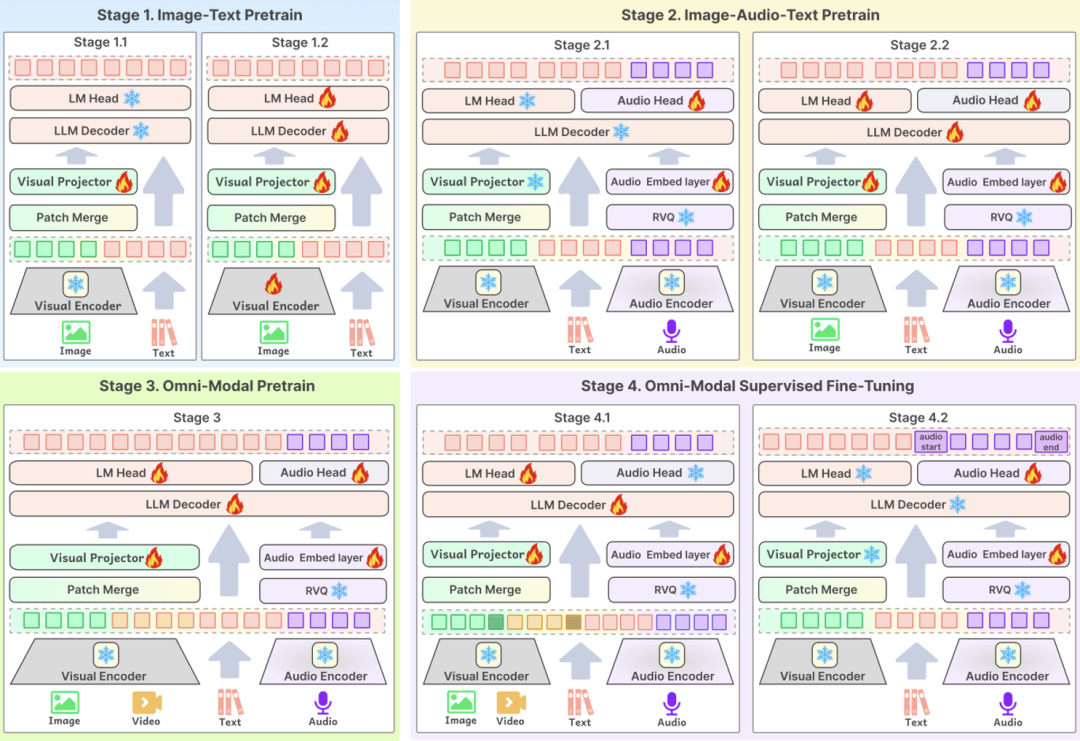
Com base na otimização técnica completa acima, a capacidade geral do Baichuan-Omni-1.5 foi significativamente aprimorada em comparação com o modelo tradicional de linguagem grande monomodal ou o modelo multimodal. O lançamento do Baichuan-Omni-1.5 não é apenas mais um marco importante na pesquisa e no desenvolvimento tecnológico da Baichuan Intelligence, mas também significa que o centro de desenvolvimento da IA está acelerando desde o aprimoramento da capacidade básica do modelo até a aplicação prática.
Anteriormente, o aprimoramento da capacidade do grande modelo se concentrava principalmente em recursos básicos, como compreensão de idiomas e reconhecimento de imagens, enquanto a poderosa capacidade de fusão multimodal do Baichuan-Omni-1.5 ajudará a tecnologia a obter uma integração mais próxima com cenários de aplicativos do mundo real. Ao aprimorar os recursos abrangentes do modelo no processamento de informações multimodais, como linguagem, visão, áudio, etc., o Baichuan-Omni-1.5 é capaz de responder com eficácia a tarefas de aplicação prática mais complexas e diversificadas. Por exemplo, no setor médico, os poderosos recursos de compreensão e geração do modelo omnimodal podem ser usados para auxiliar os médicos no diagnóstico de doenças, melhorando a precisão e a eficiência do diagnóstico, o que é de grande valor de exploração na promoção da aplicação aprofundada da tecnologia de IA no campo médico. Olhando para o futuro, o lançamento do Baichuan-Omni-1.5 pode ser o início da aplicação da tecnologia de IA nas áreas médica e de saúde na era da AGI, e temos motivos para esperar que a IA desempenhe um papel maior na área médica e em outras áreas em um futuro próximo, mudando profundamente nossas vidas.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados



Nenhum comentário...