

オリンピアード・レベルの問題への挑戦:LLM中国数学のパフォーマンス・ベンチマーク7つのレビュー

数式導出、論理連鎖の構築、抽象的思考を包含する数学的能力は、人工知能(AI)、特に大規模言語モデル(LLM)の能力をテストするための重要な分野と考えられてきた。これは、計算能力をテストするだけでなく、複雑な問題を推論し、理解し、解決するモデルの能力をより深く掘り下げるためである。
しかし、チューリッヒ工科大学の研究チームが最近発表した結果によると、トップレベルの大規模言語モデル(LLM)であっても、米国の数学オリンピックレベルのような難しい数学競技の問題に直面すると、一般的にスコアが低くなることが分かっており、厳密な数学的推論という点で、現在のLLMの真の能力についての議論が促されている。
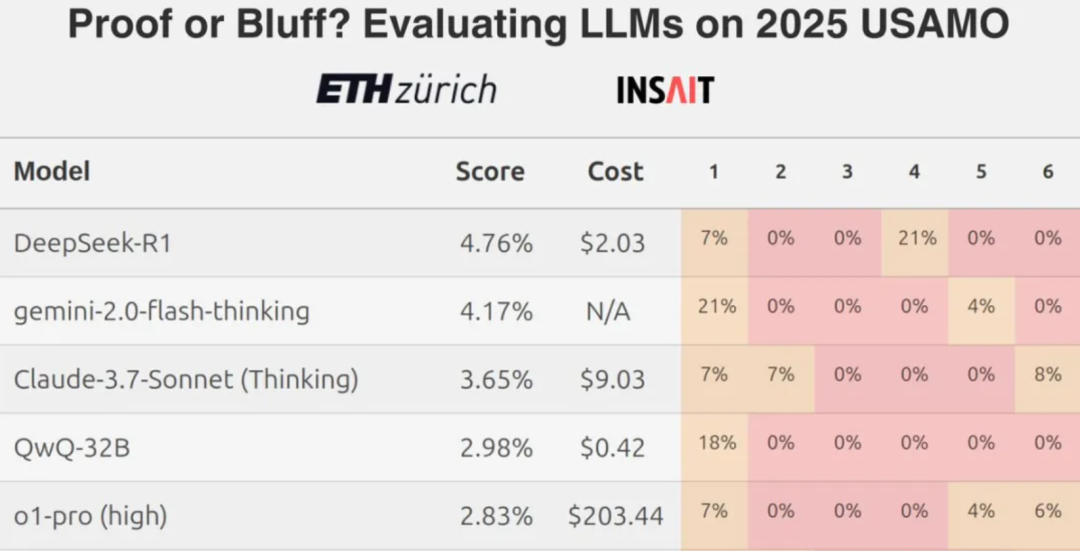
このような状況において、自然な疑問は、中国語で定式化された数学的問題を扱ったときに、これらのモデルがどの程度の性能を発揮するかということである。このレビューでは、国内外の主流または新興の大規模言語モデル合計7つを選び、アリババ世界数学コンテストと中国数学オリンピックの問題を用いて、その数学的能力を並べて比較した。
