PP-OCRv5 - 百度の次世代テキスト認識用オープンソースAIモデル

PP-OCRv5とは
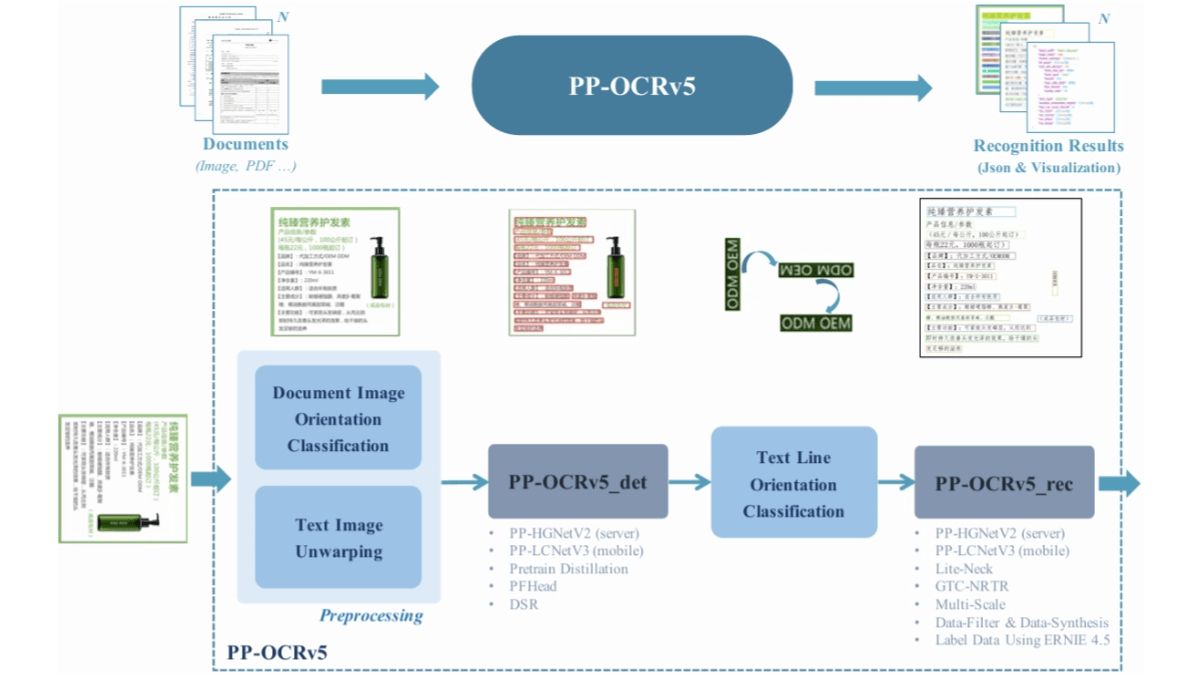
PP-OCRv5は、百度がリリースした最新世代のテキスト認識AIモデルである。軽量設計とわずか0.07Bの参照数で、CPUやエッジデバイスでの効率的な実行に適しており、1秒間に370文字以上を処理できる。このモデルは、簡体字中国語、繁体字中国語、英語、日本語、ピンインを含む5種類のテキストをサポートし、40以上の言語を認識できるため、多言語文書処理に適しています。PP-OCRv5は、画像前処理、テキスト検出、テキスト行方向分類、テキスト認識の4つのコアコンポーネントを含む、モジュール式の2フェーズプロセスを採用しています。PP-OCRv4と比較して、手書き中国語検出、古文書検出、縦書きテキスト認識、隠し文字認識、手書き英語認識などのシナリオの精度が、それぞれ13.8%、43%、71%、96%、118%向上しました。OCRv5は、バックボーンネットワークをアップグレードし、デュアルブランチアーキテクチャを採用し、PDFや電子書籍などの文書から高品質の注釈データを得るために、アテンションメカニズムとCTC損失を組み合わせることにより、データ構築戦略を最適化しました。
PP-OCRv5の特徴
- 軽量設計参照カウントはわずか0.07Bで、CPUやエッジデバイスでの効率的な動作に適しており、モバイル版ではCPUのIntel Xeon Gold 6271Cで毎秒370文字以上の処理が可能で、大量のテキストデータを高速に処理できる。
- 多言語サポート簡体字中国語、繁体字中国語、英語、日本語、ピンインの5種類のテキストをサポートし、40以上の言語を認識することができるため、多言語文書処理に適しており、異なる言語環境におけるテキスト認識のニーズに応えることができる。
- 高精度の認識PP-OCRv4と比較して、手書き中国語検出、古文書検出、縦書き文字認識、隠し文字認識、手書き英語認識などのシナリオにおいて、それぞれ13.81 TP3T、431 TP3T、711 TP3T、961 TP3T、1,181 TP3Tの精度が向上しており、様々な種類のテキストを正確に認識することができます。様々な種類のテキストをより正確に認識できるようになりました。
- 正確なテキスト配置正確なテキスト行のバウンディングボックス座標を提供することは、構造化データ抽出とコンテンツ分析の重要な要件であり、その後のテキスト処理と分析作業に役立ちます。
- 単一モデルによる多言語認識このモデルは、1つのモデルで5種類のテキストをサポートする業界初の超軽量(100M未満)オープンソースモデルです。 統一されたモデルアーキテクチャにより、5種類のテキストのシームレスな認識を実現し、テキストタイプごとに独立したモデルを導入する必要がなくなり、導入プロセスが簡素化されるとともに、全体的な認識精度と速度が向上します。
- 複雑なシナリオへの高い適応力中国語や英語の複雑な手書き文字、縦書き文字、珍しい文字など、さまざまな困難なシナリオの認識をサポートし、さまざまな複雑なテキスト形式や内容に対応できるため、モデルの汎用性と実用性が向上しています。
- バックボーン・ネットワークのアップグレードPP-HGNetV2をバックボーンとする2ブランチアーキテクチャを採用し、一方のブランチは配列モデリングを強化するためにアテンションベースのトレーニングを使用し、もう一方のブランチはCTC損失を使用した効率的な推論に重点を置いている。トレーニング時には2つのブランチが互いに連携するが、予測時には軽量ブランチのみを使用することで、精度とスピードを確保している。
- データ構築戦略の最適化従来のモデルをERNIE - 4.5 - VL - 424B - A47Bと組み合わせることで、合成によって生成された希少文字を含む高品質の手書きサンプルに自動的に注釈を付け、フィルタリングすることができます。PDFや電子書籍などの文書から大規模な注釈付きデータを自動構文解析と編集距離フィルタリングによって取得し、モデルの全体的な性能のための強固なデータ基盤を構築します。
PP-OCRv5の主な利点
- 軽量設計モデルのパラメータ数はわずか0.07Bで、CPUやエッジデバイスでより高いパフォーマンスを実現。モバイル版では、Intel Xeon Gold 6271C CPUで毎秒370文字以上の処理が可能。
- 高精度の認識Gemini 2.5 Pro、Qwen2.5-VL、GPT-4oなどの汎用の視覚言語モデルを、手書きや印刷の中国語、英語、ピンインテキストを含むOCR固有のベンチマークで凌駕しています。
- 多言語サポート簡体字中国語、繁体字中国語、英語、日本語、ピンインの5種類のテキストをサポートし、40以上の言語を認識できる。
- 正確なテキスト配置正確なテキスト行のバウンディングボックス座標を提供することは、構造化データ抽出とコンテンツ分析の重要な要件です。
PP-OCRv5公式サイトとは?
- プロジェクトのウェブサイト:: https://huggingface.co/blog/baidu/ppocrv5
- HuggingFaceモデルライブラリ:: https://huggingface.co/collections/PaddlePaddle/pp-ocrv5-684a5356aef5b4b1d7b85e4b
PP-OCRv5は誰のためのものですか?
- エンタープライズ・デベロッパー金融業界、医療業界、教育業界など、業務システムに高効率なテキスト認識機能を組み込む必要がある企業では、契約書の解析、カルテの電子化、試験問題の添削などのシーンで活用できる。
- (研究者コンピュータビジョン、自然言語処理、その他の人工知能分野の研究者は、学術研究やモデル比較のためにPP-OCRv5を使用することができます。
- ソフトウェア開発者モバイルアプリケーションやデスクトップソフトウェアなど、テキスト認識機能を必要とするアプリケーションの開発者は、PP-OCRv5を迅速に統合して機能を実現することができます。
- データアナリスト大量の文書から構造化データを抽出し、テキストデータの迅速な処理と分析を必要とするデータアナリスト。
- 教育者生徒の課題やテスト用紙など、手書きの文章を処理・分析する必要のある教師は、自動添削や内容分析に利用できる。
- ファイルマネージャ大量の紙文書を管理し、デジタル化するアーキビストのためのもので、文書の識別と分類を素早く行うことができる。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません