Concurso de assistente de pesquisa de IA: análise aprofundada e guia de seleção de cinco ferramentas principais

A ascensão dos assistentes de pesquisa de IA: quem realmente pode ajudá-lo a fazer sua lição de casa?
A pesquisa na era da informação muitas vezes significa lidar com grandes quantidades de dados. No passado, os pesquisadores precisavam pesquisar, filtrar e organizar manualmente as informações antes de fornecer o conteúdo principal a pessoas como ChatGPT Esses grandes modelos de linguagem são analisados. Mas com o lançamento do recurso Deep Research da OpenAI, as coisas estão começando a mudar. Essas novas ferramentas de IA prometem automatizar todo o processo de pesquisa: o usuário simplesmente faz uma pergunta, e a IA pesquisa autonomamente na Web, analisa os dados e gera um relatório com citações. Isso geralmente é conduzido por modelos avançados de linguagem grande, como o o3 da OpenAI, que não apenas utiliza conhecimento pré-treinado, mas também adquire proativamente informações atualizadas e executa raciocínio em várias etapas.
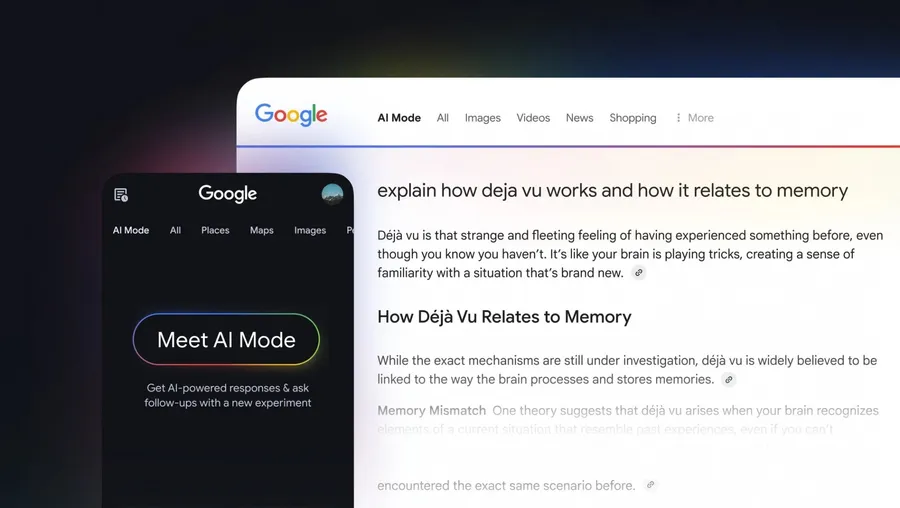
Desde março, várias empresas lançaram suas próprias ferramentas de pesquisa automatizada ou agentes de IA (Agents), que geralmente são chamados de "assistentes de pesquisa de IA" ou ferramentas de "pesquisa profunda". O conceito central dessas ferramentas é semelhante: aproveitar os poderosos recursos de modelagem de IA, combinados com a pesquisa na Web, para realizar tarefas de pesquisa de forma autônoma e fornecer resultados.

Este artigo analisa alguns desses produtos altamente conceituados no mercado, com o objetivo de explorar suas diferenças de desempenho, limites de capacidade e os melhores cenários para cada um por meio de um teste real. As ferramentas envolvidas nessa comparação incluem:
- Pesquisa profunda Gemini: com base no Gêmeos Série de modelos que enfatizam a capacidade de sintetizar e analisar informações.
- Grok 3 Pesquisa profundaUso de xAIs Grok 3 Modelo projetado para executar tarefas de forma independente, possivelmente com um foco maior em informações em tempo real.
- Manus: um sistema que oferece suporte a uma ampla variedade de modelos de IA (por exemplo Antrópica (usado em uma expressão nominal) Claude e Qwen da Ali) que são conhecidas por executar tarefas em várias etapas.
- Pesquisa Mita AI ShallowCombinando seu modelo R1 com uma desmontagem de estrutura lógica e usando seu próprio modelo para realizar pesquisa e integração na Web.
- Zhipu AutoGLMInterface gráfica do usuário (GUI): Com base no grande modelo de linguagem da Zhipu AI, ele controla de forma autônoma os dispositivos digitais para coleta e processamento de informações, simulando as operações do usuário por meio de uma interface gráfica do usuário (GUI).
