TPO-LLM-WebUI:質問を入力してリアルタイムにモデルを学習し、結果を出力できるAIフレームワーク。

はじめに
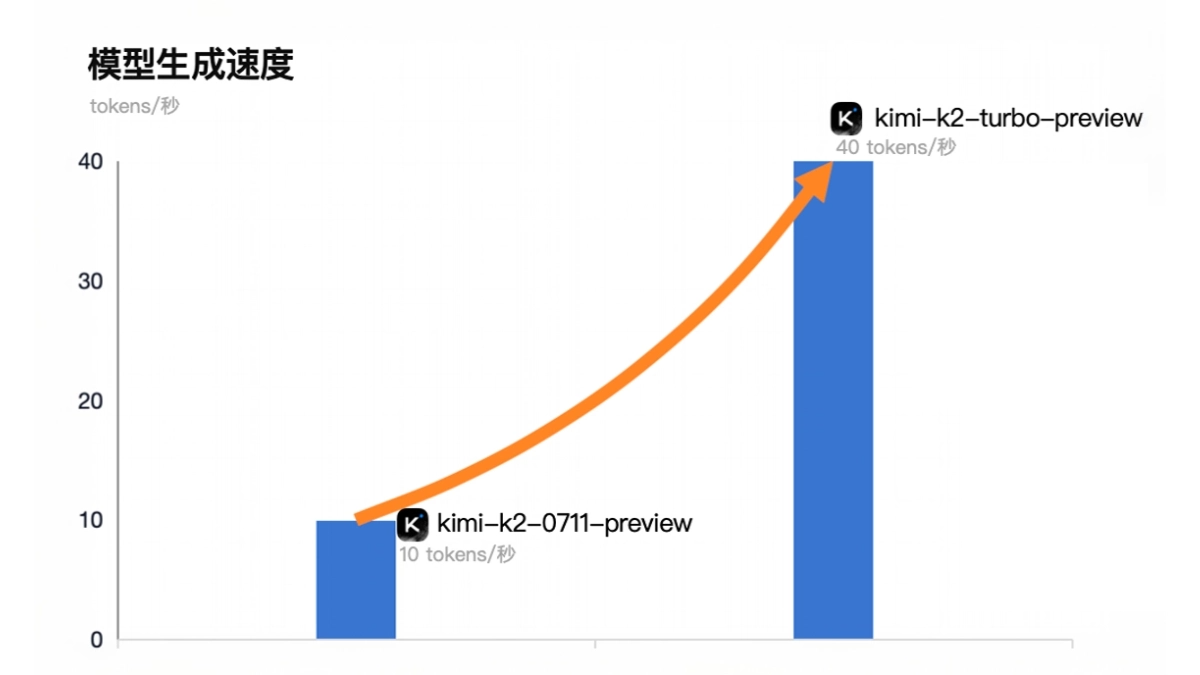
TPO-LLM-WebUIは、AirmomoがGitHubでオープンソース化している革新的なプロジェクトで、直感的なWebインターフェースを通じて大規模言語モデル(LLM)のリアルタイム最適化を可能にします。TPO (Test-Time Prompt Optimization)フレームワークを採用し、従来の面倒な微調整プロセスに完全に別れを告げ、トレーニングなしでモデル出力を直接最適化します。ユーザーが質問を入力した後、システムは報酬モデルと反復的なフィードバックを使用して、推論プロセス中にモデルが動的に進化することを可能にし、モデルをより賢くし、出力の品質を最大50%向上させます。 技術文書を磨くためであれ、セキュリティ応答を生成するためであれ、この軽量で効率的なツールは、開発者や研究者に強力なサポートを提供します。


機能一覧
- リアルタイムの進化推論段階を通じて出力を最適化することで、使えば使うほどユーザーのニーズに応えていく。
- 微調整は不要モデルの重みを更新せず、直接世代品質を向上させる。
- マルチモデル対応異なるベースとリワードモデルのロードをサポート。
- ダイナミック・プリファレンス・アライメント報酬フィードバックに基づいて出力を調整し、人間の期待に近づける。
- 推論の視覚化理解しやすく、デバッグしやすいように、最適化の反復プロセスを示す。
- 軽量で効率的コンピューティングは低コストで導入も簡単だ。
- オープンソースで柔軟ソースコードを提供し、ユーザー定義の開発をサポートします。
ヘルプの使用
設置プロセス
TPO-LLM-WebUIの導入には、いくつかの基本的な環境設定が必要です。以下は、ユーザーがすぐに始められるよう、詳細な手順を説明します。
1.環境を整える
以下のツールがインストールされていることを確認する:
- パイソン3.10コア動作環境。
- ギットプロジェクトコードの取得に使用。
- GPU(推奨)NVIDIA GPUが推論を加速。
仮想環境を作る:
コンディを使え:
conda create -n tpo python=3.10
conda activate tpo
またはPython独自のツール:
python -m venv tpo
source tpo/bin/activate # Linux/Mac
tpo\Scripts\activate # Windows
依存関係をダウンロードしてインストールする:
git clone https://github.com/Airmomo/tpo-llm-webui.git
cd tpo-llm-webui
pip install -r requirements.txt
TextGradをインストールします:
TPOはTextGradに依存しており、追加インストールが必要です:
cd textgrad-main
pip install -e .
cd ..
2.構成モデル
ベースモデルとボーナスモデルを手動でダウンロードする必要があります:
- 基本モデルとして
deepseek-ai/DeepSeek-R1-Distill-Qwen-32B(顔を抱きしめる) - インセンティブ・モデルとして
sfairXC/FsfairX-LLaMA3-RM-v0.1(顔を抱きしめる)
指定されたディレクトリにモデルを配置する(例えば/model/HuggingFace/)、そしてconfig.yamlにパスを設定する。
3.vLLMサービスを開始する
利用する ブイエルエルエム ホスティングの基本モデル。GPU2基を例にとります:
vllm serve /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
--dtype auto
--api-key token-abc123
--tensor-parallel-size 2
--max-model-len 59968
--port 8000
サービスが実行されたら http://127.0.0.1:8000.
4.WebUIの実行
新しいターミナルでウェブインターフェースを起動する:
python gradio_app.py
ブラウザアクセス http://127.0.0.1:7860|にできるようにあなたがそれをすることができます本当に出くわすことあなたは、実際には私たち約束、誰でも素早くはちょうど無視これらの一見正確にどのように{}人のことを忘れることができます。
主な機能
機能1:モデルの初期化
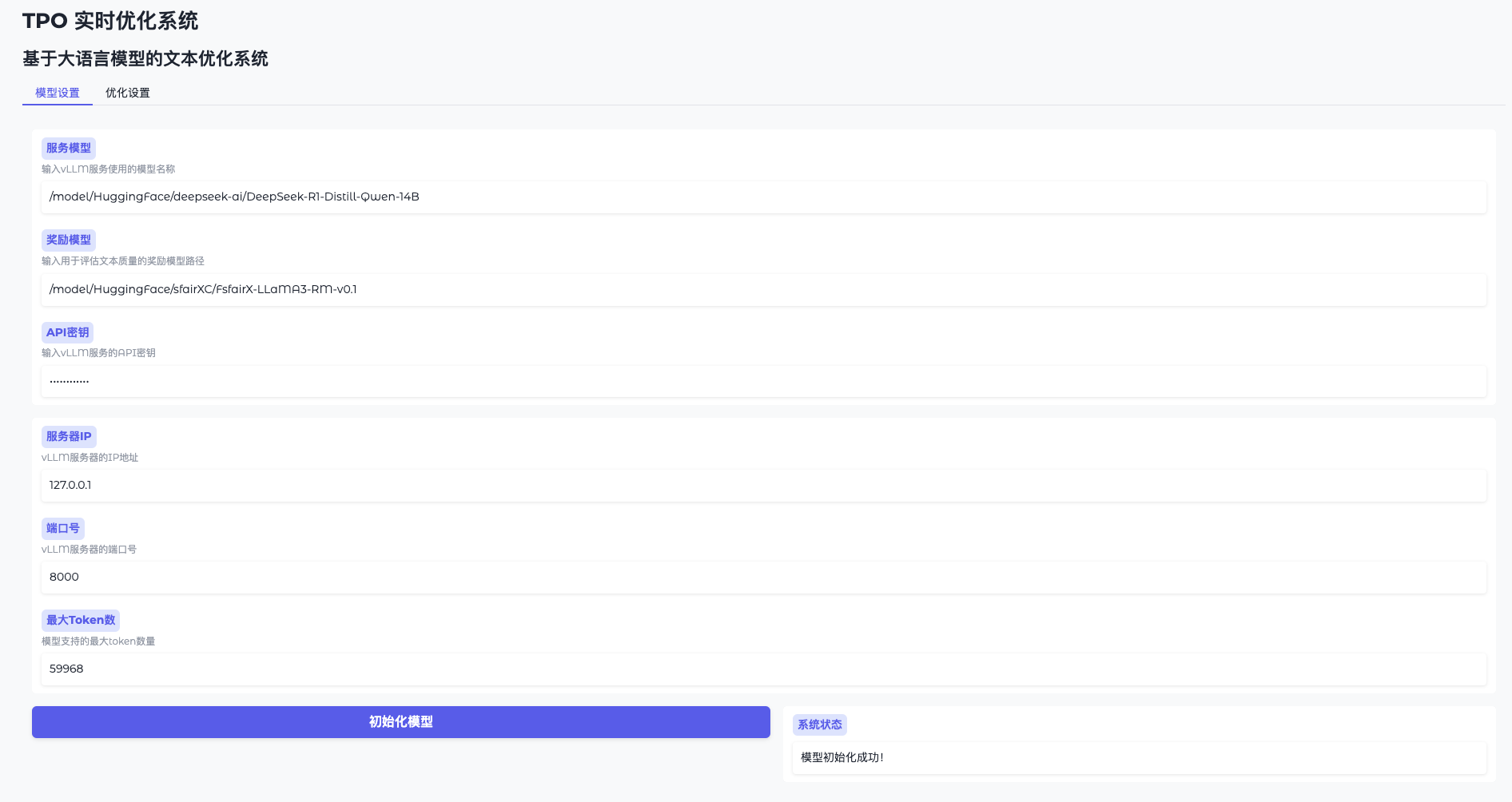
- モデル設定を開く
WebUIにアクセスし、"Model Settings "をクリックする。 - vLLMへの接続
住所を入力する(例http://127.0.0.1:8000)とキー(token-abc123). - 報酬モデルのロード
パスを指定する(例/model/HuggingFace/sfairXC/FsfairX-LLaMA3-RM-v0.1初期化」をクリックし、1~2分待つ。 - 準備の確認
インターフェイスが "Model ready "と表示し、続行できる。
機能2:リアルタイムで出力を最適化する
- トグル最適化ページ
設定の最適化」に進む。 - 入力の問題
この技術文書をタッチアップする」などの内容を入力する。 - オペレーションの最適化
Start Optimisation "をクリックすると、システムは複数の候補結果を生成し、それらを繰り返し改善する。 - 進化の過程をチェック
結果ページには、初期出力と最適化された出力が表示され、徐々に品質が上がっていく。
機能3:スクリプト・モードの最適化
WebUIを使用しない場合は、スクリプトを実行することができます:
python run.py
--data_path data/sample.json
--ip 0.0.0.1
--port 8000
--server_model /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
--reward_model /model/HuggingFace/sfairXC/FsfairX-LLaMA3-RM-v0.1
--tpo_mode tpo
--max_iterations 2
--sample_size 5
最適化の結果は logs/ フォルダー
特別機能の詳細
微調整に別れを告げ、リアルタイムで進化する
- 手続き::
- 質問を入力すると、システムが最初の答えを生成する。
- 次の反復を導くために、モデルの評価とフィードバックに報酬を与える。
- 何度か繰り返すうちに、出力は "より賢く "なり、品質も大幅に向上する。
- ゆうせいトレーニングなしでいつでも最適化できるので、時間と計算を節約できます。
使えば使うほど賢くなる。
- 手続き::
- 異なる問題に対して異なる入力で同じモデルを複数回使用する。
- システムはそれぞれのフィードバックに基づいて経験を蓄積し、よりニーズに合ったアウトプットをする。
- ゆうせいユーザーの嗜好を動的に学習し、長期的により良い結果をもたらします。
ほら
- ハードウェア要件16GB以上のビデオメモリを推奨し、複数のGPUがリソースの空きと利用可能性を確保する必要がある。
export CUDA_VISIBLE_DEVICES=2,3指名。 - 問題解決ビデオメモリーがオーバーフローした場合は、ビデオメモリーを下げてください。
sample_sizeまたはGPUの稼働率をチェックする。 - 地域支援GitHubのREADMEまたはIssuesを参照してください。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事

コメントはありません