
SmolDocling:少量で効率的な文書処理のための視覚言語モデル

はじめに
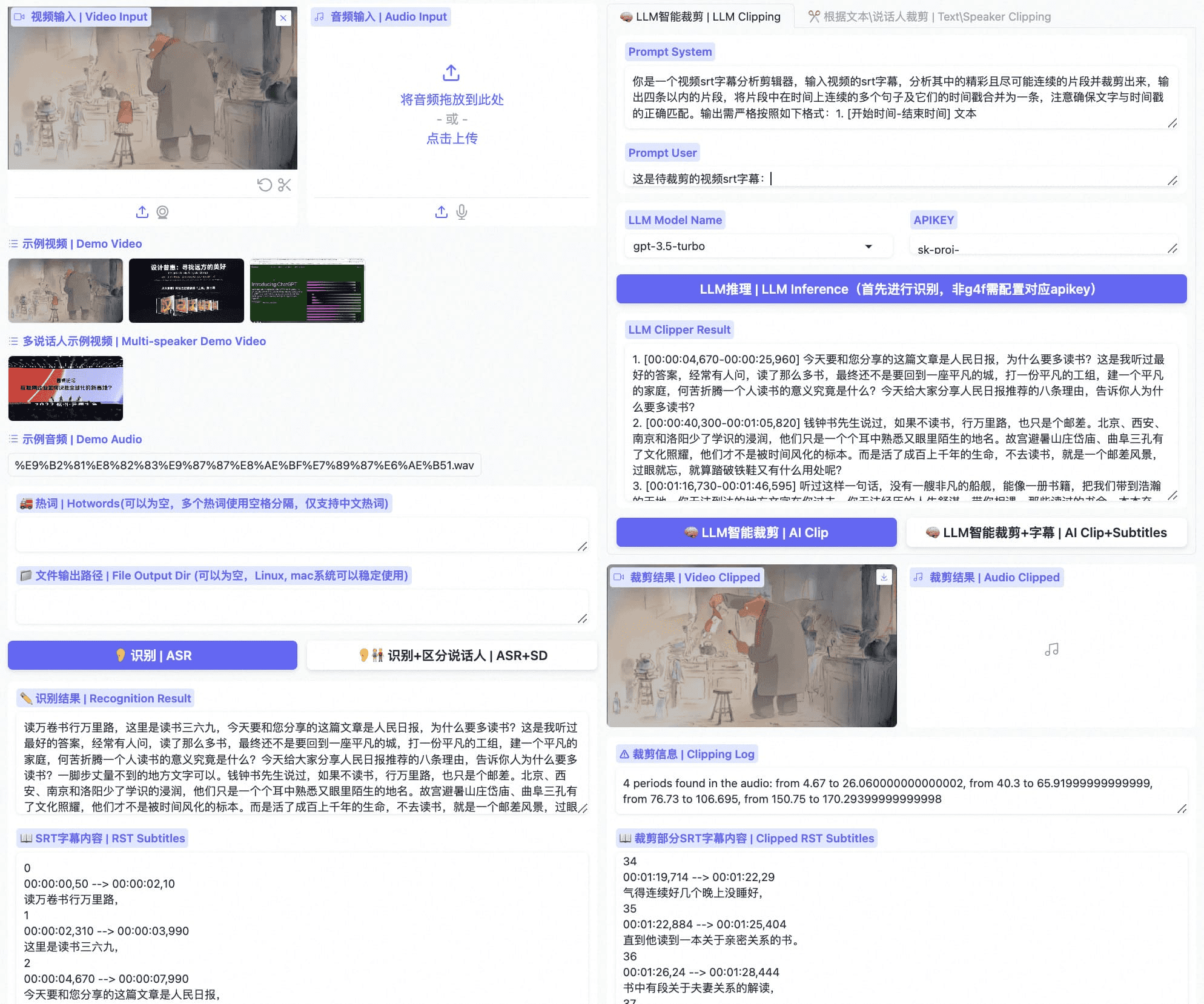
SmolDoclingは、ds4sdチームがIBMと共同で開発したビジュアル言語モデル(VLM)で、SmolVLM-256Mをベースにしており、Hugging Faceプラットフォームでホストされています。わずか256Mのパラメータを持つ世界最小のVLMであり、その中核機能は、画像からテキストを抽出し、レイアウト、コード、数式、図を認識し、DocTags形式の構造化ドキュメントを生成することです。開発チームは、このモデルをオープンソースを通じて共有し、より多くの人々が文書作業に対処できるようにしたいと考えています。SmolVLMファミリーの一部で、文書変換に重点を置いており、複雑な文書を迅速に処理する必要があるユーザーに適しています。


機能一覧
- テキスト抽出(OCR)画像からテキストを認識・抽出。
- レイアウト識別例えば、見出し、段落、表の位置など。
- コード認識コードブロックを抽出し、インデントと書式を保持します。
- 数式認識数式を検出し、編集可能なテキストに変換します。
- チャート認識画像からチャートの内容を解析し、データを抽出します。
- フォーム処理テーブルの構造を特定し、行と列の情報を保持する。
- DocTags出力処理結果を統一されたラベリングフォーマットに変換し、その後の使用を容易にします。
- 高解像度画像処理より高解像度の画像入力に対応し、認識精度を向上。
ヘルプの使用
SmolDoclingの使用は、インストールと操作の2つの部分に分かれています。以下は、ユーザーがすぐに使い始められるよう、詳しい手順です。
設置プロセス
- 環境を整える
- Python 3.8以降がコンピュータにインストールされていることを確認してください。
- ターミナルで以下のコマンドを入力し、依存ライブラリをインストールする:
pip install torch transformers docling_core - GPUをお持ちの場合は、CUDAをサポートしたPyTorchをインストールすることをお勧めします。方法を確認してください:
import torch print("GPU可用:" if torch.cuda.is_available() else "使用CPU")
- 積載モデル
- SmolDoclingは手動でダウンロードする必要はなく、コード経由でハギング・フェイスから直接入手できます。
- ネットワークが開いており、最初の実行時にモデルファイルが自動的にダウンロードされることを確認します。
使用手順
- 写真を準備する
- スキャンした文書やスクリーンショットなど、テキストを含む画像を検索します。
- コードで画像を読み込む:
from transformers.image_utils import load_image image = load_image("你的图片路径.jpg")
- モデルとプロセッサの初期化
- SmolDoclingのプロセッサーとモデルをロードする:
from transformers import AutoProcessor, AutoModelForVision2Seq DEVICE = "cuda" if torch.cuda.is_available() else "cpu" processor = AutoProcessor.from_pretrained("ds4sd/SmolDocling-256M-preview") model = AutoModelForVision2Seq.from_pretrained( "ds4sd/SmolDocling-256M-preview", torch_dtype=torch.bfloat16 ).to(DEVICE)
- SmolDoclingのプロセッサーとモデルをロードする:
- DocTagsの生成
- 入力を設定し、モデルを実行する:
messages = [{"role": "user", "content": [{"type": "image"}, {"type": "text", "text": "Convert this page to docling."}]}] prompt = processor.apply_chat_template(messages, add_generation_prompt=True) inputs = processor(text=prompt, images=[image], return_tensors="pt").to(DEVICE) generated_ids = model.generate(**inputs, max_new_tokens=8192) doctags = processor.batch_decode(generated_ids[:, inputs.input_ids.shape[1]:], skip_special_tokens=False)[0].lstrip() print(doctags)
- 入力を設定し、モデルを実行する:
- 一般的なフォーマットへの変換
- DocTagsをMarkdownや他のフォーマットに変換します:
from docling_core.types.doc import DoclingDocument doc = DoclingDocument(name="我的文档") doc.load_from_doctags(doctags) print(doc.export_to_markdown())
- DocTagsをMarkdownや他のフォーマットに変換します:
- 高度な使用法(オプション)
- 複数ページのドキュメントを扱う複数の画像をループ処理し、DocTagsをマージします。
- パフォーマンスを最適化する設定
torch_dtype=torch.bfloat16メモリ節約、GPUユーザーは有効にできるflash_attention_2加速:model = AutoModelForVision2Seq.from_pretrained( "ds4sd/SmolDocling-256M-preview", torch_dtype=torch.bfloat16, _attn_implementation="flash_attention_2" if DEVICE == "cuda" else "eager" ).to(DEVICE)
操作技術
- 映像条件画像は鮮明でテキストが読みやすいものである必要があり、解像度が高ければ高いほどよい。
- 調整パラメーター結果が不完全な場合は、以下を加える。
max_new_tokens(デフォルト8192)。 - バッチファイル複数の画像をリストとして渡すことができます。
images=[image1, image2]. - 試運転方法中間チェック結果を出力する。
inputs入力が正しいかチェックする。
ほら
- 初回はインターネット接続が必要だが、その後はオフラインでも使用できる。
- 大きすぎる写真はメモリ不足になる可能性があるので、トリミングして対処することをお勧めします。
- エラーが発生した場合は、Pythonのバージョンと依存ライブラリが正しくインストールされているか確認してください。
以上の手順で、ユーザーはSmolDoclingを使って画像を構造化文書に変換することができます。プロセス全体はシンプルで、初心者にもプロフェッショナルユーザーにも適しています。
アプリケーションシナリオ
- 学術研究
スキャンした論文をテキストに変換し、編集や引用が簡単にできるように数式や表を抽出します。 - プログラミング・ドキュメント
コードを含むマニュアル画像をMarkdownに変換し、開発者のためにコードの書式を保持します。 - オフィスオートメーション
契約書や報告書などのスキャンコピーを扱い、レイアウトや内容を認識して効率化を図る。 - 教育支援
教科書の画像を編集可能なドキュメントに変換して、先生や生徒がノートを整理するのに役立ちます。
品質保証
- SmolDoclingとSmolVLMの違いは何ですか?
SmolDoclingはSmolVLM-256Mの最適化バージョンをベースにしており、文書処理とDocTagsフォーマットの出力に重点を置いているのに対し、SmolVLMはより一般的で、画像記述などのタスクをサポートしています。 - どのOSに対応していますか?
Windows、Mac、Linuxがサポートされており、Pythonと依存ライブラリがインストールされた状態で実行できる。 - 処理は速いですか?
画像処理にかかる時間は、通常のコンピューターでは数秒、GPUユーザーならさらに速く、通常は1秒未満だ。 - 手書きのテキストを扱えますか?
しかし、結果は手書きの鮮明さに左右されるため、最良の結果を得るには印刷されたテキスト画像を使用することをお勧めします。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません