Seed-VC:少ないサンプル数で音声と歌のリアルタイム変換に対応

はじめに
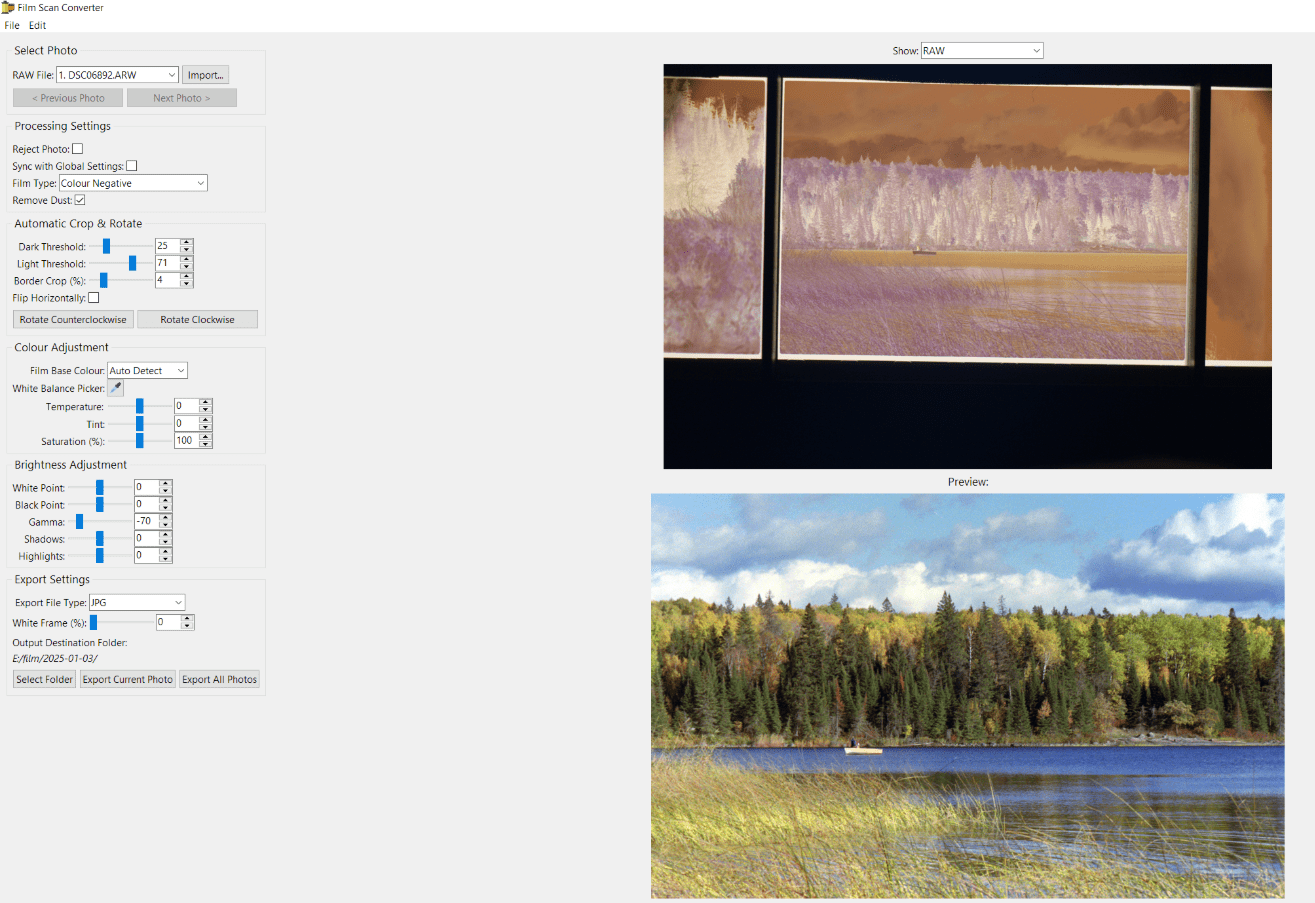
Seed-VCは、Plachtaaによって開発されたGitHub上のオープンソースプロジェクトです。1秒から30秒のリファレンス音声を使用することで、追加トレーニングなしで音声や曲の変換を素早く行うことができます。Seed-VCは、音声変換(VC)、曲変換(SVC)、リアルタイム変換の3つのモードを提供します。使用方法 ウィスパー やBigVGANなどの技術を駆使し、クリアなサウンドを実現している。コードは無料で公開されており、ユーザーはダウンロードしてローカルでビルドすることができます。公式アップデート、詳細なドキュメント、活発なコミュニティサポート。

機能一覧
- ゼロサンプル変換をサポート:短い音声でターゲットの声や歌を模倣します。
- リアルタイム音声処理:マイク入力後、音声が瞬時に目標トーンに変わります。
- 歌声変換:任意の曲を指定した歌手の歌声に変換します。
- 音声の長さ調整:テンポをコントロールするために、音声を速くしたり遅くしたりします。
- ピッチ調整:ターゲット・トーンに合わせてピッチを自動または手動で調整。
- ウェブ・インターフェイス操作:シンプルなグラフィカル・インターフェイスで使いやすい。
- カスタムトレーニングのサポート:少ないデータ量で特定のサウンドを最適化。
- オープンソースコード:ユーザーが変更またはアップグレード可能な機能。
ヘルプの使用
設置プロセス
Seed-VCをローカルで使用するには、まず環境をインストールする必要があります。以下は、Windows、Mac(Mシリーズチップ搭載)、Linux用の詳細な手順です。
- 環境を整える
- Python 3.10をインストールするには、公式サイトからダウンロードしてください。
- Gitをインストールするには、Windowsユーザーなら "Git for Windows "を、Macユーザーならbrew install git for Macを検索する。
- GPUユーザーは、CUDA 12.4と対応するドライバーをインストールする必要があります。
- オーディオ処理用のFFmpegをインストールするには、Windowsの場合は公式サイトからダウンロードし、Macの場合はbrewでffmpegをインストールし、Linuxの場合はパッケージマネージャーでインストールする。
- ダウンロードコード
- コマンドライン(Windowsの場合はCMDまたはAnaconda Prompt、Mac/Linuxの場合はTerminal)を開く。
- git clone https://github.com/Plachtaa/seed-vc.git と入力してプロジェクトをダウンロードする。
- ディレクトリに移動: cd seed-vc .
- 仮想環境の設定
- python -m venv venvと入力してスタンドアロン環境を作る。
- 環境を活性化させる:
- Windows: venvScriptsactivate
- Mac/Linux:ソース venv/bin/activate
- 成功については(venv)を参照。
- 依存関係のインストール
- Windows/Linux pip install -r requirements.txt と入力する。
- Mac Mシリーズは、pip install -r requirements-mac.txt と入力してください。
- ネットワーク問題のためにミラーリングを追加する: HF_ENDPOINT=https://hf-mirror.com pip install -r requirements.txt .
- ランニングプログラム
- 音声変換: python app_vc.py
- 曲の変換: python app_svc.py
- リアルタイム変換: python real-time-gui.py
- 実行すると、ブラウザはインターフェイスを使うためにhttp://localhost:7860。
主な機能
1.音声変換(VC)
- 動く::
- python app_vc.pyを実行し、ブラウザでhttp://localhost:7860。
- オリジナルのオーディオ(Source Audio)とリファレンスオーディオ(Reference Audio、1~30秒)をアップロードします。
- Diffusion Stepsを設定する。デフォルトは25だが、より良い音質を得るには30〜50に設定する。
- 長さを調整し、1より小さいと速くなり、1より大きいと遅くなる。
- Submitをクリックして数秒待ち、変換結果をダウンロードする。
- 銘記する::
- 最初の実行では、seed-uvit-whisper-small-wavenetモデルが自動的にダウンロードされます。
- リファレンス音声は30秒後にカットされる。
2.歌声変換(SVC)
- 動く::
- python app_svc.pyを実行してウェブインターフェースを開く。
- 曲のオーディオと歌手のリファレンス・オーディオをアップロードする。
- 曲のピッチを維持するためにf0コンディションを刻む。
- オプションのauto-f0-adjust ピッチを自動的に調整します。
- 拡散ステップ数を30~50に設定し、Submitをクリックする。
- 技術::
- 最高の結果を得るためには、クリアでバックグラウンドノイズのないリファレンスオーディオを使用してください。
- モデルはデフォルトでseed-uvit-whisper-baseをダウンロードします。
3.リアルタイム変換
- 動く::
- python real-time-gui.pyを実行してインターフェースを開く。
- リファレンスオーディオをアップロードし、マイクを接続します。
- 設定パラメーター:拡散ステップ4~10、ブロックタイム0.18秒。
- スタート」をクリックすると、話しながらリアルタイムで音声が変化する。
- VB-CABLE を使って出力をバーチャルマイクにルーティングする。
- リクエスト::
- GPU推奨(例:RTX 3060)のレイテンシは約430ミリ秒。
- CPUの動作待ち時間が長くなる。
4.コマンドライン操作
- スピーチ変換例::
python inference.py --source input.wav --target ref.wav --output ./out --diffusion-steps 25 --length-adjust 1.0 --fp16 True
- 曲の変換例::
python inference.py --source song.wav --target singer.wav --output ./out --diffusion-steps 50 --f0-condition True --semi-tone-shift 0 --fp16 True
5.カスタマイズされたトレーニング
- 動く::
- 1~30秒の音声ファイル(.wav/.mp3など)をフォルダに用意する。
- ランのトレーニング:
python train.py --config configs/presets/config_dit_mel_seed_uvit_whisper_base_f0_44k.yml --dataset-dir ./data --run-name myrun --max-steps 1000
- トレーニング後のチェックポイント ./runs/myrun/ft_model.pth .
- カスタムモデルを使った推論
python app_svc.py --checkpoint ./runs/myrun/ft_model.pth --config configs/presets/config_dit_mel_seed_uvit_whisper_base_f0_44k.yml
- 銘記する少なくとも1つのオーディオサンプルをトレーニングに使用し、100ステップで約2分(T4 GPU)。
補注
- モデルの選択::
- seed-uvit-tat-xlsr-tiny(25Mパラメータ)を使用したリアルタイム。
- seed-uvit-whisper-small-wavenet(98Mパラメータ)によるオフライン音声。
- ボーカルには、seed-uvit-whisper-base(200Mパラメータ、44kHz)を使用する。
- テスト中にコンポーネントを調整する::
- ModuleNotFoundError エラーを報告してください。
- MacでリアルタイムGUIを実行するには、TkinterがインストールされたPythonが必要かもしれない。
アプリケーションシナリオ
- エンターテイメント・ダビング
声をアニメのキャラクターに変えて、面白いビデオを作ろう。 - 音楽制作
普通のボーカルをプロフェッショナルなシンガートーンに変換し、曲のデモを生成します。 - ライブ・インタラクション
キャスターはリアルタイムで声を変え、番組の面白さを高めている。 - 語学学習
ネイティブスピーカーのスピーチを真似て発音練習をする。
品質保証
- 大量のデータが必要ですか?
変換に必要な短いオーディオクリップは1つ、トレーニングに必要なサンプルは1つだけです。 - 中国語のオーディオをサポートしていますか?
サポートします。リファレンス音声が中国語である限り、変換もクリアです。 - 高遅延についてはどうですか?
GPUを使用し、低拡散ステップ(4-10)を設定する。 - 音質の悪さについては?
拡散ステップを50に増やすか、クリーンなリファレンスオーディオを使用する。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません