データのクロールは難しいですか? Automaプラグインは簡単にあなたを助ける!

こんな悩みはありませんか?「手作業でデータをコピー&ペーストするのは時間がかかりすぎ、非効率的だ」。.;"ウェブページのデータを一括収集したいが、コードの書き方がわからない".;「他のクローラーツールも試したが、複雑すぎて習得にコストがかかる」。.;"クローラーが出入り禁止にならないか心配だし、どう対処していいかわからない".
ご心配なく!今日は、以下の使い方をお教えしましょう。 オートマ この人工物は、データのクロールを簡単かつ効率的にする!
1.Automa:コード不要のデータ収集アシスタント
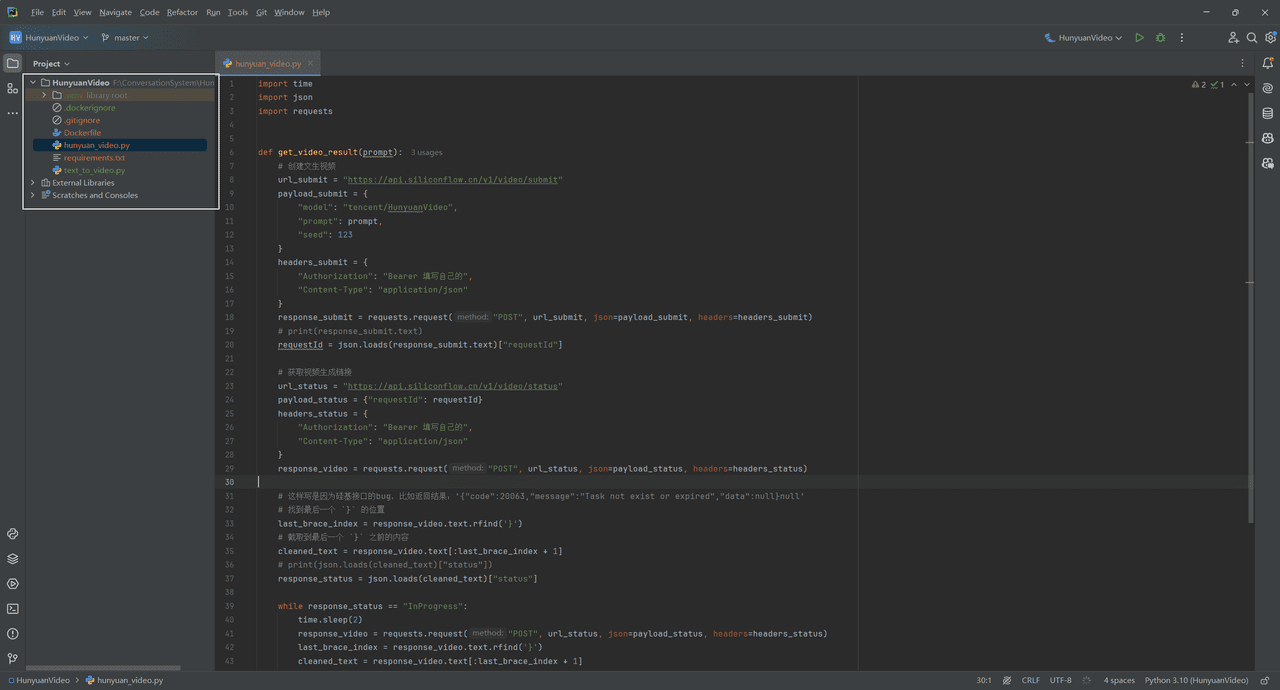
Automaプラグインのインターフェース概要
AutomaはChrome用の強力な自動化プラグインです。次のようなことができます。「ウェブ閲覧の自動化、バッチデータ収集、様々なフォーマットへのデータエクスポート、時間指定タスクの設定。.
最も重要なことだ:"コードを書く必要はまったくなく、ビジュアル・インターフェースから実行するだけだ!"
2.初心者からマスターへ:データ・クローリングの3つのステップ
ステップ1:インストールと基本設定
Chromeショップで「Automa」を検索してインストールし、ブラウザの右上にあるAutomaアイコンをクリックして、新しいワークフローを作成する。
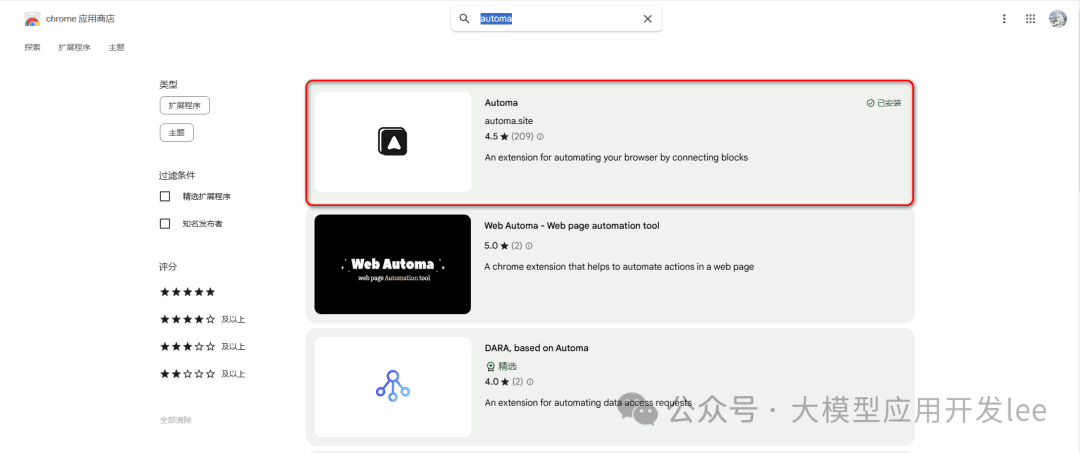
Chromeストアのインストール画面
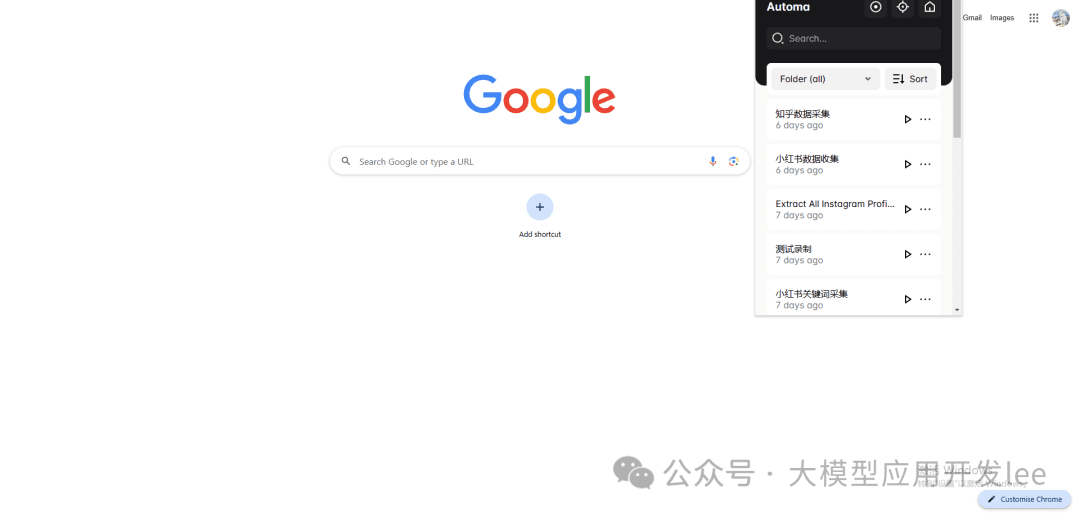
Automaプラグインの場所
ワークフロー作成画面
ステップ2:ワークフローの設計
eコマースの商品データのクロールを例にとってみよう。「コア・ステップ含まれている:「スタートページの設定、ページングを処理するループブロックの追加、商品情報の抽出、そして最後にデータのエクスポート」。.
ステップ3:実行と最適化
データ収集の安定性と効率性を確保するために「ページの読み込みが完了するまでの待ち時間として、適切な遅延時間を設定する必要があります」。.同時に重要なのは"意図しない中断を防ぐためのエラー処理メカニズムを追加する".
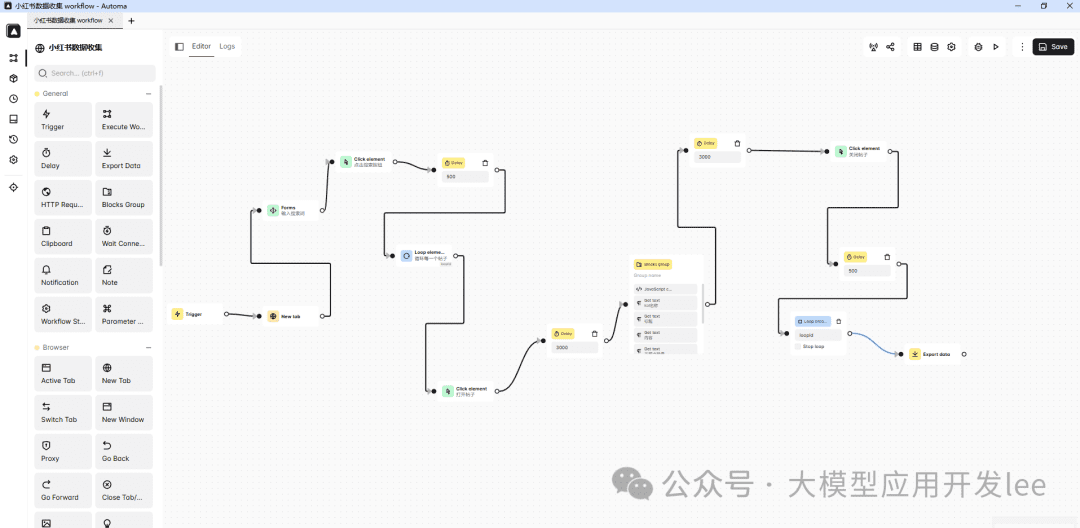
3.実践事例:小型サツマイモのホットポストデータ収集
オートマコアコンセプトノート
本題に入る前に、Automaの核となるコンセプトをいくつか確認しておこう:
- ワークフローワークフロー): タスクフロー全体のコンテナ
- ブロック:各機能モジュール
- セレクタ:ウェブページ上の要素を配置するためのツール。
- 変数:一時的なデータを格納する。
- トリガー(Trigger):ワークフローを開始させる条件。
- 表:データを収集・整理するための書式。
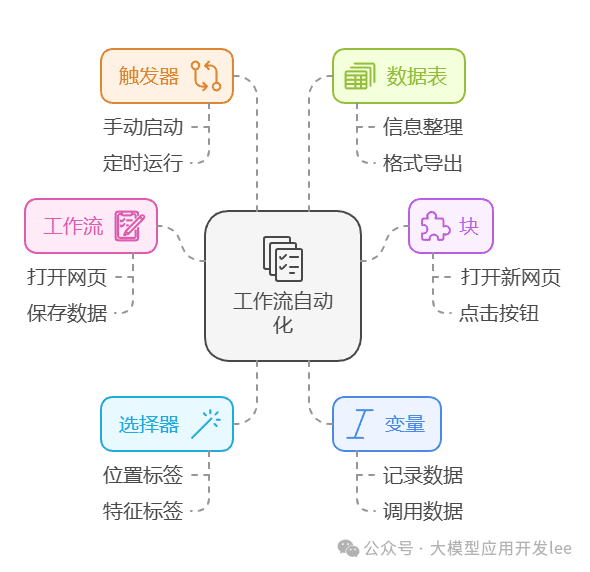
ワークフロー・オートメーションの基本概要
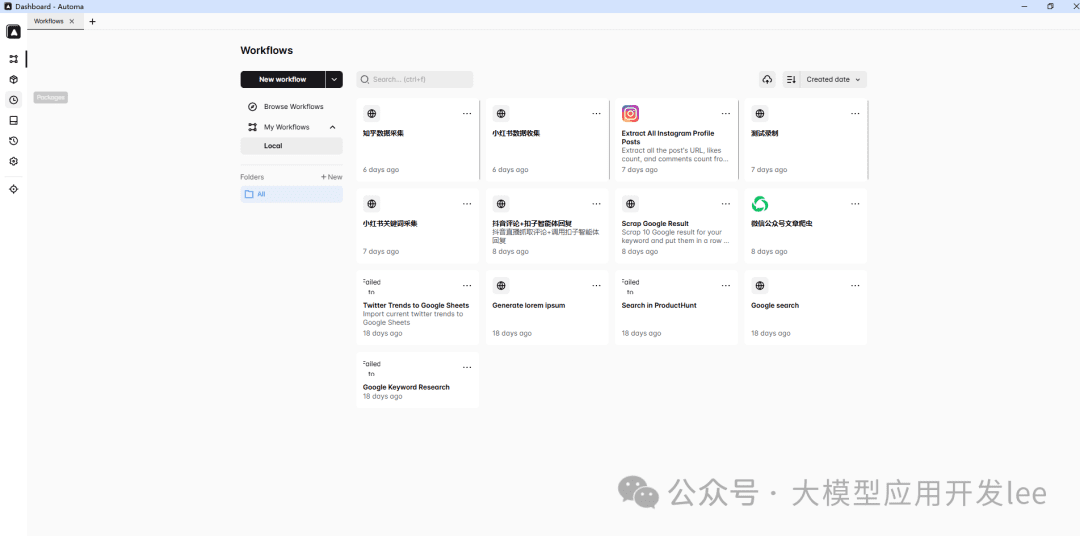
ケーススタディ
Little Sweet Potatoホットノートのデータ収集を例に、Automaを使ってホットノートデータを収集する方法を見てみよう。その核心は、自分たちで手作業で収集し、Automaを使って自動化するプロセスを模倣することだ。
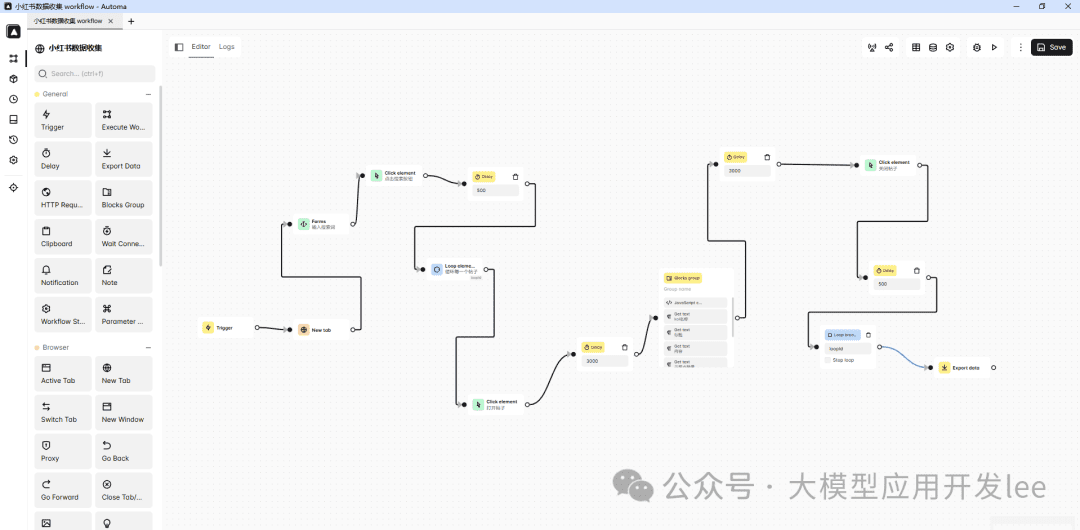
リトルレッドブックのデータ収集プロセス
まず、Automaを使ってリトルレッドブックのデータを収集する方法を見てみよう。全体の流れは以下のステップに分かれる。
ワークフローの作成とトリガーの設定
Xiaohongshu Data Collection」というワークフローを作成する。トリガーに "key_word "というパラメータを追加する。このパラメータのデフォルト値は "independent developer "に設定されている。
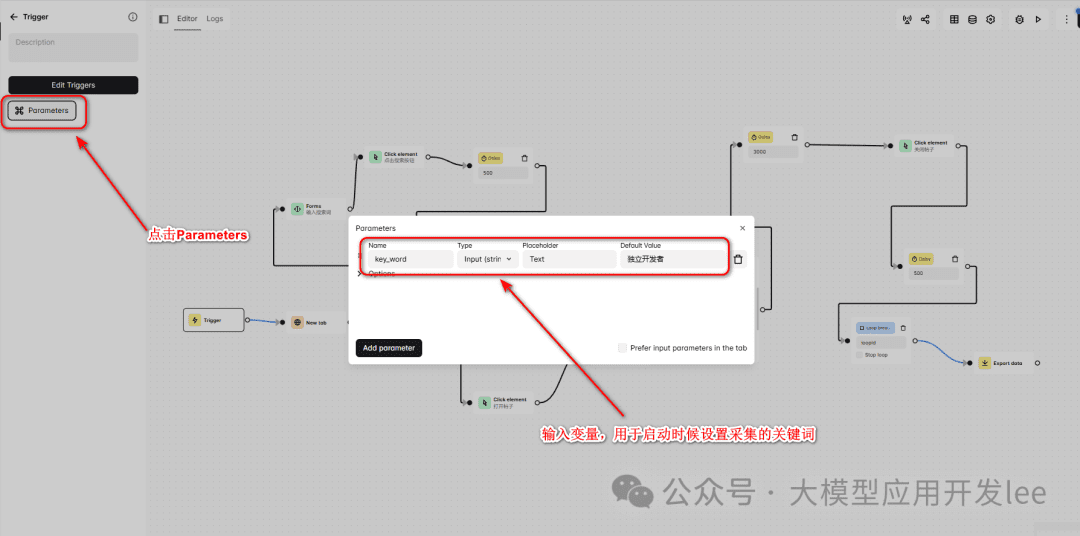
トリガー設定
対象ページを開き、検索する
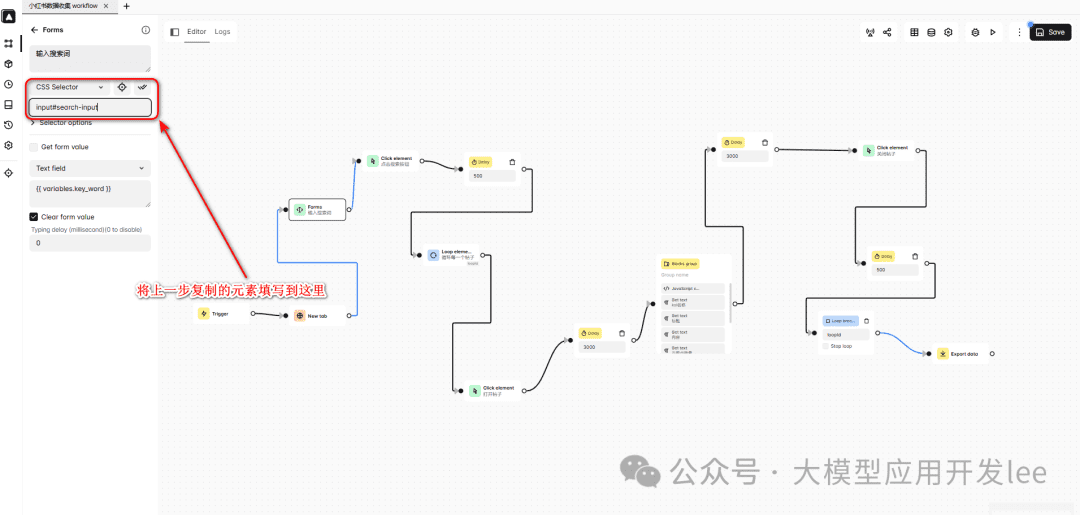
New Tabブロックを使ってリトルレッドブックのホームページ(https://www.xiaohongshu.com/explore)を開きます。次に、Formsブロックを使って検索ボックスを配置します。
要素への選択方法
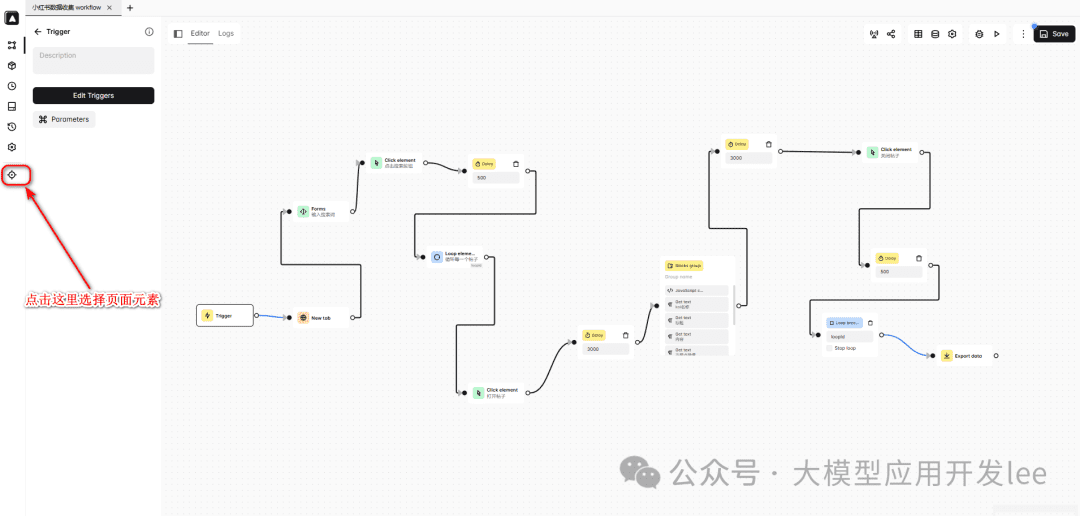
- ダッシュボードのサイドバーで以下のアイコンを見つけて、要素を選択するページにアクセスする。

セレクタ取得
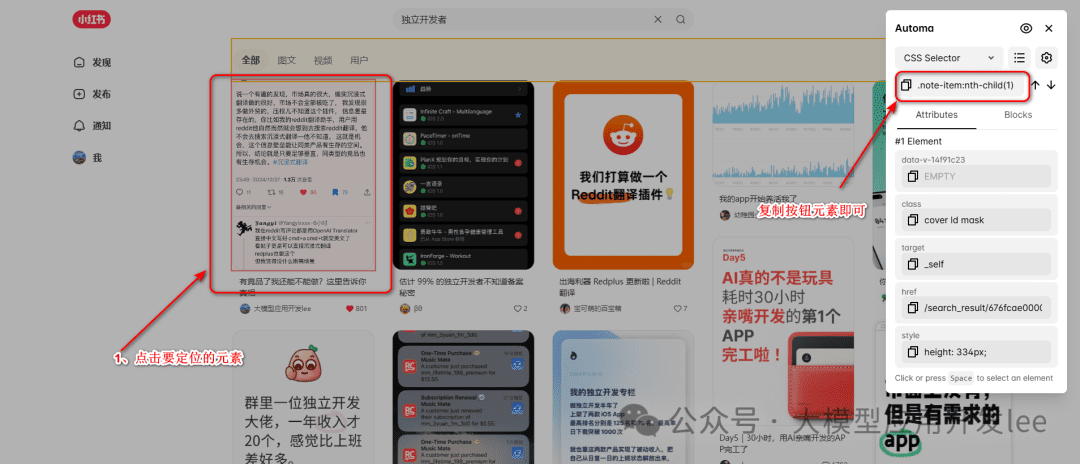
- キャプチャページの要素を選択し、右上のコピーボタンをクリックします。
コピーセレクター
- 前のステップで選択した要素をAutomaのCss Selcetorに貼り付ける。
ペーストセレクター
周期的データ収集
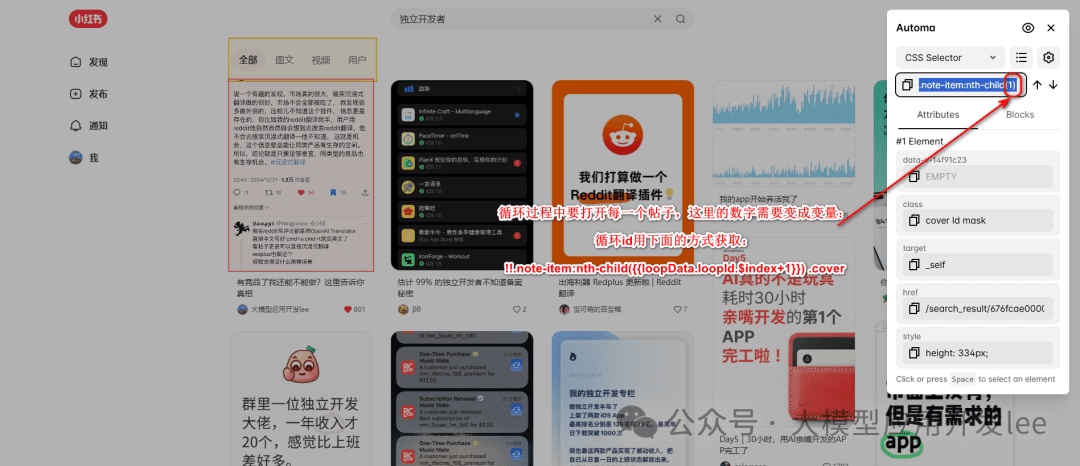
ループ要素ブロックを使って音符のリストを反復処理する。音符リストのセレクタを取得する必要がある:
- ノート一覧ページで、いずれかのノートカバーを右クリックします。
- Automa セレクタ取得ツールでセレクタ「.note-item .cover」を取得する。
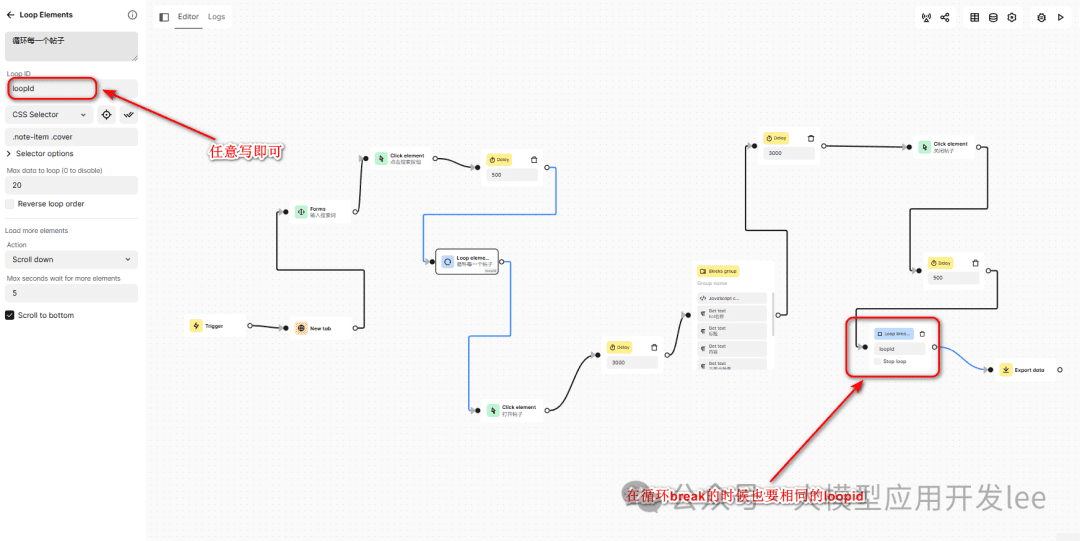
サイクル構成
ポストを開いて詳細を見る
ループの中で、各ノートをクリックして詳細ページに移動する必要がある。ここでは以下の点に注意する必要がある。
- "ページの読み込みを待つ"Wait Elementブロックを使って、ページが完全にロードされるようにする。
- "ノートの表紙をクリック"クリック要素ブロックを使って、それぞれの音符のカバーをクリックします。
- 「詳細ページがロードされるまで待つWait Elementブロックを使用して、詳細ページが完全にロードされるようにします。
オープン・エレメント概略図
各ループで収集されたデータセレクタの取得方法:
- KOL名:著者名を右クリック>チェック>セレクタ "a.name "をコピー
- ノートタイトル:セレクタ "div#detail-title"
- ノート内容:セレクタ "#detail-desc > .note-text > span"
- インタラクティブなデータ。
- いいね!: ".left > .like-wrapper > .count"
- コレクション数: "#note-page-collect-board-guide > .count"
- コメント数: ".chat-wrapper > .count"
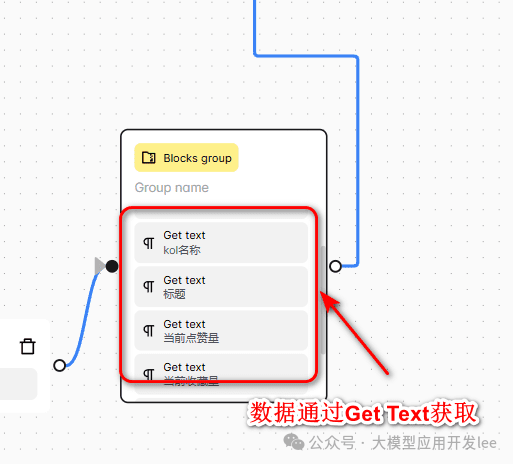
セレクタの例
輸出データ
最後に、Export Dataブロックを使用して、収集したデータをCSV形式でエクスポートします。
チップ
- セレクタが正確でない場合は、XPathを使ってみてください。
- ページがロードされるのを待つために適切なディレイを追加する。
- セレクターの故障を定期的にチェック
- 一度に収集するデータは20個までとすることが推奨される。
- 回収頻度を管理し、頻繁に回収しない
ワークフロー全体は、合理的な遅延制御とセレクタの位置決めにより、データ収集タスクを安定的に完了することができます。同時に、パラメータ化された構成を通して、異なるニーズに従って収集キーワードを調整することが便利です。
4.よくある質問と解決策
ダイナミック・セレクタの説明
似たような要素を複数集める場合、ダイナミック・セレクタを使う必要があることがよくある。実例を通して学んでみましょう。
このセレクタを例にとってみよう。
!!.note-item:nth-child({{loopData.loopId.$index+1}}) .cover
このセレクタは複雑に見えるので、ステップごとに分解してみよう。
!! プレフィックスは、CSSセレクタの代わりにJavaScriptセレクタを使用するためのAutomaの特別な構文で、より柔軟な選択メソッドを使用できるようにします。
.note-itemクラス "note-item "を持つ要素を選択します。これは通常、リスト内の各投稿のコンテナです。
:nth-child()はCSSのサブ要素セレクタで、特定の位置にあるサブ要素を選択するために使用される。
{{loopData.loopId.$index+1}}正鵠を得る{{}}はオートマの変数構文でありloopData.loopId.$indexはループ内の現在のインデックス(0から始まる)、そして+1それは:nth-child1から数え始める。
.cover最終的なターゲット要素(この場合は投稿のカバー画像)を選択します。
ループ・ブロックは次のように設定する。
{
selector: "!!.note-item:nth-child({{loopData.loopId.$index+1}}) .cover",
timeout: 5000
}
なぜこのように書かれているのか?ダイナミックなポジショニングが可能になるからだ。
- 第1サイクル
.note-item:nth-child(1) .cover - 第2サイクル
.note-item:nth-child(2) .cover - 第3サイクル
.note-item:nth-child(3) .cover - などなど
これにより、固定セレクタの問題を回避できる。
/* 错误写法 */
.note-item .cover // 会选中所有cover元素
/* 正确写法 */
!!.note-item:nth-child({{loopData.loopId.$index+1}}) .cover // 精确选择当前循环的元素
セレクタが正しいかどうかわからない場合は、ブラウザのコンソールでテストすることができる。
// 假设当前是第3次循环
document.querySelector('.note-item:nth-child(3) .cover')
Automaのログ機能も使用できます。
{
type: "log",
message: "当前选择器: .note-item:nth-child({{loopData.loopId.$index+1}}) .cover"
}
この動的セレクタのアプローチによって、各ループでターゲット要素を正確に特定し、間違った要素を選択することを避け、ワークフローの安定性と精度を向上させることができます。セレクタの記述はデータ収集において最も重要な部分のひとつであり、動的セレクタを合理的に使用することで、ワークフローをより堅牢で信頼性の高いものにすることができます。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事




コメントはありません