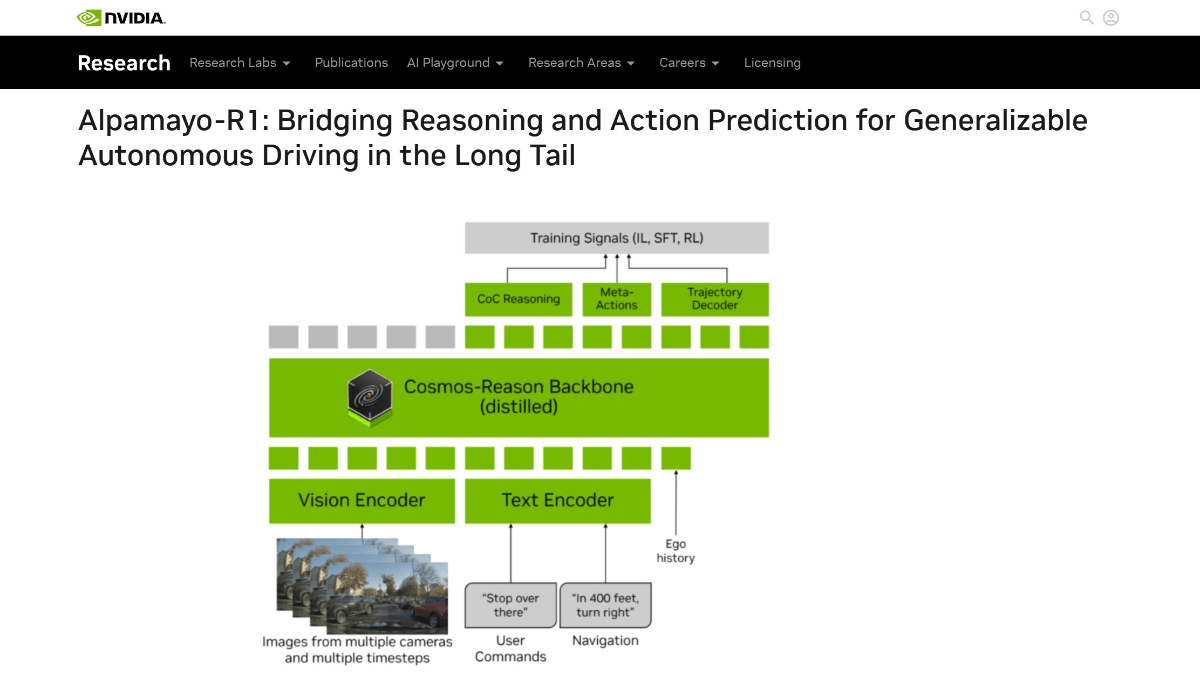
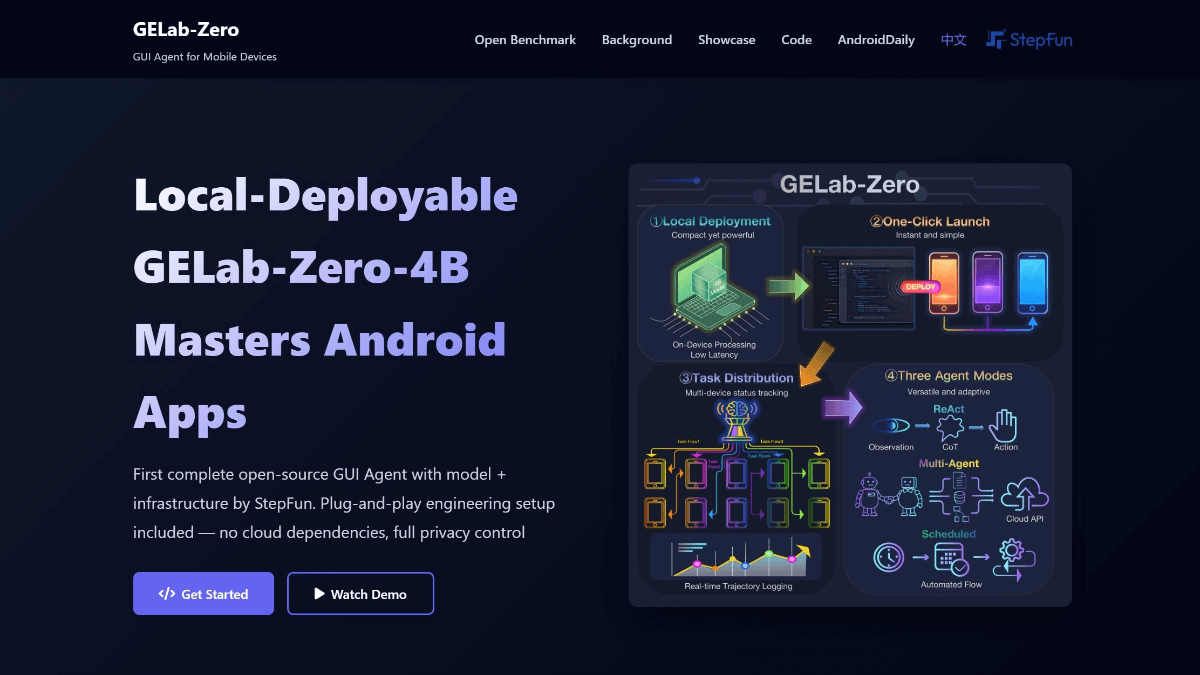
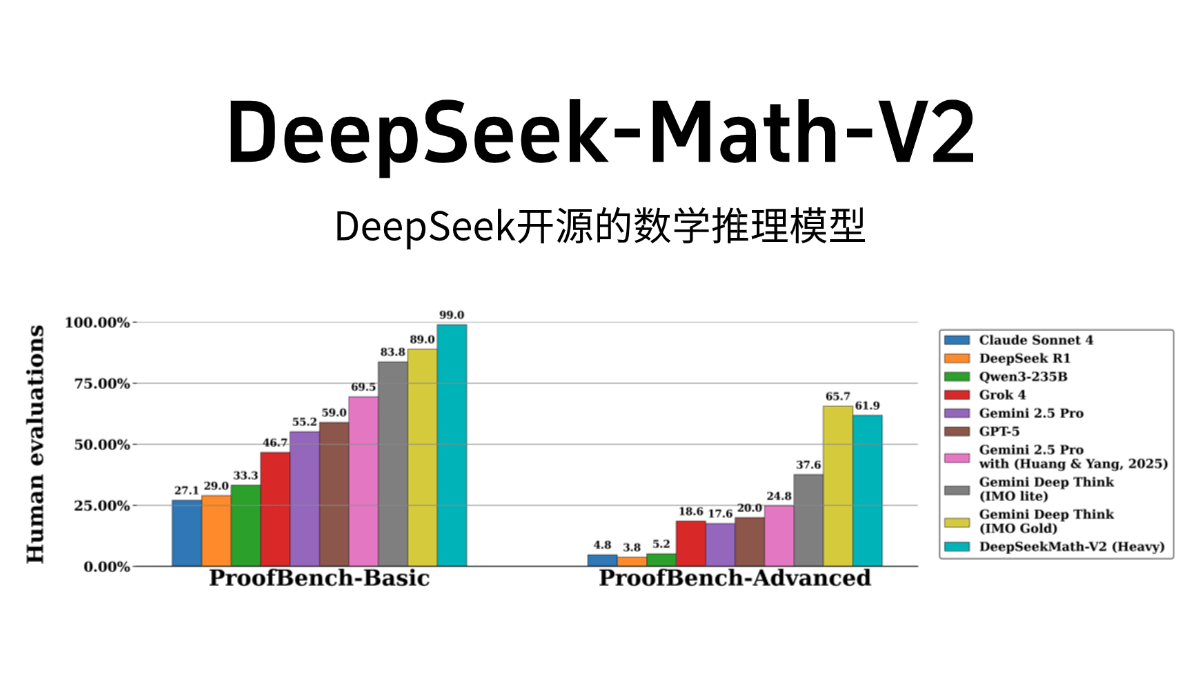
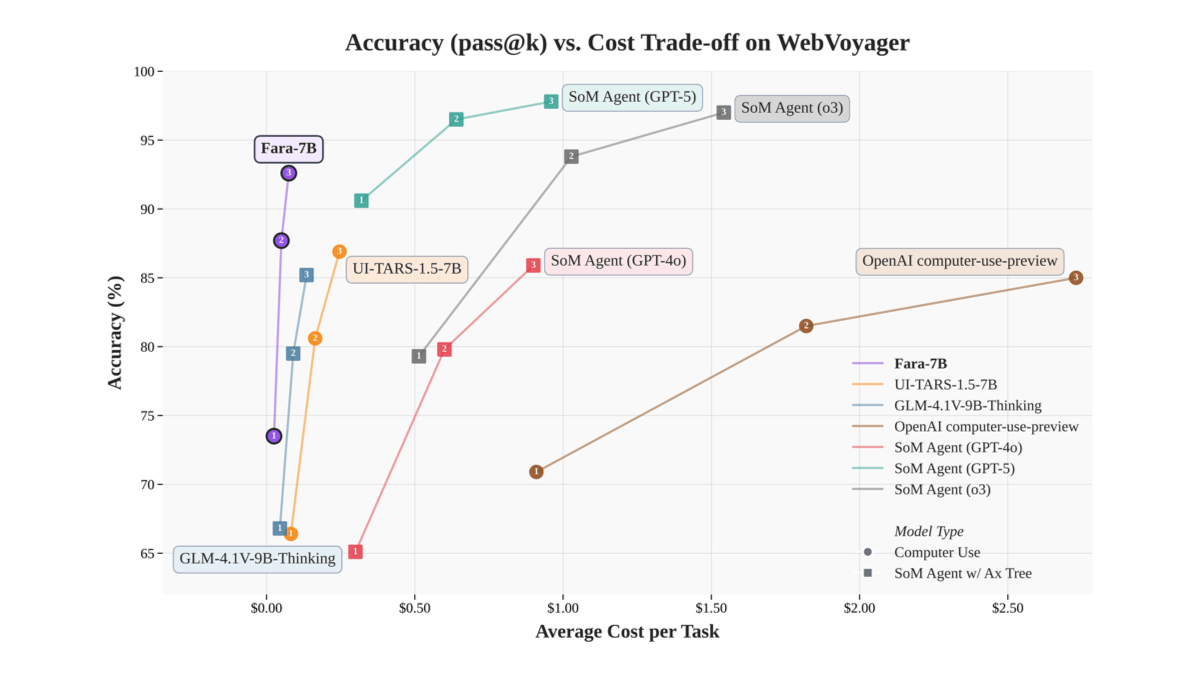
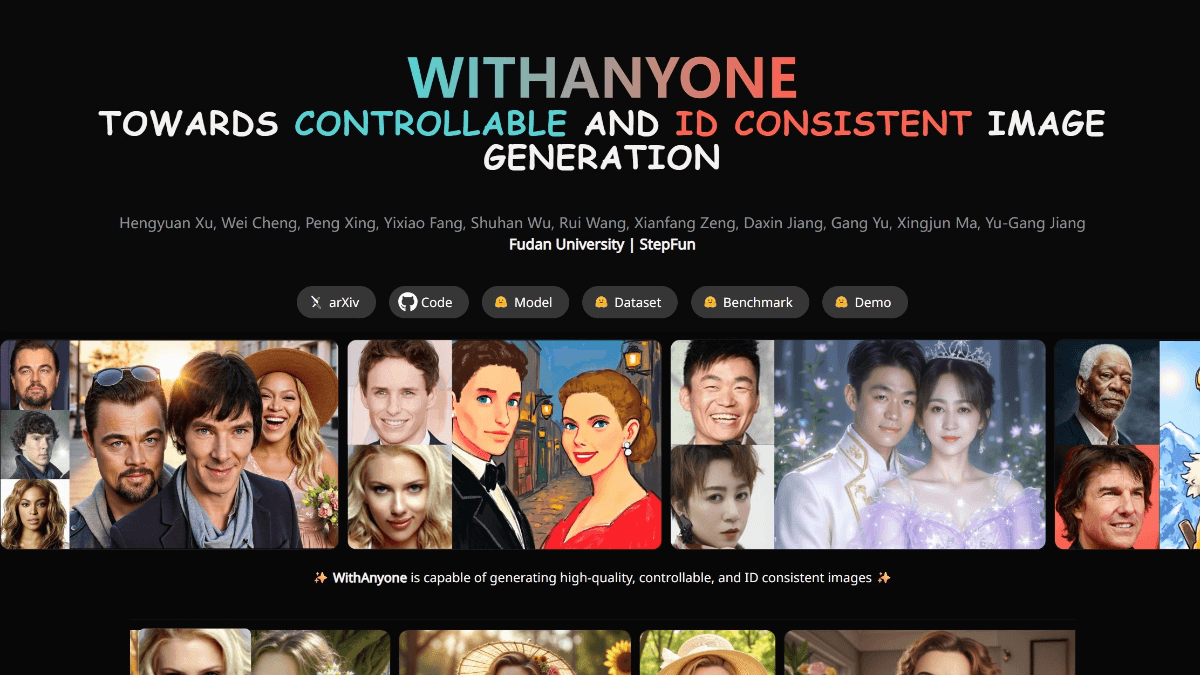
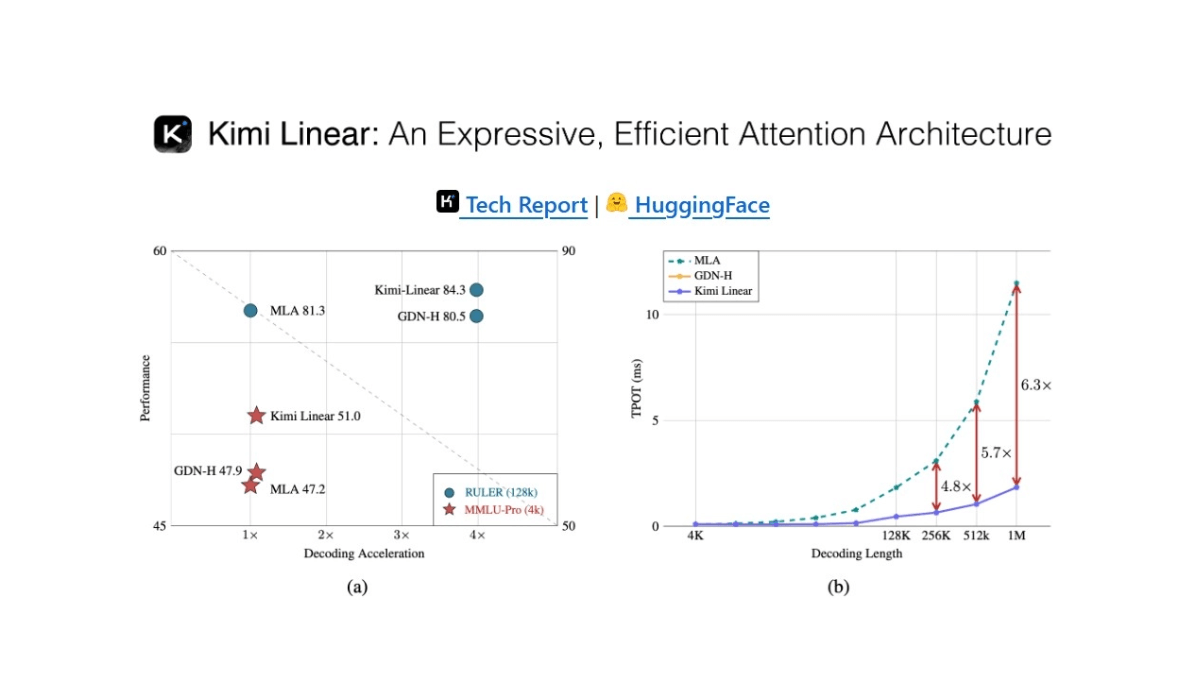
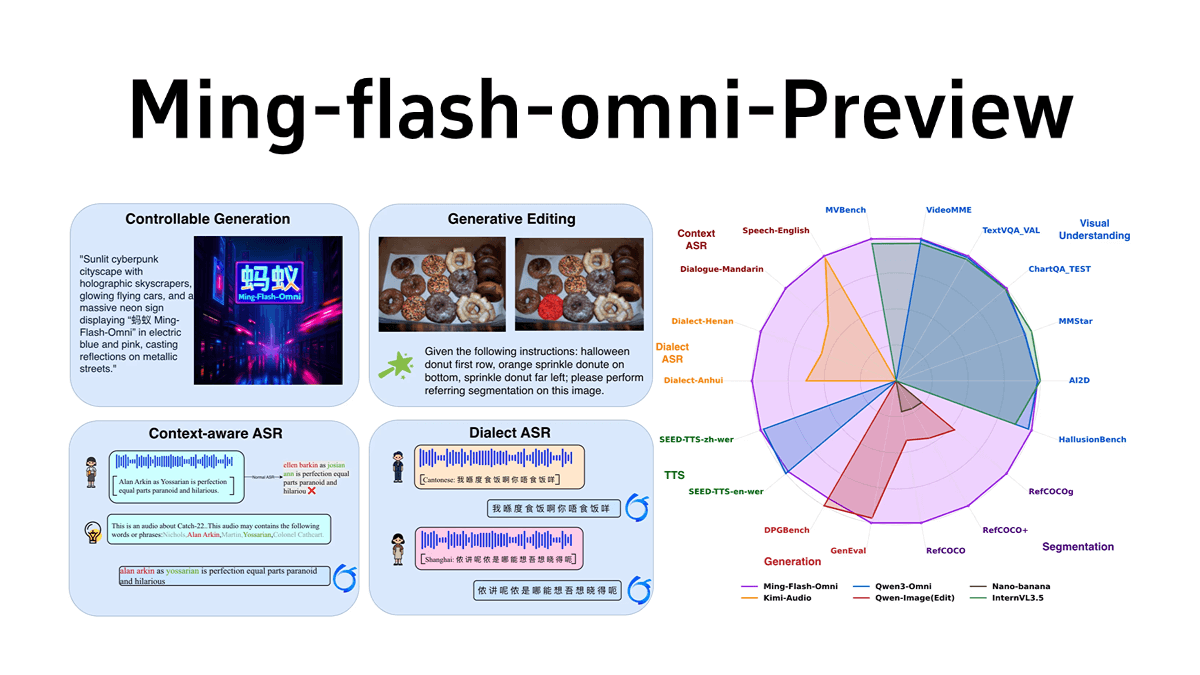
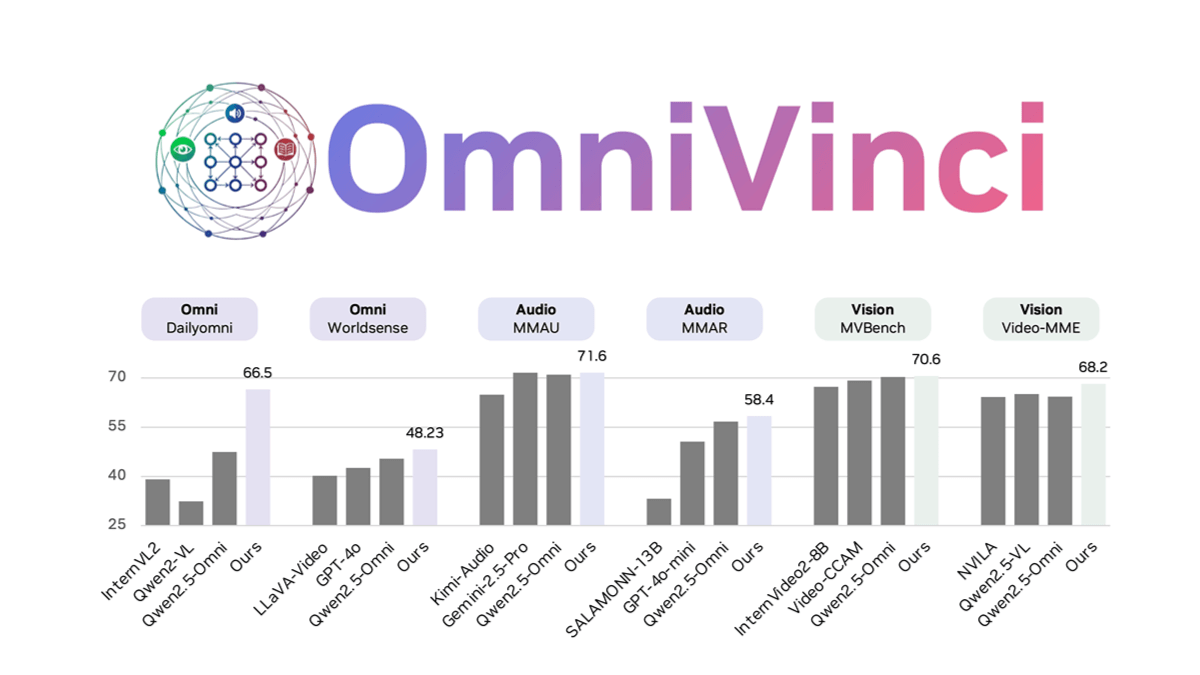
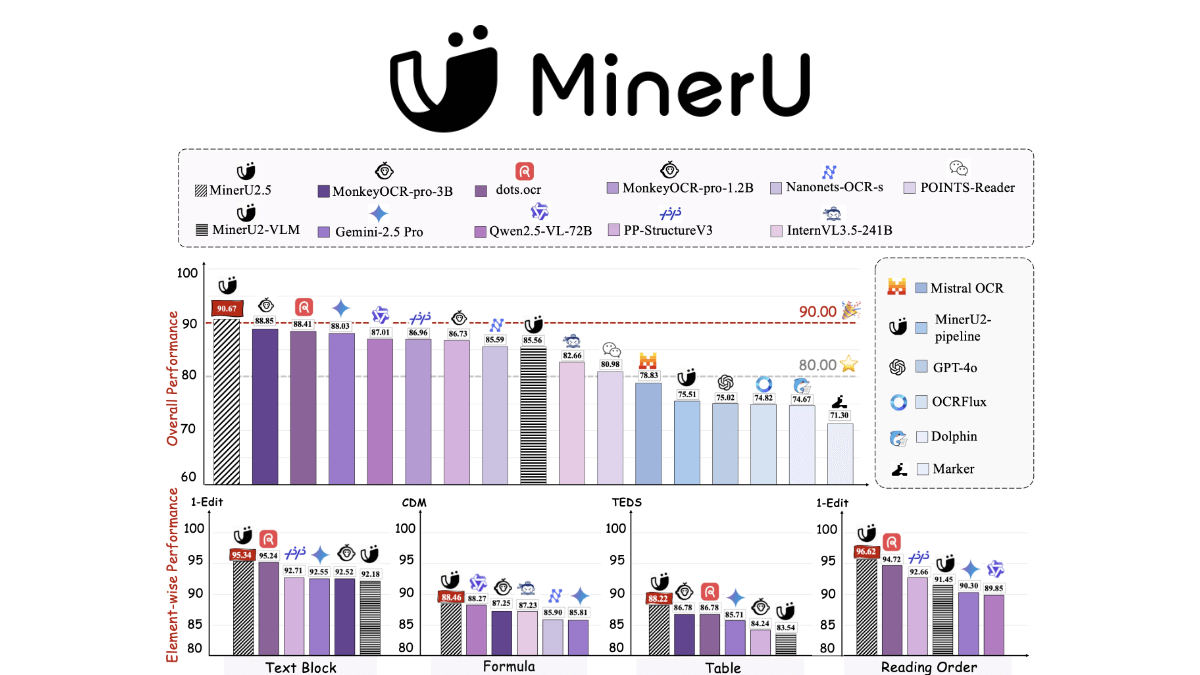
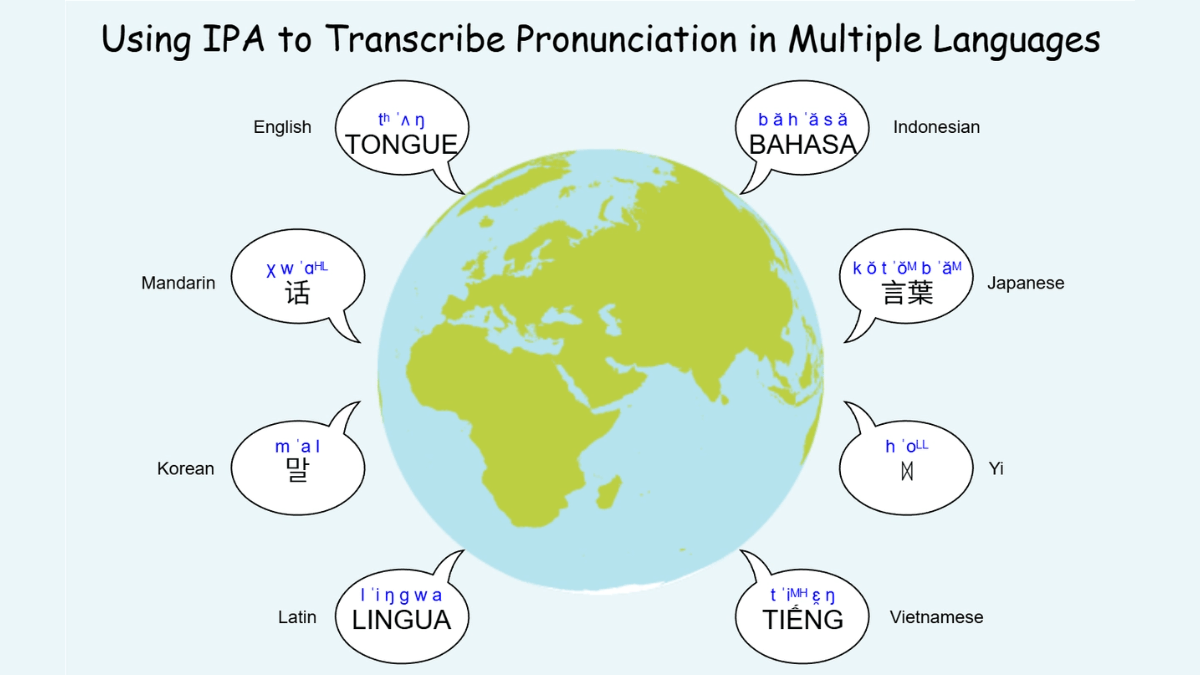
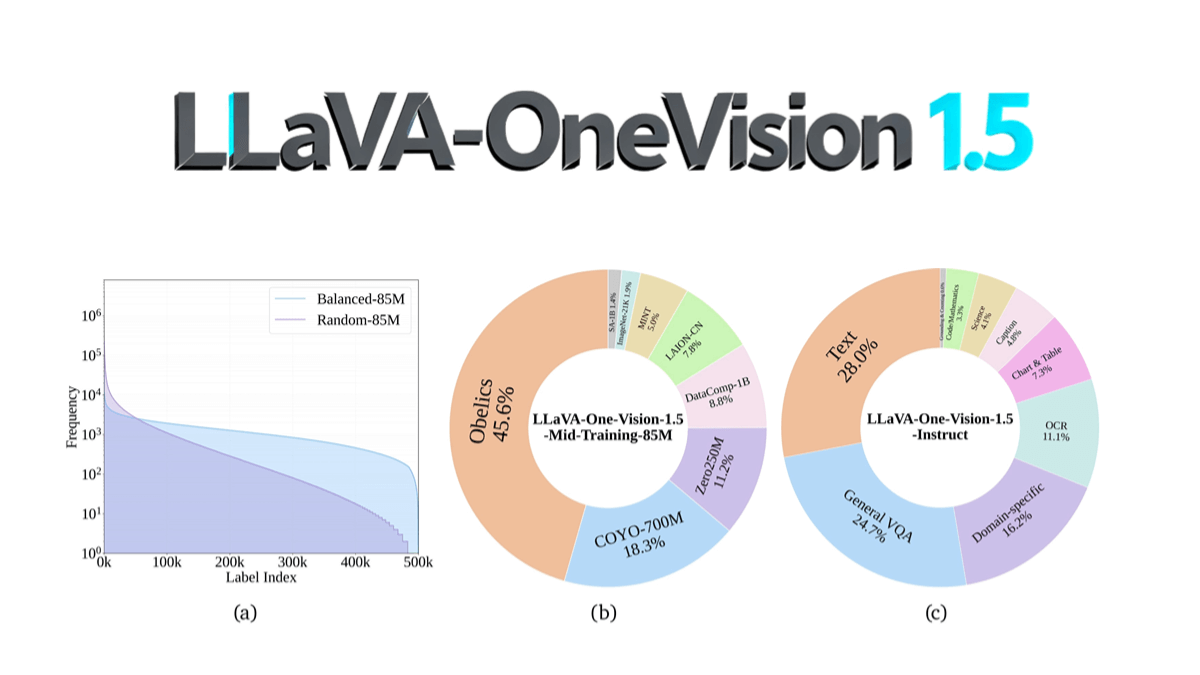
Ovis-Imageは、Alibaba International Digital Commerce GroupのAIDC-AIチームによってオープンソース化された70億パラメータのテキスト生成グラフモデルで、高品質のテキストレンダリングに焦点を当てています。Ovis-U1アーキテクチャに基づき、高度なビジュアルデコーダーと双方向トークン精製機能を継承しています。
LoopToolは、上海交通大学とLittle Red Bookチームによってオープンソース化された自動ツールコールデータ進化フレームワークであり、大規模言語モデルのツールコール機能を強化するために設計されている。オープンソースのモデル(Qwen3-32Bなど)をデータ生成に使用し、クローズドループの繰り返しによってデータ生成とモデル学習を最適化します。
SoulX-Podcastは、高品質のポッドキャストコンテンツを生成するために設計された、Soul AI Labのオープンソースの先進的な複数話者会話音声合成モデルです。SoulX-Podcastは複数ラウンドのダイアログを生成する機能を持ち、実際のポッドキャスティングシナリオでスムーズなダイアログをシミュレートできます。
LongCat-Audio-Codecは、MeituanのLongCatチームによるオープンソースの音声コーデックソリューションです。このソリューションは、Speech Large Language Model (Speech LLM)のために設計されており、意味的・音響的な二重トークン並列抽出メカニズムによって、音声の意味的・音響的特徴を考慮に入れています。