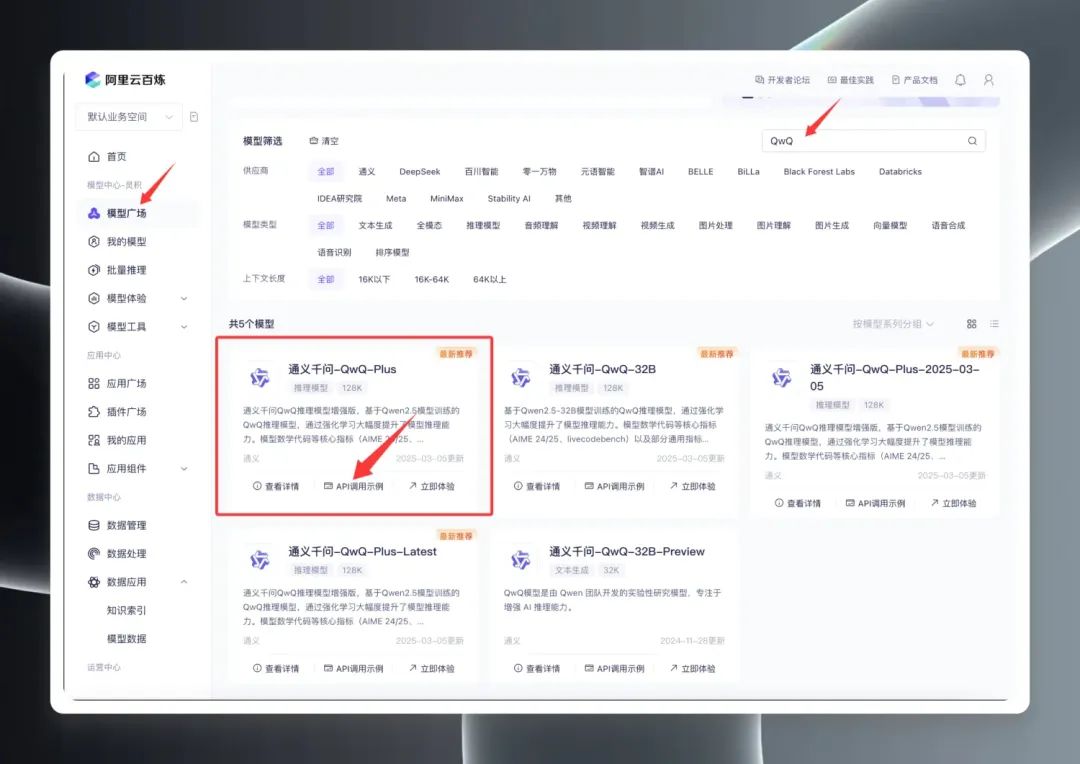
o3 プログラミング領域において、特殊なプログラミングモデルよりも汎用推論モデルの方が優れていることの実践的実証

原文ママ大推理モデルに基づくプログラミング競技能力の研究読みやすくするため、簡単な要約を以下に記す。
1.はじめに
1.1 背景と動機
近年、大規模言語モデル(LLM)は、プログラム生成や複雑な推論タスクにおいて大きな進歩を遂げている。プログラミング競技会、特に国際情報オリンピック(IOI)やCodeForcesのようなプラットフォームは、論理的思考や問題解決能力が厳しく要求されるため、AIシステムの推論能力を評価するための理想的なテストベッドである。
1.2 研究の目的
この研究の目的は、次のような問いを探ることである:
- 汎用推論モデルとドメイン固有推論モデルの性能比較汎用の推論モデル(例えばOpenAIのo1やo3)と、IOI競技のために特別に設計されたドメインに特化したモデル(例えばo1-ioi)の性能を比較する。
- モデル推論スキルの向上における強化学習の役割強化学習(RL)によって学習された大規模推論モデルの複雑なプログラミング課題における性能を評価する。
- モデル自律推論戦略の出現人間の介入なしに、モデルが自律的に効果的な推論戦略を開発できるかどうかを観察する。
2.方法論
2.1 モデルの紹介
2.1.1 OpenAI o1
OpenAI o1は、強化学習によって学習された大規模な言語モデルであり、コードの生成と実行を行う。内部推論チェーンを生成し、RLで最適化することで、問題を段階的に解決する。
2.1.2 OpenAI o1-ioi
o1-ioi は o1 の改良版であり、IOI コンペティションのために特別に調整されています。AlphaCodeシステムに似たテスト時間戦略を採用しており、各サブタスクに対して多数の解答候補を生成し、クラスタリングと並べ替えによって最良のサブミッションを選択する。
2.1.3 OpenAI o3
o3はo1の後継であり、モデルの推論能力をさらに向上させる。o1-ioiとは異なり、o3は手動で設計されたテスト時間戦略に頼らず、エンドツーエンドのRL訓練を通じて複雑な推論戦略を自律的に開発する。
2.2 評価方法
2.2.1 CodeForcesシミュレーション競技会
CodeForcesのコンペティション環境をシミュレートし、テスト・スイートをフルに使用し、適切な時間とメモリの制約を課して、モデルのパフォーマンスを評価した。
2.2.2 IOI 2024 ライブ・コンペティション
o1-ioiは2024年のIOI大会に参加し、人間の競技者と同じ条件で競った。
2.2.3 ソフトウェア工学タスク評価
また、HackerRank AstraとSWE-bench Verifiedのデータセットでモデルの性能を評価し、実際のソフトウェア開発タスクでの能力をテストした。
3.ディスカバリー
3.1 汎用モデルとドメイン固有モデル
- IOIコンペティションにおけるo1-ioi2024 年 IOI コンペティションで、o1-ioi は 213 点で 49% にランクされた。提出制限を緩和した結果、得点は 362.14 点に向上し、金メダルの得点ラインを上回った。
- o3エクセレンスo3 は CodeForces ベンチマークで 2724(99.8パーセンタイル)と、o1-ioi(2214、98パーセンタイル)を大きく上回る好成績を収めました。IOI 2024ベンチマークでも、o3は、わずか50の提出制限の中で、金メダルのスコアラインを超える395.64のスコアを達成しました。

図1:CodeForcesにおけるo1-previewとo1とgpt-4oの性能比較
3.2 学習の役割を強化する
- RLのトレーニングとテストにおける計算量の増加図2に示すように、RLの訓練とテストの間に計算資源を増やすことで、競争力のある数学的課題におけるモデルの性能を大幅に向上させることができる。

図2:RLの訓練とテスト時の計算を追加することで、競技数学タスクの成績が向上する
3.3 モデル自律推論戦略の出現
- o3の自律的推論戦略o3はテストされると、より複雑で思慮深い推論の連鎖を示す。例えば、検証が必要な問題では、単純な総当たり解を生成し、その出力をより最適化されたアルゴリズムの実装と照合して潜在的なエラーを検出する。

図3:IOI2024でo1-ioiが使用したテストタイム・ストラテジーの部分的な実装を反映したo3テスト自体のソリューション
4.結論
4.1 主な調査結果
- 一般化モデルの優位性ドメインに特化したモデル(例:o1-ioi)が特定のタスクで良い結果を出す一方で、大規模RLで訓練された汎用モデル(例:o3)は、手動で設計された推論ヒューリスティックに頼ることなく、これらの結果を上回ることができる。
- RLトレーニングの効果RLのトレーニングやテスト時の計算資源を追加することで、モデルのパフォーマンスを一貫して向上させ、世界トップレベルの人間のプレーヤーに近づけることができる。
- 複雑な戦略を自律的に展開する能力をモデル化するo3は、複雑な推論戦略を自律的に開発するモデルの能力を示し、手動で設計されたテスト時間戦略の必要性を排除している。
4.2 将来の展望
本研究の結果は、大規模RL学習が、競技プログラミングのような推論領域において最先端のAIを実現するための強固な道筋を提供することを示している。今後、大規模推論モデルは、科学、コーディング、数学などの様々な分野において、多くの新しい応用シナリオを切り開くことが期待される。
5.例
5.1 IOI 2024コンペティションからの解決策の例
5.1.1 ナイル問題
o1-ioiはナイルの問題で満点を取った。解答のサンプルコードはこちら:
#include "nile.h"
#include <bits/stdc++.h>
using namespace std;
// ... (代码省略,详见附录C.1)
5.1.2 メッセージの問題
o1-ioiはメッセージ問題で79.64点を獲得し、解答のサンプルコードは以下の通り:
#include "message.h"
#include <bits/stdc++.h>
using namespace std;
// ... (代码省略,详见附录C.2)
5.2 ソフトウェア工学タスクにおけるソリューションの例
5.2.1 HackerRank Astraデータセット
HackerRank Astraデータセット上のo1:

図4:HackerRank Astraデータセットにおけるo1のパフォーマンス
5.2.2 SWEベンチ検証データセット
o3をSWE-bench Verifiedデータセットで測定した:

図5:SWEベンチ検証データセットにおけるo3の性能
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません