450 para treinar um 'o1-preview'? UC Berkeley abre o modelo de inferência de 32B Sky-T1, a comunidade de IA está em polvorosa
Um preço de US$ 450 não parece muito em um primeiro momento. Mas e se esse for o custo total do treinamento de um modelo de inferência de 32B?
Sim, à medida que chegamos a 2025, os modelos de inferência estão se tornando mais fáceis de desenvolver, e o custo está diminuindo rapidamente para níveis que não poderíamos imaginar antes.
Recentemente, a NovaSky, uma equipe de pesquisa do Sky Computing Lab da Universidade da Califórnia, em Berkeley, lançou o Sky-T1-32B-Preview. É interessante notar que a equipe afirma que "o Sky-T1-32B-Preview custa menos de US$ 450 para ser treinado, o que sugere que é possível replicar recursos de raciocínio de alto nível de forma econômica e eficiente".

- Página inicial do projeto: https://novasky-ai.github.io/posts/sky-t1/
- Endereço de código aberto: https://huggingface.co/NovaSky-AI/Sky-T1-32B-Preview
De acordo com informações oficiais, esse modelo de inferência correspondeu a uma versão anterior do OpenAI o1 em vários benchmarks importantes.

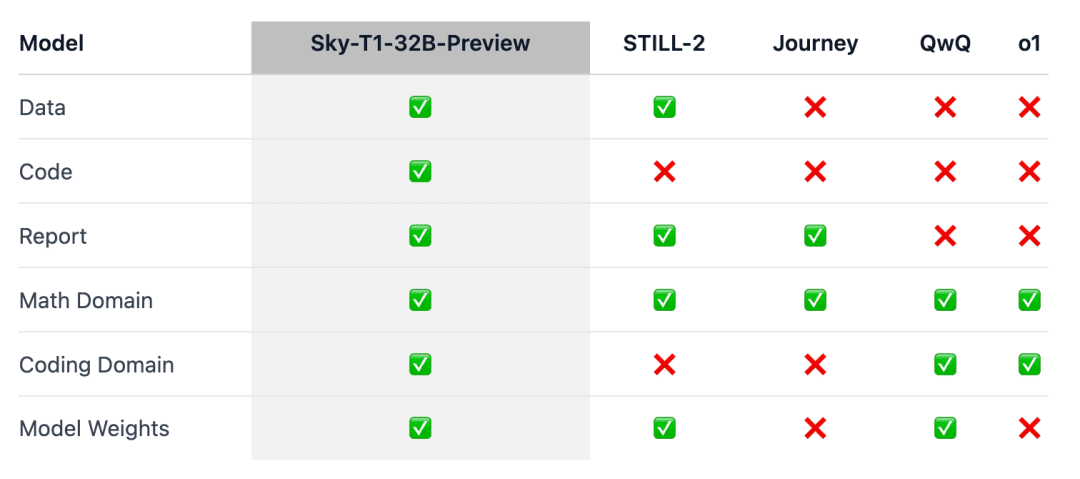
A questão é que o Sky-T1 parece ser o primeiro modelo de inferência verdadeiramente de código aberto, pois a equipe lançou o conjunto de dados de treinamento, bem como o código de treinamento necessário para que qualquer pessoa possa replicá-lo do zero.
As pessoas exclamaram: "Que contribuição incrível de dados, códigos e pesos de modelos".
Não faz muito tempo, o preço do treinamento de um modelo com desempenho equivalente geralmente chegava a milhões de dólares. Dados de treinamento sintéticos ou dados de treinamento gerados por outros modelos permitiram uma redução significativa no custo.
Anteriormente, uma empresa de IA, a Writer, lançou o Palmyra X 004, que foi treinado quase inteiramente em dados sintéticos e custou apenas US$ 700.000 para ser desenvolvido.
Imagine executar esse programa no supercomputador Nvidia Project Digits AI, que custa US$ 3.000 (barato para um supercomputador) e pode executar modelos com até 200 bilhões de parâmetros. Em um futuro próximo, os modelos com menos de 1 trilhão de parâmetros serão executados localmente por indivíduos.
A evolução da tecnologia de grandes modelos em 2025 está se acelerando, e esse é um sentimento muito forte.
Visão geral do modelo
O raciocínio o1 e Gêmeos 2.0 Modelos como o flash thinking resolveram tarefas complexas e fizeram outros avanços ao gerar longas cadeias internas de pensamento. No entanto, os detalhes técnicos e os pesos dos modelos não estão disponíveis, o que representa uma barreira para o envolvimento da comunidade acadêmica e de código aberto.
Para isso, houve alguns resultados notáveis no campo da matemática para o treinamento de modelos de inferência com ponderação aberta, como o Still-2 e o Journey. Enquanto isso, a equipe da NovaSky na Universidade da Califórnia, em Berkeley, vem explorando várias técnicas para desenvolver os recursos de inferência dos modelos de base e ajustados por comando.
Nesse trabalho, Sky-T1-32B-Preview, a equipe obteve um desempenho de inferência competitivo não apenas no lado matemático, mas também no lado da codificação do mesmo modelo.

Para garantir que esse trabalho "beneficie a comunidade em geral", a equipe abriu todos os detalhes (por exemplo, dados, código, pesos do modelo) para que a comunidade pudesse replicar e aprimorar o trabalho com facilidade:
- Infraestrutura: criação de dados, treinamento e avaliação de modelos em um único repositório;
- Dados: 17 mil dados usados para treinar o Sky-T1-32B-Preview;
- Detalhes técnicos: relatórios técnicos e registros de wandb;
- Pesos do modelo: 32B Pesos do modelo.
Detalhes técnicos
Processo de coleta de dados
Para gerar os dados de treinamento, a equipe usou o QwQ-32B-Preview, um modelo de código aberto com recursos de inferência comparáveis ao o1-preview. A equipe organizou a combinação de dados para cobrir os diferentes domínios em que a inferência era necessária e usou um procedimento de amostragem de rejeição para melhorar a qualidade dos dados.
Em seguida, inspirada pelo Still-2, a equipe reescreveu o rastreamento do QwQ em uma versão estruturada usando o GPT-4o-mini para melhorar a qualidade dos dados e simplificar a análise.
Eles descobriram que a simplicidade da análise era particularmente benéfica para os modelos de inferência. Eles são treinados para responder em um formato específico, e os resultados geralmente são difíceis de analisar. Por exemplo, no conjunto de dados APPs, sem reformatação, a equipe só poderia presumir que o código foi escrito no último bloco de código, e o QwQ só poderia alcançar uma precisão de cerca de 25%. No entanto, às vezes o código pode ser escrito no meio e, após a reformatação, a precisão aumenta para mais de 90%.
Rejeitar amostra. Dependendo da solução fornecida com o conjunto de dados, se a amostra QwQ estiver incorreta, a equipe a descarta. Para problemas matemáticos, a equipe realiza uma correspondência exata com a solução da verdade básica. Para problemas de codificação, a equipe executa os testes de unidade fornecidos no conjunto de dados. Os dados finais da equipe consistem em 5 mil de dados codificados de APPs e TACO e 10 mil de dados matemáticos do subconjunto de Olimpíadas dos conjuntos de dados AIME, MATH e NuminaMATH. Além disso, a equipe reteve 1k de dados científicos e de quebra-cabeças do STILL-2.
trem
A equipe usou os dados de treinamento para ajustar o Qwen2.5-32B-Instruct, um modelo de código aberto sem recursos de inferência. O modelo foi treinado usando 3 épocas, uma taxa de aprendizado de 1e-5 e um tamanho de lote de 96. O treinamento do modelo foi concluído em 19 horas em 8 H100s usando um offload DeepSpeed Zero-3 (com preço de cerca de US$ 450, de acordo com a Lambda Cloud). A equipe usou o Llama-Factory para o treinamento.
Resultados da avaliação
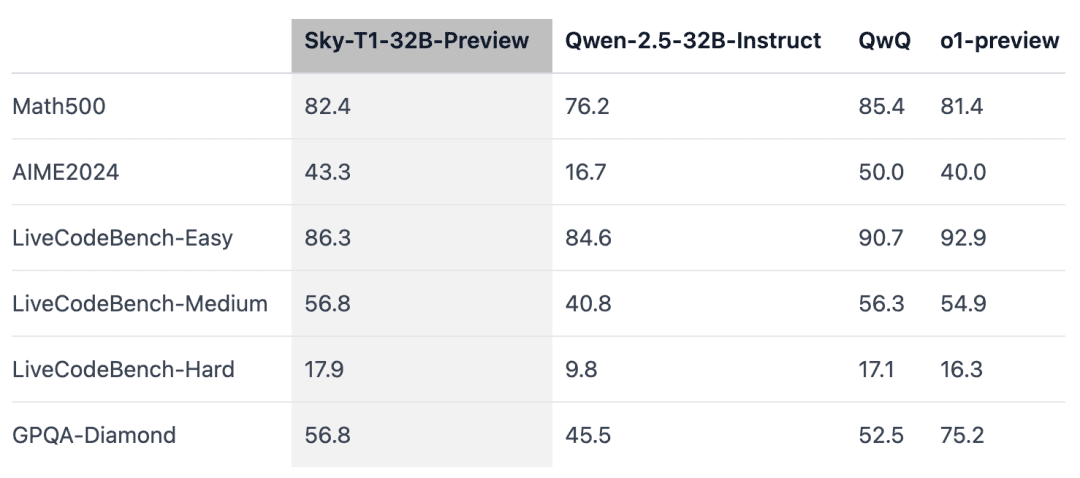
O Sky-T1 superou o desempenho de uma versão prévia do o1 no MATH500, um desafio de matemática de "nível de competição", e também superou uma versão prévia do o1 em um conjunto de quebra-cabeças do LiveCodeBench, uma avaliação de codificação. No entanto, o Sky-T1 não é tão bom quanto a versão prévia do o1 no GPQA-Diamond, que contém problemas relacionados a física, biologia e química que os graduados em doutorado devem conhecer.
No entanto, a versão o1 GA da OpenAI é mais avançada do que a versão prévia do o1, e a OpenAI espera lançar um modelo de inferência de melhor desempenho, o o3, nas próximas semanas.
Novas descobertas que merecem atenção
O tamanho do modelo é importante.Inicialmente, a equipe tentou treinar em modelos menores (7B e 14B), mas observou pouca melhoria. Por exemplo, o treinamento do Qwen2.5-14B-Coder-Instruct no conjunto de dados APPs mostrou uma ligeira melhoria no desempenho no LiveCodeBench, de 42,6% para 46,3%. No entanto, ao examinar manualmente a saída dos modelos menores (aqueles com menos de 32B), a equipe descobriu que eles frequentemente geravam conteúdo duplicado, o que limitando sua eficácia.
A combinação de dados é importante.A equipe treinou inicialmente o modelo 32B usando problemas de matemática de 3-4K do conjunto de dados Numina (fornecido pelo STILL-2), e a precisão do AIME24 melhorou significativamente de 16,7% para 43,3%. Entretanto, quando os dados de programação gerados pelo conjunto de dados APPs foram incorporados ao processo de treinamento, a precisão do AIME24 diminuiu para 36,7%. Isso pode implicar que essa queda se deve aos diferentes métodos de inferência necessários para as tarefas de matemática e programação.
O raciocínio de programação geralmente envolve etapas lógicas adicionais, como a simulação de entradas de teste ou a execução interna do código gerado, enquanto o raciocínio de problemas matemáticos tende a ser mais direto e estruturado.Para tratar dessas diferenças, a equipe enriqueceu os dados de treinamento com problemas matemáticos desafiadores do conjunto de dados NuminaMath e tarefas de programação complexas do conjunto de dados TACO. Essa combinação equilibrada de dados permitiu que o modelo se destacasse em ambos os domínios, recuperando uma precisão de 43,3% no AIME24 e, ao mesmo tempo, aprimorando seus recursos de programação.
Ao mesmo tempo, alguns pesquisadores expressaram ceticismo:


O que as pessoas pensam sobre isso? Fique à vontade para discutir o assunto na seção de comentários.
Link de referência: https://www.reddit.com/r/LocalLLaMA/comments/1hys13h/new_model_from_httpsnovaskyaigithubio/
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados



Nenhum comentário...