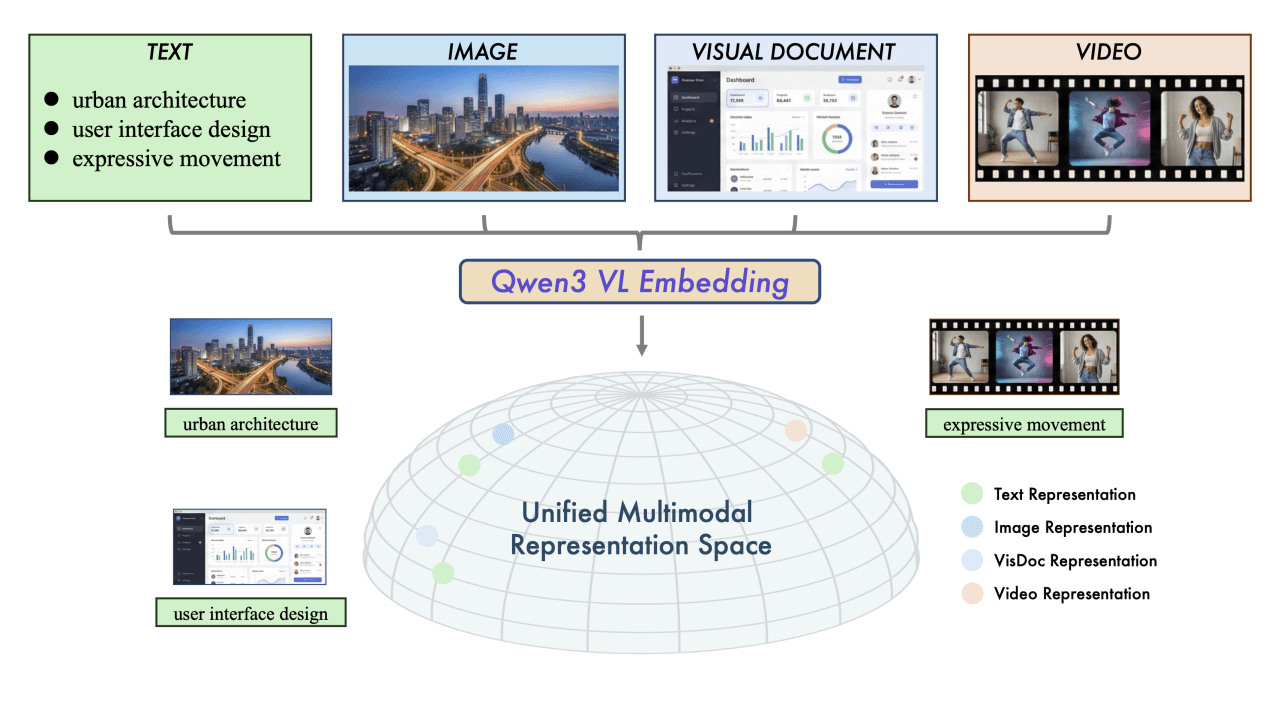
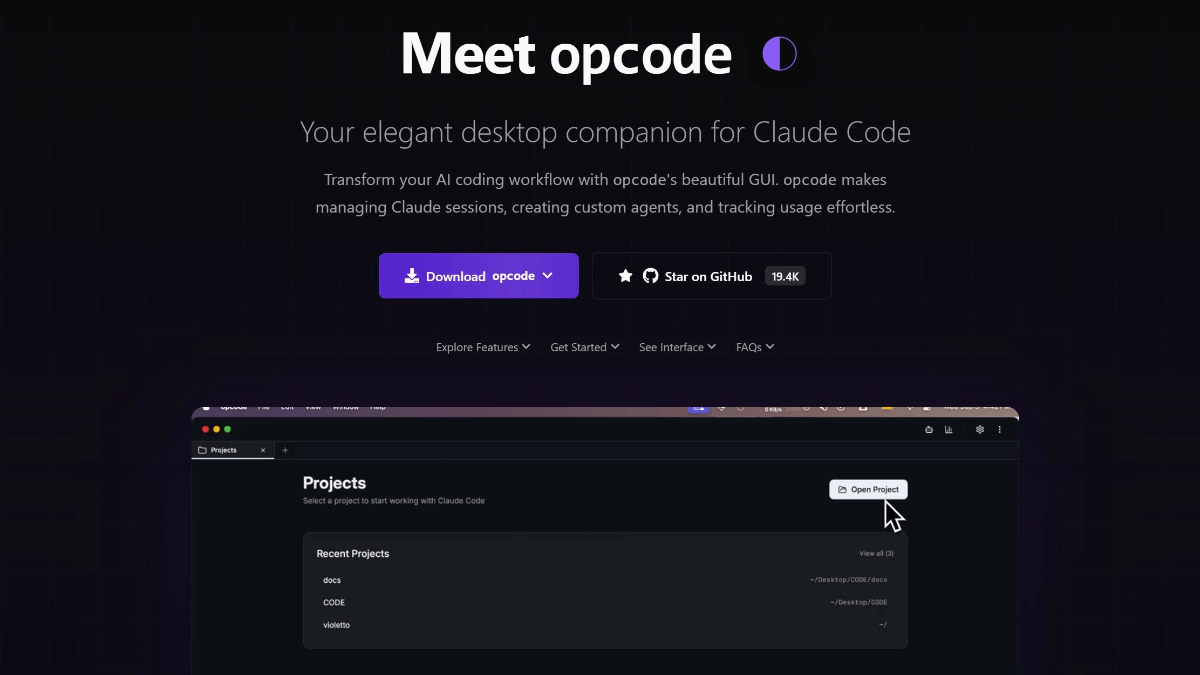
Zen BrowserはFirefoxカーネルをベースとしたオープンソースブラウザで、垂直タブバーやワークスペースの分離などのコア機能を備え、シンプルで効率的なブラウジング体験に焦点を当てています。サイドバーのデザインにより、50以上のタブの完全なタイトルを明確に表示でき、マルチウィンドウの画面分割ブラウジングをサポートします。
ハイブリッド世界モデル1.5(Tencent HY WorldPlay)は、Tencentがリリースした業界初のオープンソースリアルタイム世界モデルフレームワークであり、データ、トレーニング、ストリーミング推論の展開のフルチェーンをカバーする。コアとなるのはWorldPlay自己回帰拡散モデルで、Next-F...
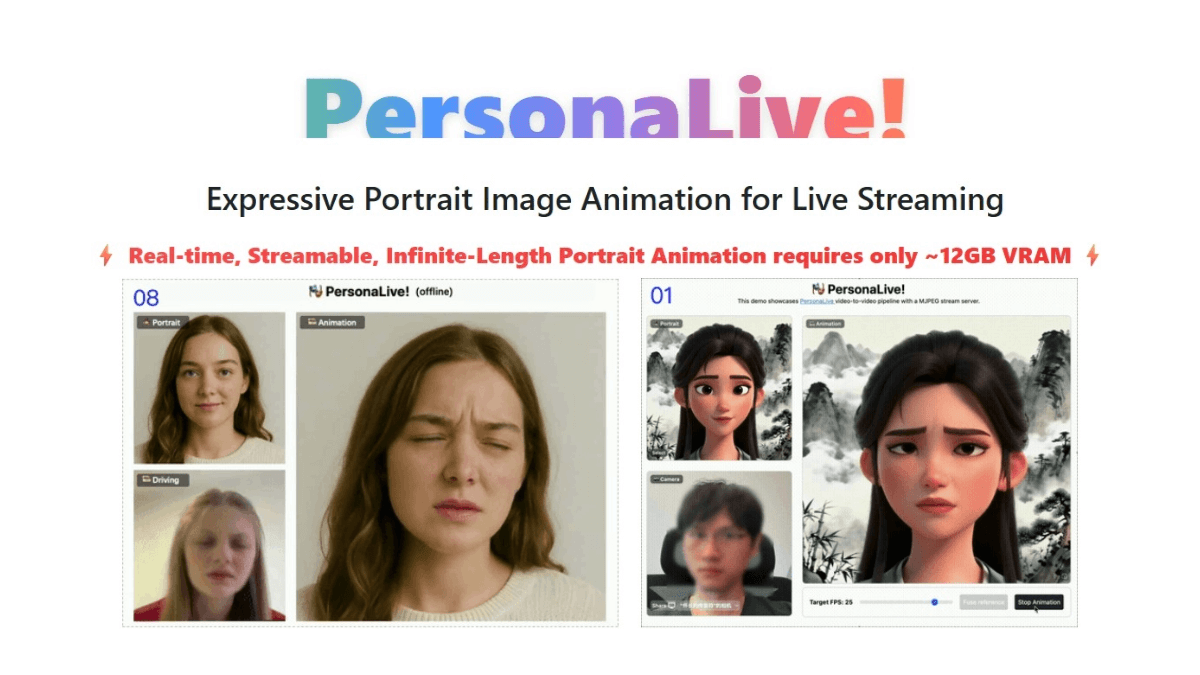
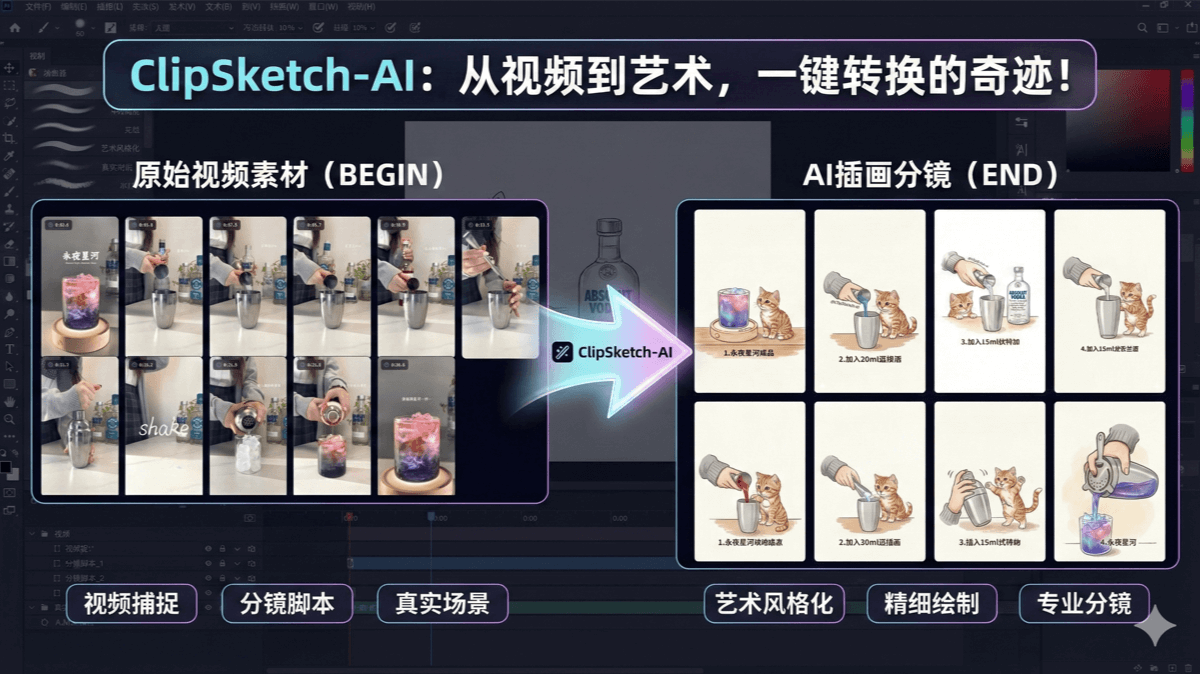
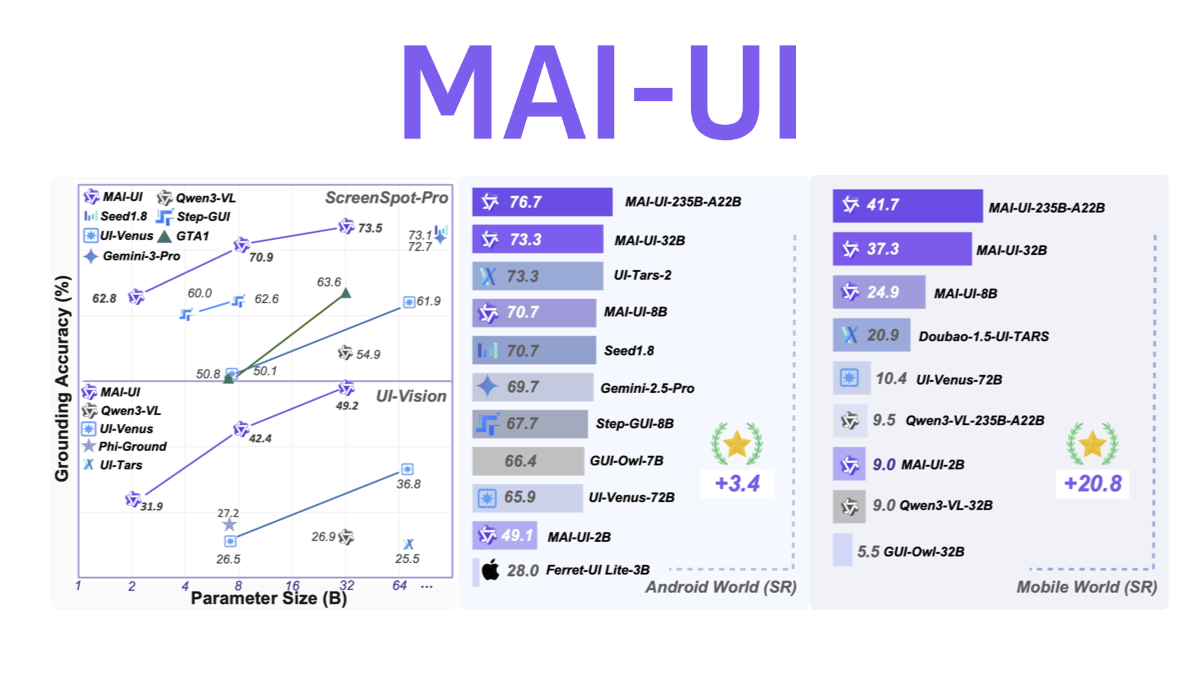
SCAIL(Studio-Grade Character Animation via In-Context Learning)は、Smart Spectrumが清華大学のLiu Yongjin教授のグループと共同で提案した、映画・テレビ用のキャラクターアニメーション生成フレームワークです。このフレームワークを通して...










![FLUX.2 [klein] - Black Forest Labs 开源的轻量级图像生成与编辑模型](https://aisharenet.com/wp-content/uploads/2026/01/1768710007-1768710007-FLUX.2-klein.png)