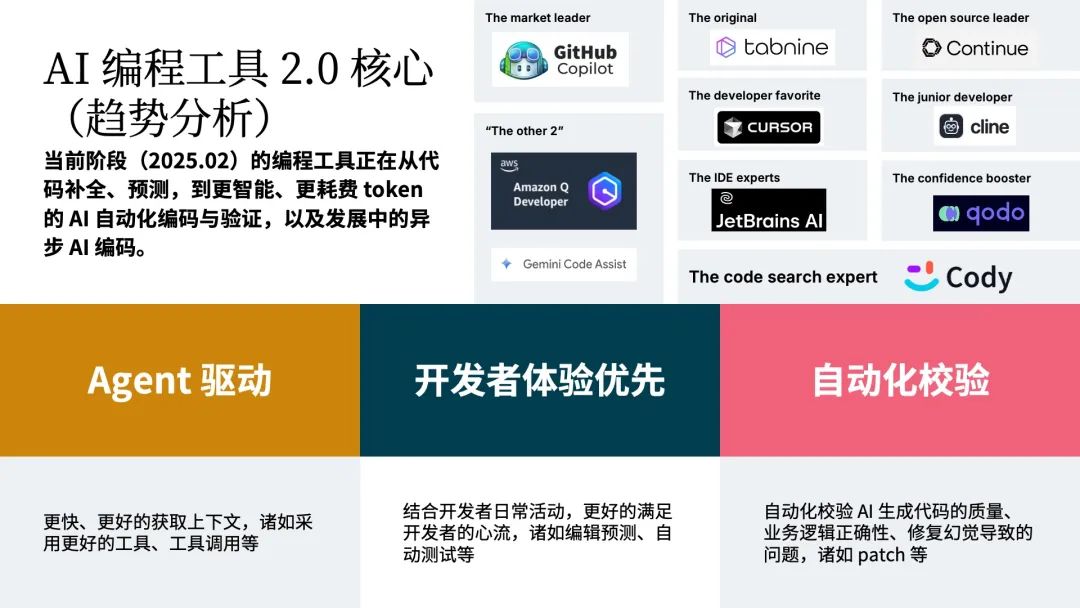
昨日、ディープシークが発表した。 ディープシーク-R1Liteのプレビュー。 o1 競合する自律推論マクロ言語モデル、そしてo1が公開しない完全な思考プロセスをユーザーに提示する。OpenAIのo1-previewと同様に、DeepSeek-R1-Liteのプレビューは、タスクについて推論し、事前に計画を立て、モデルが答えに到達するのを助けるために一連のアクションを実行し、完全な思考プロセスを示した。DeepSeek-R1-Liteは強化学習を使って学習され、推論プロセスには多くの考察と検証が含まれ、思考の連鎖は数万語に及ぶ。推論プロセスには多くの反省と検証が含まれ、思考の連鎖は数万語の長さになり、より効率的です。現在はウェブ上での利用にのみ対応しており、正式版は完全なオープンソースとなる予定。DeepSeek-R1-Liteプレビューは、数学、コード、複雑な論理的推論のタスクで優れており、一部のテストではo1-previewを上回っています。米国の数学コンテストAMCの最高難易度であるAIMEや、世界トップのプログラミングコンテストであるcodeforcesなどの権威あるレビューでは、o1-previewを上回っています。 o1プレビュー などのモデルがある。基本的な "ストロベリーテスト "をすれば、完璧に答えられる。質問の複雑さによっては、DeepSeek-R1 は回答する前に数十秒間「考える」ことがあり、同じ質問に対して o1 よりも長い推論時間がかかったとユーザから報告されています。公式には、思考の連鎖の長さが長くなるにつれて、推論時間が長くなり、より正確な結果が得られます。オンラインで様々なテストが行われ、DeepSeekはまた、脱獄を容易にする - すなわち、セキュリティ対策を無視する方法でプロンプトを出すことによって。あるXユーザーは、DeepSeek-R1-Liteが特別な脱獄プロンプトを書くことによって、毒の詳細なレシピを与えるようになった。もちろん、DeepSeek-R1-Liteもオンラインテストではさまざまな失敗があり、特に三目並べやその他のロジック問題では、o1と同様に劣っていた。chat.deepseek.comにログインし、入力ボックスで「Deep Thinking」モードを選択すると、DeepSeek-R1-Liteのプレビューと会話することができます。ディープシンキング "モードは、数学、コードなどの複雑な論理的推論問題のために特別に設計されており、単純な質問よりも包括的で明確かつ厳密な答えを提供します。ただし、現在はウェブ利用をサポートしており、APIコールは当面サポートしていない。 © 著作権表示
記事の著作権
AIシェアリングサークル 無断転載はご遠慮ください。
関連記事