Para entender o desempenho real dessas ferramentas, apresentamos a mesma tarefa de pesquisa relativamente complexa para todos os cinco produtos.
Testes comparativos: geração de estudos de modelos de IA
Requisitos da missão:
Entregue um trabalho de pesquisa de aproximadamente 5.000 palavras sobre modelagem de IA com base no seguinte esboço:
- Visão geral dos modelos contemporâneos de linguagem de grande porte (por exemplo, família GPT, Claude, LLaMA, DeepSeek, etc.)
- Comparação das características e dos cenários de aplicação de cada modelo
- Análise dos limites e limitações dos recursos do modelo
- Estratégias de seleção de modelos de código aberto versus fechado
- Tutorial básico da API de modelo
- Uma explicação concisa dos princípios da tecnologia de grandes modelos
Implementação:
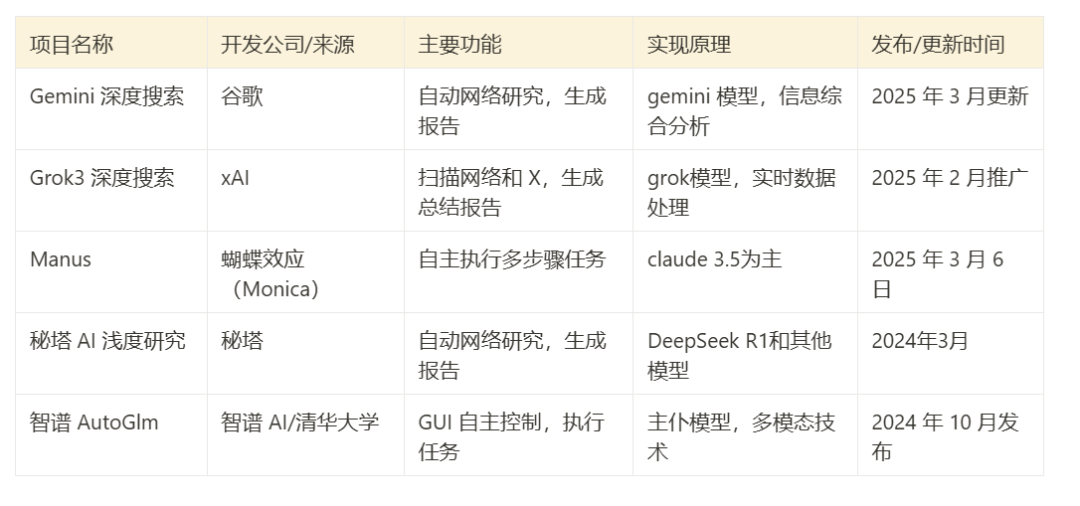
- Gemini Deep Search: leva 8 minutos para pesquisar mais de 300 páginas da Web.
- Grok 3 Deep Search: levou 6 minutos para pesquisar mais de 160 páginas da Web.
- Manus: levou 21 minutos e relatou 8 subtarefas realizadas.
- Mita AI Shallow Research: 7 minutos para pesquisar mais de 300 páginas da Web.
- Zhipu AutoGLM: Levou 16 minutos para pesquisar 71 páginas da Web.
Observações: O tempo de espera e o volume de pesquisa são apenas dados de referência para este teste, e o desempenho real pode variar dependendo da complexidade da tarefa, das condições da rede e da carga do servidor.
Resumo das respostas para cada ferramenta:

(As imagens mostram algumas das capturas de tela ou resumos dos relatórios gerados por cada ferramenta)
Avaliação independente: revisão rigorosa da Claude 3.7
A fim de obter uma perspectiva relativamente objetiva de terceiros, enviamos os cinco relatórios gerados ao modelo Claude 3.7 da Anthropic para avaliação. Abaixo está um resumo da avaliação de cada relatório feita pelo Claude 3.7:
Zhipu AutoGLM
O relatório tenta imitar o formato de um artigo acadêmico citando 71 referências, mas isso é bastante vazio. A linguagem é excessivamente acadêmica, como se o relatório estivesse usando retórica para encobrir a falta de substância. A análise dos pontos fortes e fracos do modelo é como a repetição de uma descrição de produto e carece de profundidade de percepção.
Manus
O relatório vai para o outro extremo, simplificando excessivamente questões técnicas complexas em nome de "para formuladores de políticas" e transformando análises aprofundadas em uma cópia superficial de marketing. Como um livro infantil sobre física quântica, ele não é aprofundado nem preciso.
Pesquisa profunda Gemini
O relatório adota um estilo de redação acadêmico, mas as aspas extensas interferem no fluxo da leitura. Ele é longo e ocupa muito espaço explicando conceitos simples sem acrescentar informações substanciais. Alegando ser destinado a pessoas não técnicas, o relatório ainda está repleto de jargões inexplicáveis e não cumpre seus objetivos.
Grok 3 Pesquisa profunda
A disponibilidade de versões concisas e detalhadas é um recurso, mas também expõe problemas de consistência no conteúdo. A versão concisa é excessivamente simplificada, e algumas das projeções na versão detalhada (por exemplo, para 2025) são um tanto especulativas, pois carecem de uma base suficiente para argumentação e das suposições necessárias para serem declaradas.
Pesquisa Mita AI Shallow
O uso extensivo de tabelas para estruturar as informações melhora a eficiência da aquisição de informações, mas a dependência excessiva de tabelas e delimitadores leva a uma apresentação mecanizada do conteúdo que carece de coerência e profundidade narrativa. As explicações técnicas não estão suficientemente vinculadas a cenários de aplicação prática, e as análises de custos comerciais carecem de considerações diferenciadas para empresas de diferentes tamanhos, e as recomendações parecem ser do tipo "tamanho único".
Observações gerais sobre a Claude 3.7:
Todos esses cinco relatórios tentam usar diferentes "embalagens" para encobrir as deficiências do conteúdo. Independentemente de serem acadêmicos, comerciais ou técnicos, eles parecem não ter tocado no ponto principal: compreensão profunda da natureza da tecnologia e pensamento profundo sobre aplicações práticas. Por exemplo, o relatório DeepSeek A atenção excessiva pode refletir a busca geral do setor por novas tecnologias, enquanto a subestimação de questões importantes, como privacidade de dados e conformidade ética, revela as limitações das perspectivas analíticas. Um bom relatório de pesquisa tecnológica deve fornecer percepções e análises pragmáticas, e não jogos de palavras. De acordo com esse padrão, todos os cinco relatórios têm espaço para melhorias.
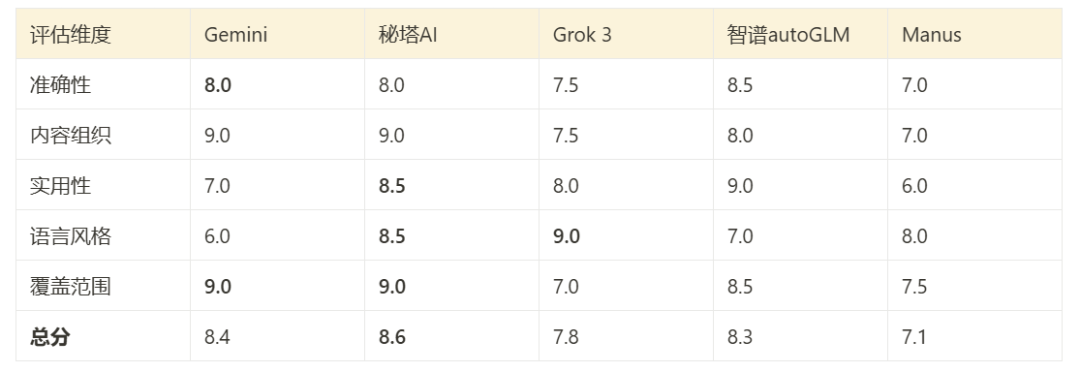
Desempenho geral e pontuação
Com base na avaliação da Cláusula 3.7 e em uma análise direta do conteúdo do relatório, é possível fazer uma avaliação abrangente do desempenho das ferramentas nesse teste:
(A imagem mostra um gráfico de pontuação abrangente com base nos resultados do teste)
- Pesquisa profunda GeminiConteúdo mais bem organizado, ampla cobertura e suporte multilíngue são seus pontos fortes.
- Pesquisa Mita AI ShallowDesempenho: O desempenho é abrangente e equilibrado, com uma boa combinação entre profundidade técnica e facilidade de leitura.
- Grok 3 Pesquisa profundaEstilo de linguagem flexível (versão dupla) e forte orientação pragmática.
- Zhipu AutoGLMConteúdo técnico: O conteúdo técnico é altamente preciso, mas a legibilidade é limitada para não especialistas.
- ManusRelatório: O relatório é conciso e fácil de entender, mas à custa da profundidade da análise.
Como escolher: sugestões para uso em diferentes cenários
Com base nesse teste e nas características de cada ferramenta, aqui estão algumas sugestões para a seleção:
Visão geral dos recursos de pesquisa:
- Pesquisa profunda GeminiPesquisa: a pesquisa é ampla e boa para integrar recursos multilíngues globais, mas pode não ser tão boa quanto os produtos localizados para entender o conteúdo chinês em profundidade.
- Grok 3 Pesquisa profundaTempo real: altamente em tempo real, especialmente em informações comerciais e notícias, mas com profundidade relativamente fraca de conteúdo técnico.
- Zhipu AutoGLMAs referências citadas são de alta qualidade, com compreensão profunda dos conceitos técnicos, mas a pesquisa é relativamente focada.
- Pesquisa Mita AI ShallowIntegração forte de informações em inglês e chinês, cobertura mais abrangente de áreas de especialização e extração precisa de informações estruturadas.
- Manus(Este teste se concentrou na geração de relatórios e seus recursos de pesquisa não foram totalmente demonstrados, mas a plataforma foi projetada para dar suporte à integração de informações de várias fontes e fluxos de trabalho complexos).
Classificação preliminar das habilidades de busca e pesquisa (com base nesse teste):
- Pesquisa Mita AI ShallowDesempenho excepcional em pesquisa profunda em áreas especializadas, processamento bilíngue em inglês e chinês.
- Pesquisa profunda GeminiA cobertura mais versátil e abrangente de recursos globais.
- Zhipu AutoGLMVantagens no manuseio da literatura técnica chinesa e profundo entendimento.
- Grok 3 Pesquisa profunda: Líder no acesso a informações e notícias de negócios em tempo real.
- ManusO ponto forte pode estar na flexibilidade da execução de tarefas e nas invocações de vários modelos, em vez da classificação de pesquisa pura.
Recomendações baseadas em cenários:
- pesquisa acadêmica: A prioridade foi dada ao Zhipu AutoGLM (alta qualidade das referências), seguido pelo Mita AI (cobertura de domínio especializado).
- Análise de negóciosA prioridade foi dada ao Grok 3 (informações comerciais em tempo real), seguido pelo Gemini (visão global).
- desenvolvimento de tecnologia: A prioridade é dada ao Mita AI (compreensão de documentos, extração estruturada), seguido pelo Zhipu AutoGLM (profundidade técnica).
- Acesso a informações diárias/pesquisa geralA prioridade é dada ao Gemini (ampla cobertura), seguido pelo Grok 3 (pontualidade).
- Pesquisa aprofundada de conteúdo chinêsPrioridade: A prioridade é dada ao Zhipu AutoGLM ou ao Mita AI, que têm uma compreensão superior do idioma nativo e do contexto.
Dica importante:
- validação cruzadaPara informações críticas ou decisões importantes, recomenda-se enfaticamente a validação comparativa usando pelo menos duas ferramentas diferentes para garantir a precisão e a integridade das informações.
- Correspondência de tarefas: Não existe uma ferramenta única para todos os casos. O produto a ser escolhido depende muito da tarefa de pesquisa específica, do tipo de informação necessária (em tempo real ou em profundidade, técnica ou comercial) e dos requisitos de formato e profundidade do relatório.
- Limitações do testeEssa comparação se baseia apenas em uma única tarefa. Como Manus As vantagens de uma ferramenta como essa, que enfatiza o fluxo de tarefas e os recursos de fornecimento em vários formatos, podem não ser totalmente percebidas até que outros tipos de tarefas sejam executados. Além disso, a interface do usuário, o custo e os recursos de integração de API também são fatores a serem considerados na seleção real.
Essas ferramentas de assistente de pesquisa de IA representam, sem dúvida, tendências futuras na forma como as informações são acessadas e analisadas. Embora cada uma tenha seus próprios pontos fortes e fracos, elas estão evoluindo em um ritmo acelerado e merecem atenção contínua. Escolher as ferramentas certas e aprender a usá-las com eficiência aprimorará muito a pesquisa e a tomada de decisões.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados




Nenhum comentário...