テストに参加したモデルは以下の通り:
- 国内モデル:
DeepSeek R1そしてHunyuan T1そしてTongyi Qwen-32B(原文ママ)通义QwQ-32B),YiXin-Distill-Qwen-72B - 国際的なモデリング:
Grok 3 betaそしてGemini 2.0 Flash Thinkingそしてo3-mini
総合的なパフォーマンス評価
評価は難易度の高い10問の問題で構成され、合計13問の採点問題がある。採点基準は、完全な正答で1点、部分的な正答で0.5点、誤答は無得点とした。
このテストにおける各モデルの総合的な正しさは以下の通りである:

詳細な得点分布は、モデル間の性能の違いを示している:
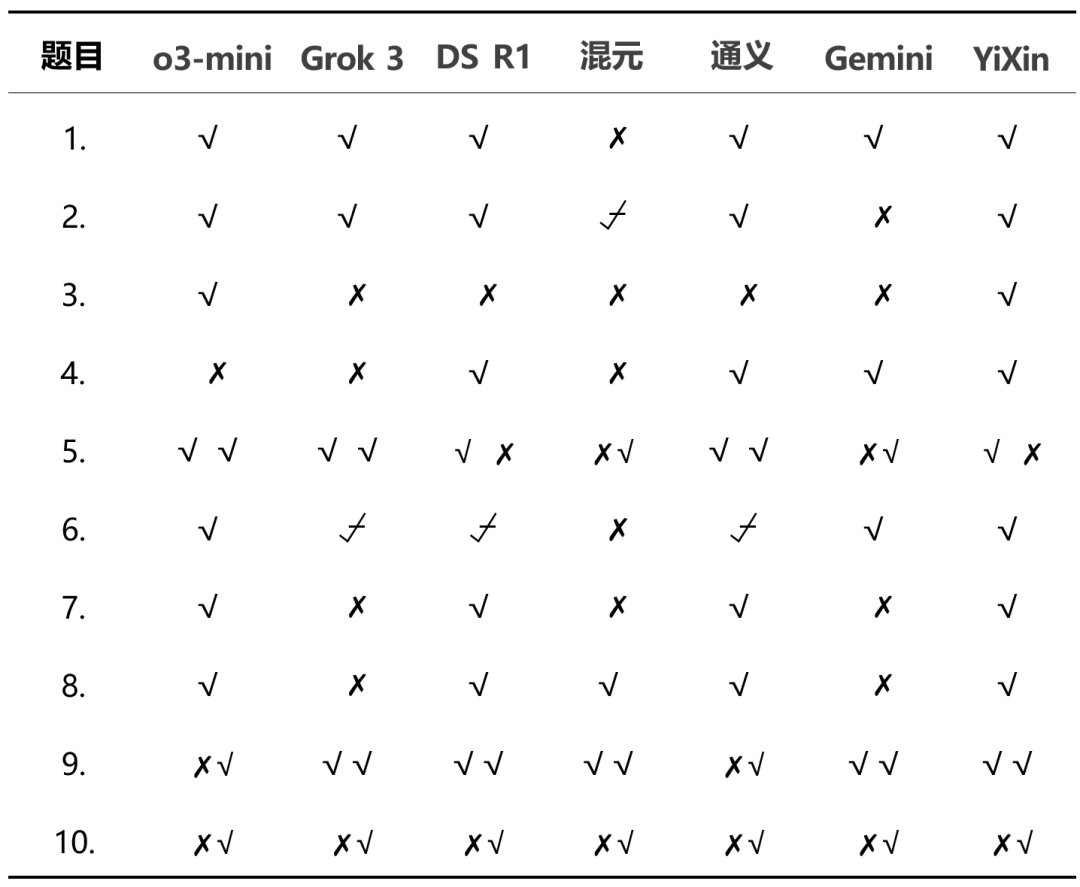
全体的な結果から。o3-mini 歌で応える YiXin-Distill-Qwen-72B はこのテストで好成績を収め、数学的問題解決能力の高さを示した。他のモデルの成績はばらつきがあった。
次に、いくつかのテスト問題に対する具体的な答えを示す。
測定内容
ラウンド1:変化の問題
質問だ: おじいちゃんが60ドルを持っていて、スーパーマーケットに20ドル分の野菜を買いに行ったとき、レジ係はおじいちゃんにどのようにお釣りを渡すだろうか?
分析する: これは基本的な算数の応用問題で、モデルの生活シナリオの理解と基本的な金銭計算能力を問う。
結果o3-mini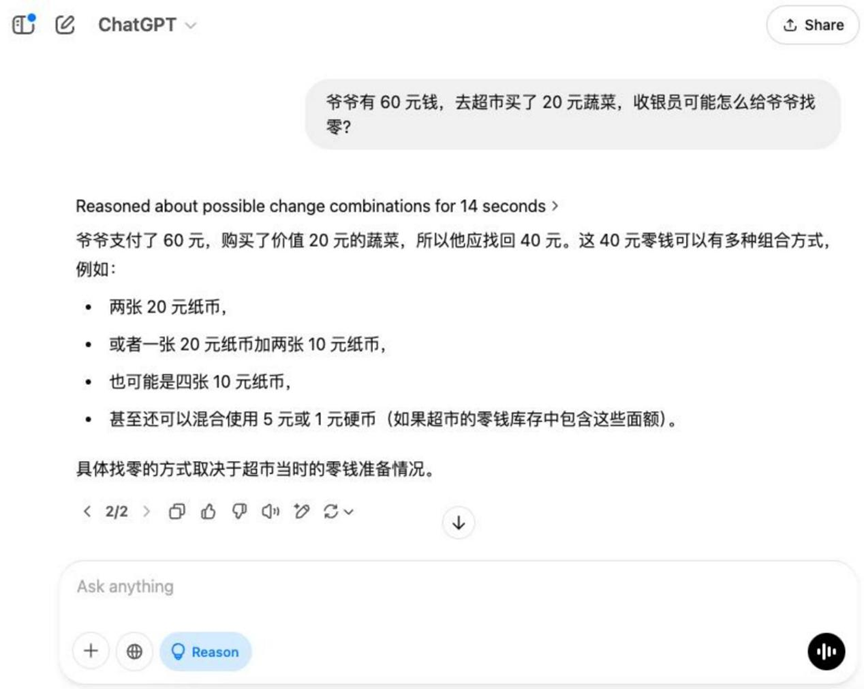
Grok 3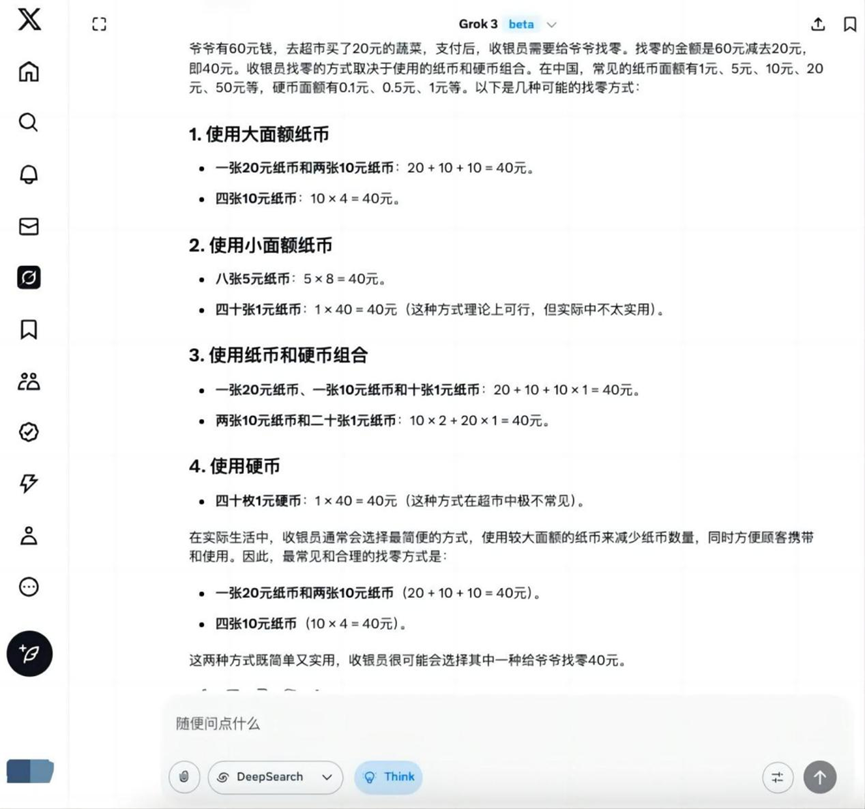
Hunyuan T1
Gemini 2.0 Flash Thinking
YiXin-Distill-Qwen-72B
この基本的なトピックについて Hunyuan T1 それ以外のモデルでは、ゼロを見つけるための正しい解が得られる。
ラウンド2:歩行距離の算出と方法論的判断
質問だ: シャオミンとシャオホアは毎日歩いて学校に通っている。明は1分間に48メートル、華は1分間に55メートル歩く。シャオミンの家は学校から384メートル離れている。小華は家から学校まで明より4分長い。小華の家は学校から何メートル離れているか。また、その理由は?
方法1:55×4=220(メートル)、384+220=604(メートル)
方法2:384÷48=8(分)、55×(8+4)=660(メートル)
分析する: この問題は、旅行問題の計算と論理的判断を組み合わせたもので、正解を計算できるだけでなく、与えられた解答の正誤を分析し、多段階の推論と論理的な見極めができることが求められる。
結果DeepSeek R1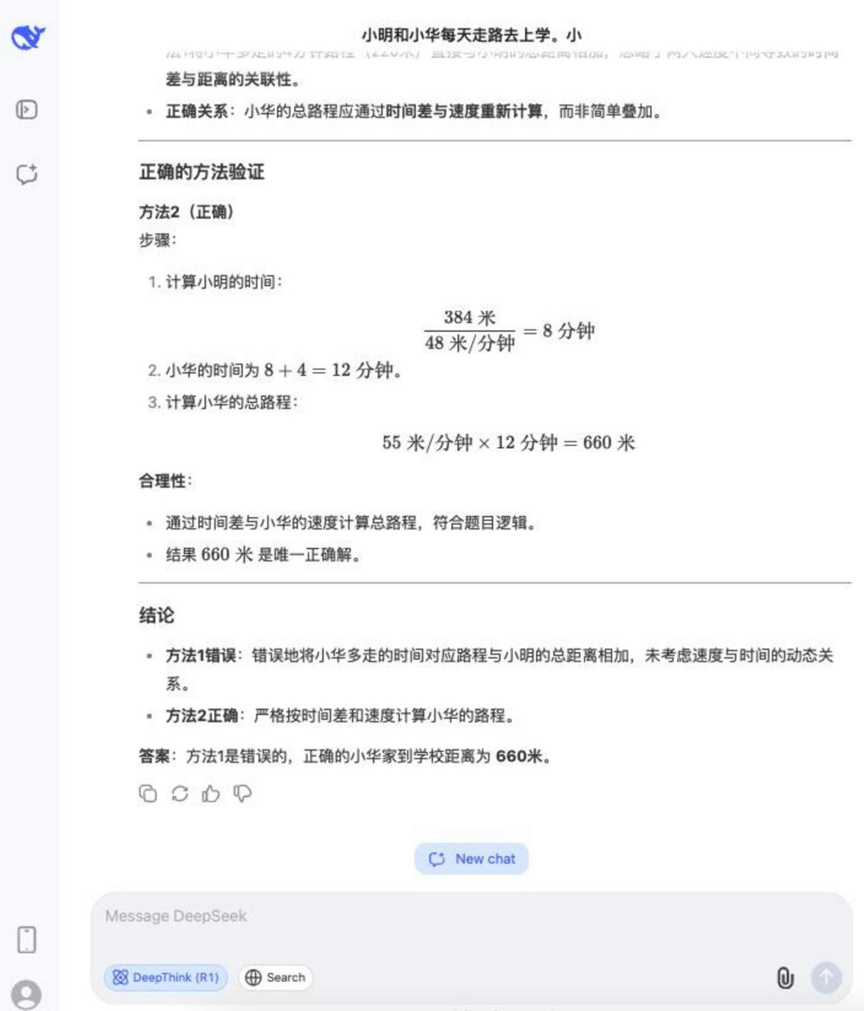
Tongyi Qwen-32B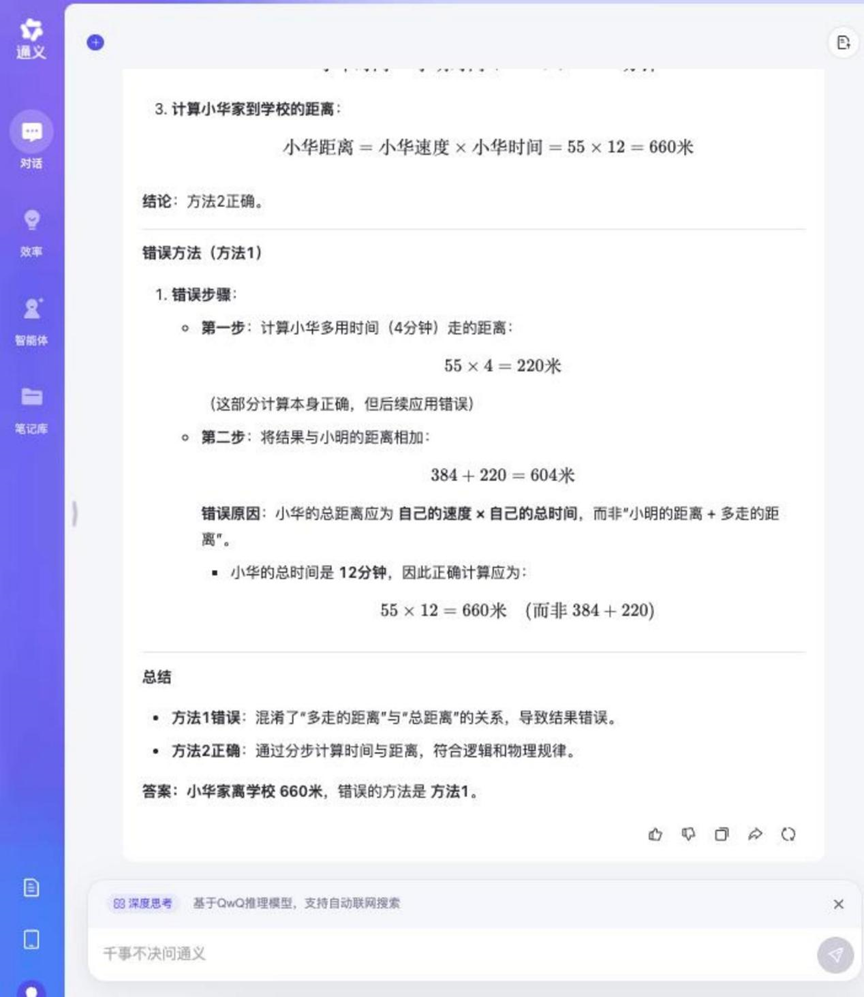
YiXin-Distill-Qwen-72B
この問題の推理プロセスは比較的長かったが、テストに参加したモデルのほとんどがこの問題に正解し、誤った方法を判断することができた。
ラウンド3:幾何学的オクルージョン問題(見えない塔)
質問だ: ある街に、A,B,C,D,E,F地点にある6つの塔がある。数人の生徒が旅行グループを作り、自由旅行に出かけた。しばらくして,各生徒はA,B,C,D地点にある4つの塔しか見えず,EとF地点にある塔は見えないことに気づく.生徒と塔の位置は同一平面上の点とみなされ、これらの点は互いに一致せず、点A、B、C、D、E、Fのうち任意の3点は共通線を共有しないことが知られている。タワーが見えない唯一の可能性は、視線が他のタワーによって遮られている場合である。例えば,生徒がAとBと同位置にある点Pにいて,Aが線分PB上にある場合,生徒はBにあるタワーを見ることができない.この旅行グループにいる生徒の最大人数は? a. 3 b. 4 c. 6 d. 12
分析する: これは、視認性、オクルージョン、点セットの構成問題を含む複雑な幾何学的・論理的推論問題であり、モデルには高度な空間的想像力と論理的推論が要求される。
結果o3-mini
DeepSeek R1
YiXin-Distill-Qwen-72B
問題の難易度は大幅に上がった。今回のテストでは o3-mini 歌で応える YiXin-Distill-Qwen-72B 他のモデルは正解を出せなかった。
第4戦:確率問題(虎と虎)
質問だ: 春節の期間中、ある牛乳会社は旧正月のブラインドボックス活動を開始した。魏 "の3つの絵柄のうちの1つが入っている。虎」「盛」「魏」を2つ集めると、「虎虎盛魏」家族の肖像画となる。この活動が始まると、ネットフリックスのヒットとなり、多くの人々が参加するようになった。既知の条件は以下の通りである:赤い包みに描かれた絵柄はランダムに独立して分布しており、互いに区別できない。虎」、「盛」、「魏」の3つの絵柄が出現する確率は1/3である。 Q: 「虎虎盛魏」を一式集めるには、何パック必要ですか?Q: 「虎虎勝魏」の家族写真を一式集めるには、平均何パックの牛乳を買う必要があるか?
分析する: これは典型的なコレクター問題(クーポンコレクター問題の変形)で、確率論と期待値計算を使う必要があり、確率モデルを扱い、数学的な期待値計算を行うモデルの能力が問われる。
結果DeepSeek R1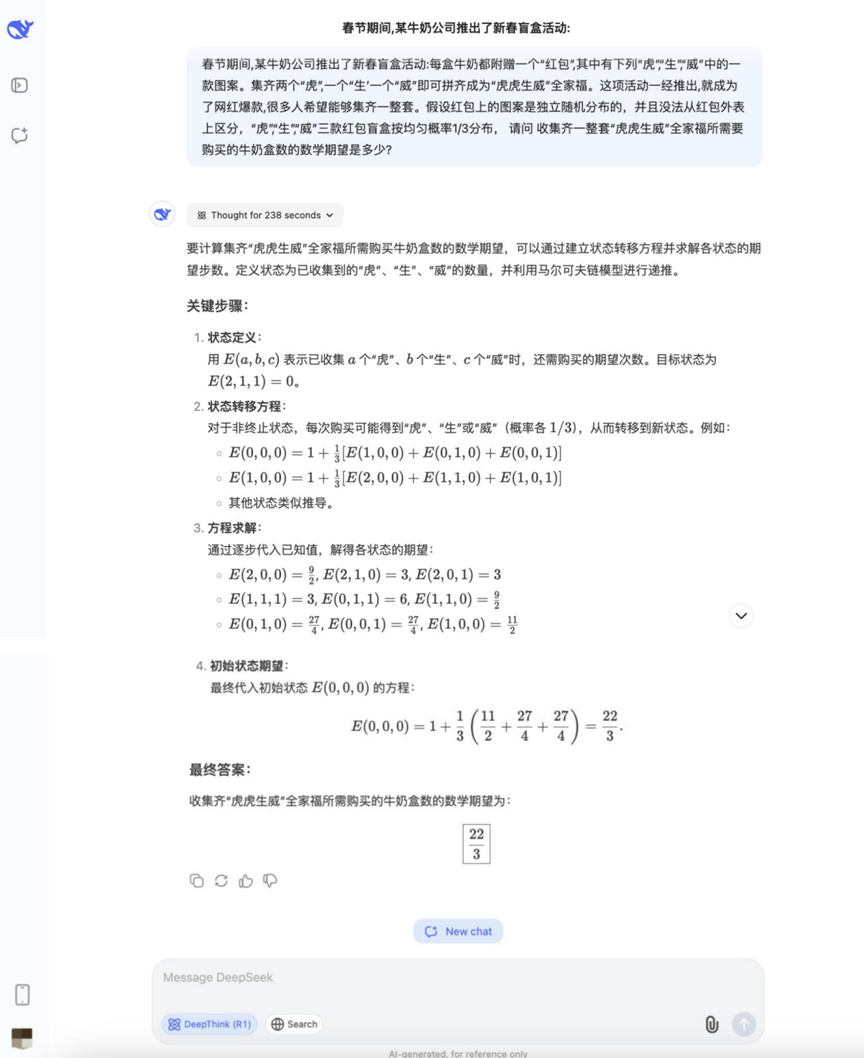
Hunyuan T1
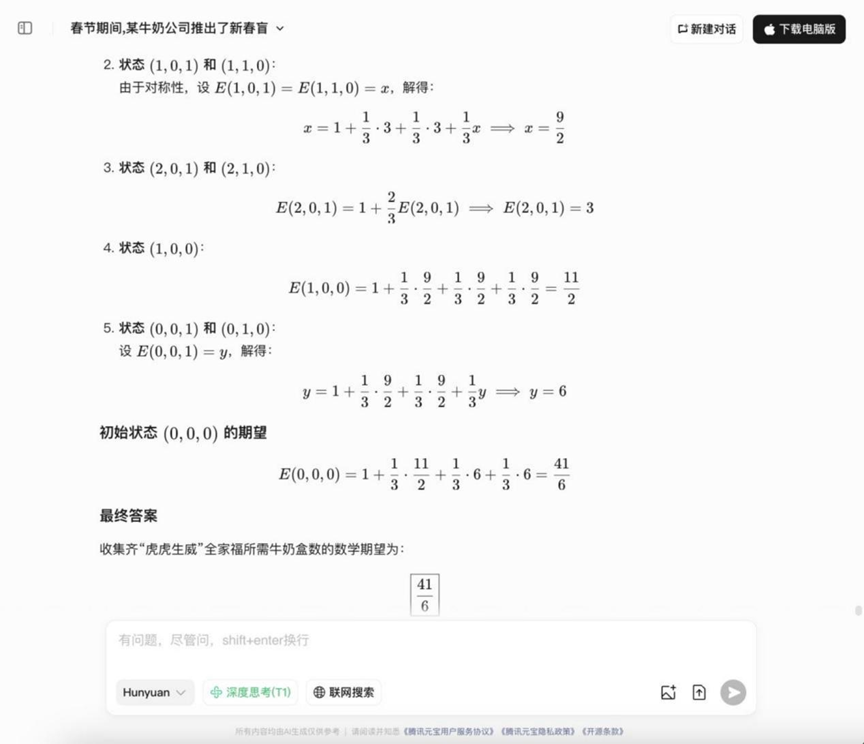
YiXin-Distill-Qwen-72B
このラウンドでは、確率の問題に対する答えが分かれ始め、いくつかのモデルは正しくアイデアを列挙し、計算することができた。
第5戦:ジオメトリーとパスプランニング(ファイターズ戦)
問題の説明 写真
分析する: これは、幾何学、座標系またはグリッド系、最短経路/最適戦略を組み合わせた問題であり、モデルがグラフィカルな情報を理解し、空間的な推論とプランニングを実行することを必要とする場合がある。
結果o3-mini解決に成功
YiXin-Distill-Qwen-72B部分的に正しい

このラウンドのテストでは、より高度なモデルの統合が要求され、テストされたモデルの約半数が完全に正しく処理された。
ラウンド6:数論の証明問題(最小の非因子を見つける)
問題の説明 写真
分析する: 厳密な論理的演繹と数論的概念の深い理解を必要とする証明問題の領域に入ると、これらの問題はモデルの抽象的推論能力を直接試すことになる。
結果o3-mini
YiXin-Distill-Qwen-72B

国内モデルではYiXin-Distill-Qwen-72B このラウンドの証明問題でより良い成績を収めた。証明問題はモデルにとってかなり難易度が高かった。
ラウンド7:関数と写像の問題(単位円上の写像)
問題の説明 写真
分析する: この問題では、高等数学における関数、写像、単位円の概念を含み、抽象的な数学的定義を理解し、適用するモデルの能力を問う。
結果o3-mini
YiXin-Distill-Qwen-72B
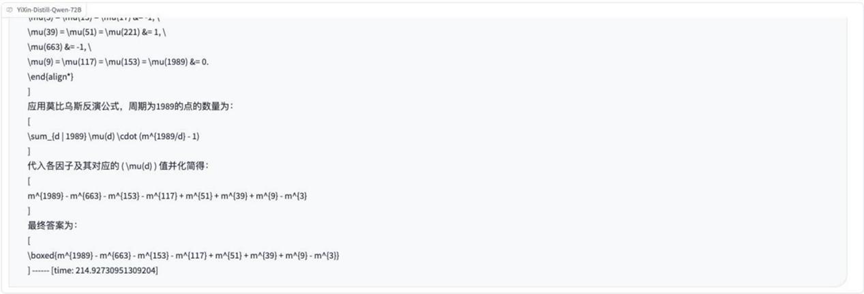
約半数のモデルは、抽象的なマッピングを含むこの問題を正しく処理することができた。
ラウンド8:組合せ最適化問題(最大三角形)
質問だ: 空間には1989の点があり、そのうち3つは線を共有していない。これらの点は30のグループに分けられ、それぞれ点の数が異なる。任意の3つの異なるグループから点を頂点として三角形を作ることができる.問:三角形の数を最大にするために、各グループの点の数をどのように配分すれば よいだろうか?
分析する: これは組合せ数学の最適化問題で、モデルには組合せ計数の原理を理解し、より複雑な数学的モデリングと最適化の考え方を含む最適配分戦略を見つけることが要求される。
結果o3-mini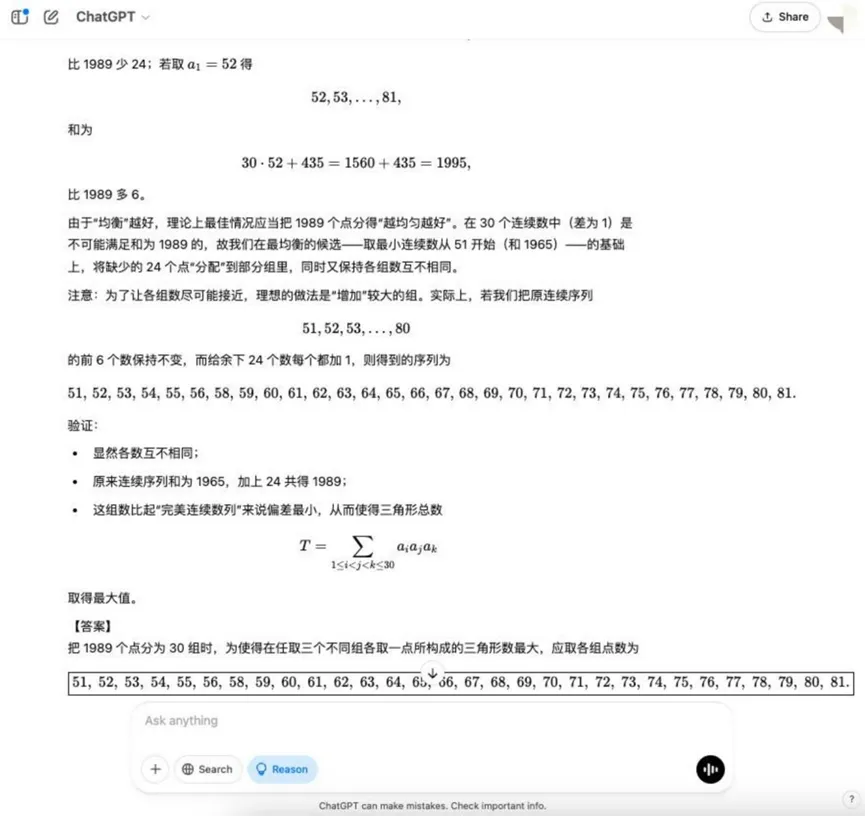
YiXin-Distill-Qwen-72B

組み合わせ最適化問題はさらに難易度を高め、モデルの数学的戦略と計算能力に高い要求を課す。
第9ラウンド:数論の問題(因数分解)
問題の説明 写真
分析する: ここでも数論的な概念が関与しており、階乗や積分性といった関係のモデルの理解と適用が検討される。
結果o3-mini部分的に正しい
YiXin-Distill-Qwen-72Bその通りだ。

YiXin-Distill-Qwen-72B このカウントの話題では堅実なパフォーマンスだった。
ラウンド10:幾何学的問題(等面積点)
問題の説明 写真
分析する: 最終問題は、面積の計算、点の軌跡や存在証明を含む幾何学的な問題で、モデルの幾何学的直感、代数演算、論理的推論が試された。
結果o3-mini
DeepSeek R1
YiXin-Distill-Qwen-72B

最終的な幾何学の問題でも、複雑な幾何学的問題を処理する能力において、モデル間の違いが見られた。
観察と分析
多くの大規模な言語モデルで中国人の数学的能力をテストした結果、以下のような見解が得られた:
- 基本的な数学的スキルのモデリングが大幅に向上: 以前のモデルと比較して、現在のLLM世代は、幾何学、確率、およびいくつかのオープンエンドの応用問題など、多段階の推論を含む数学的問題の処理において著しい向上を示している。これは、モデルサイズの増大、豊富な学習データ、および「思考連鎖」などの推論強化技術の適用によるものである。
- 問題解決のスタイルには違いがある: 解決プロセスの詳細度という点では、モデルによって挙動が異なる。
o3-mini,Grok 3 beta,Tongyi Qwen-32B出力は比較的簡潔で、推論ステップは単純だ。DeepSeek R1,Hunyuan T1,YiXin-Distill-Qwen-72Bより詳細な思考プロセスを示す傾向があり、時には反省や修正のステップも含まれるため、より "冗長 "になるが、これは彼らの推論の論理をトレースするのに役立つかもしれない。Gemini 2.0 Flash Thinkingの問題解決プロセスは長いだけでなく、主に英語の出力を使用していることから、中国の数学コーパスに対する学習が比較的不十分である可能性が示唆される。
- 入力エラーに対するロバスト性: このテストでは、問題の記述に小さな表記ミスや不規則な表現があったとしても、一部のモデルは問題の意味を正しく理解して解答することができ、ある程度のロバスト性を示していることが観察された。しかし、これはモデルが常にエラーを無視できることを意味するものではなく、重要な情報のエラーは依然として解答の失敗につながる可能性があります。
- 今後の強化点:専門化とツール統合: 明らかな進歩にもかかわらず、複雑な数学的問題、特に難しい競技問題や厳密な証明を必要とするシナリオを扱う場合、現在のLLMの精度にはまだ改善の余地がある。将来的な改良の道筋としては、以下のようなものが考えられる:
- 外部コンピューティングエンジンの統合: LLMの厳密計算と記号演算の欠点は、Wolfram Alphaのような記号計算ツールを呼び出すことで補われる。
- ドメイン専用の微調整: 数理論理学、数学の特定分野(代数学、幾何学、確率論など)のための高品質で微調整されたデータセットを構築し、専門家の推論と知識の深さのモデルを強化する。
- インタラクティブな学習と復習: ユーザがソリューションプロセスをガイドし、ミスステップを指摘し、モデルがソリューション戦略を動的に調整できるようなメカニズムを開発する。
- ユーザーへの提言
- 学生だ: LLMは、基本的な問題に対する解答や答えを素早く検証することで、学習を支援するために使用することができます。しかし、複雑な問題や独創的な問題では、モデルが「重大なナンセンス」(つまり、自信を持って間違った答えを出すこと)をする可能性があるので注意が必要です。
- 教育者: AIを活用した授業を行う場合、生徒がモデルに頼って表面的な答えを導き出さないように、より生徒の深い理解や主体的な思考力を試すような問題を設計する必要がある。
- 開発者 LLMを数学的問題の解決に適用する場合、ファジーな理解によるモデルによる効果的でない推論や「ブレーンストーミング」を減らすために、プロンプト・エンジニアリングを最適化することによって、問題の境界と解決要件を明確にする必要がある。
結論として、数学における大規模言語モデルの応用は、探索的な段階から徐々に実用的な段階へと移行しつつある。今後のモデル開発の方向性は、人間の思考の柔軟性をシミュレートすることと、数学的論理の厳密性を確保することの、より良いバランスを追求することであろう。
注釈
今回のレビューでより優れたパフォーマンスを見せたのは YiXin-Distill-Qwen-72B モデル情報は以下の通り:
- 標準バージョン:https://huggingface.co/YiXin-AILab/YiXin-Distill-Qwen-72B
- AWQ 定量版:https://huggingface.co/YiXin-AILab/YiXin-Distill-Qwen-72B-AWQ
- ローカル展開に必要なリソース: 72B Standard Editionは、約8枚のNVIDIA 4090クラスのグラフィックカードを必要とします。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事




コメントはありません