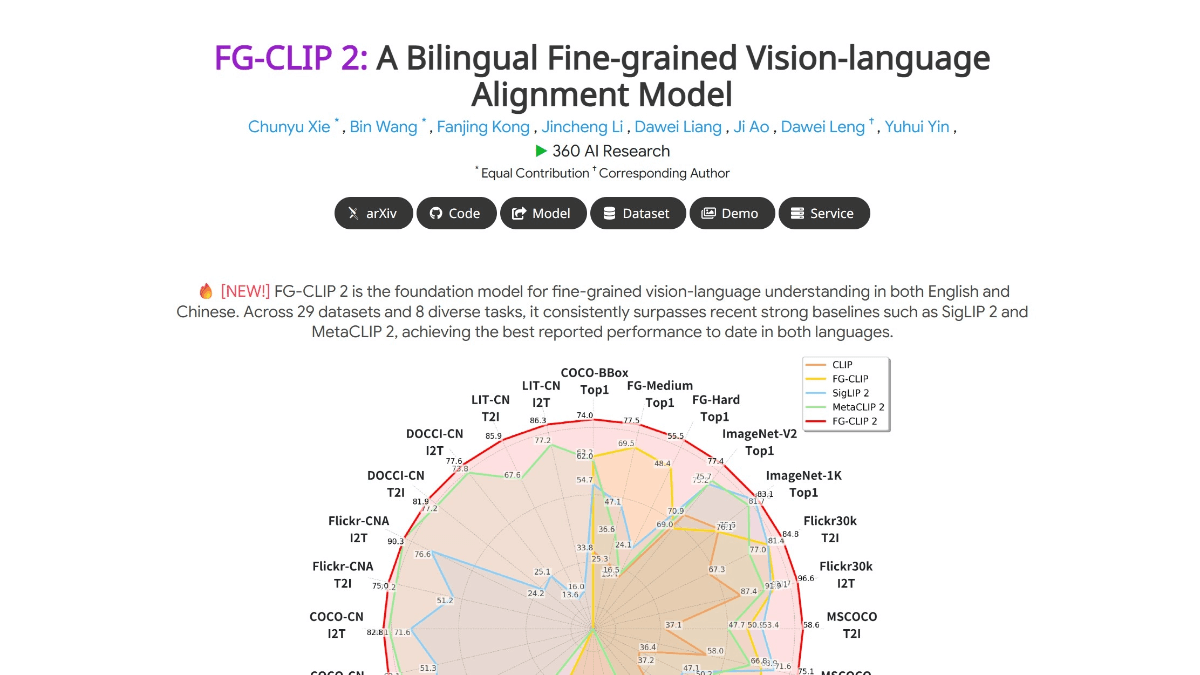
Morphik Core:マルチモーダルデータ処理のためのオープンソースRAGプラットフォーム

はじめに
Morphik Coreはmorphik-orgチームによって開発され、GitHubでホストされているオープンソースプロジェクトです。このツールはAIアプリケーションのために設計されたデータベースで、テキスト、画像、PDF、動画などの様々なデータを扱うことができます。Morphik Coreは大規模なデータ処理をサポートし、検索を高速に保ちながら何百万ものドキュメントを管理することができます。新しいアイデアを試す場合でも、本番環境を構築する場合でも、サポートを提供します。現在開発中で、ユーザーがウェイティングリストに参加できるホスティングサービスを開始する予定です。

機能一覧
- マルチモーダルデータのサポート:テキスト、PDF、画像、ビデオ、その他のフォーマットを扱うことができます。
- ファイルのインテリジェントな解析:自動的にファイルを小さなチャンクに分割し、エンベッディングを生成します。
- ColPaliマルチモーダル埋め込み:効率的な検索のためにテキストと画像コンテンツを組み合わせる。
- 知識グラフのサポート:検索結果を向上させるために、自動的にエンティティと関係を抽出します。
- 自然言語ルール:構造化された情報を抽出するために、乱雑なデータにルールを設定する。
- 効率的なキャッシュ:データを前処理して計算コストを削減し、レスポンスを高速化する。
- 拡張可能なアーキテクチャ:カスタムパーサーと複数のストレージメソッドをサポート。
- エムシーピー プロトコル:AIシステムとの知識共有を促進する。
ヘルプの使用
Morphik Coreは、主にGitHubを通じて開発者がコードを取得し、利用するためのツールです。以下は、すぐに使い始められるように、詳しいインストールと操作のガイドです。
設置プロセス
Morphik Coreを使い始めるには、GitHubからコードをダウンロードし、環境を設定する必要があります。手順は以下の通りです:
- クローン倉庫
ターミナルでコマンドを入力し、プロジェクトをダウンロードする:
git clone https://github.com/morphik-org/morphik-core.git
次にプロジェクト・ディレクトリに移動する:
cd morphik-core
- 仮想環境の構築
依存関係の衝突を避けるために、Python 3.12でスタンドアロン環境を作成する:
python3.12 -m venv .venv
環境を活性化させる:
- Linux/macOS:
source .venv/bin/activate - ウィンドウズ
.venv\Scripts\activate
- 依存関係のインストール
プロジェクトは以下の通り。requirements.txtファイルで必要なパッケージをインストールする:
pip install -r requirements.txt
ファイルが足りない場合は、GitHubのREADMEで最新の依存関係を確認してください。
- サービス開始
サーバーの設定と実行
python quick_setup.py
python start_server.py
サービス完了後 localhost:8000 走っている。
主な機能
モルフィックコアの核心は、マルチモーダルデータを処理し、次のような機能を提供することです。 ラグ 機能以下はその方法である:
1.データのインポート
Python SDKを使ってテキストやファイルをインポートすることができます。例えば、テキストをインポートします:
from databridge import DataBridge
db = DataBridge("databridge://localhost:8000")
doc = db.ingest_text("这是关于AI技术的示例文档。", metadata={"category": "tech"})
- 操作説明サーバーに接続後、テキストをインポートし、メタデータを追加する。
- 結局テキストは処理され、検索のために保存される。
PDFファイルをインポートします:
doc = db.ingest_file("path/to/document.pdf", metadata={"category": "research"})
- 官能性PDF、ビデオ、その他のフォーマットをサポートし、コンテンツを自動的に解析します。
2.マルチモーダル検索(コルパリ)
Morphik CoreはColPaliを使って画像を含む文書を処理します。例
doc = db.ingest_file("report_with_charts.pdf", use_colpali=True)
chunks = db.retrieve_chunks("显示第二季度收入图表", use_colpali=True, k=3)
- 動くファイルをインポートするときにColPaliを有効にし、検索するときにテキストと画像を返す。
- 効果図表や写真の内容を直接検索できます。
3.ルールの設定
自然言語でルールを定義し、情報を抽出することができる:
rules = [
{"type": "metadata_extraction", "schema": {"title": "string", "author": "string"}},
{"type": "natural_language", "prompt": "删除所有个人信息"}
]
doc = db.ingest_file("document.pdf", rules=rules)
- は英語の -ity、-ism、-ization に対応する。ファイルからタイトルや著者を抽出したり、必要に応じてデータをクリーンアップします。
- 提案ルールは文書の内容に合わせること。
4.ナレッジ・マッピング
ナレッジグラフを作成し、検索を強化するために使用する:
db.create_graph("tech_graph", filters={"category": "tech"})
response = db.query("AI如何与云计算相关?", graph_name="tech_graph", hop_depth=2)
- リグマップ生成後、クエリーは関連情報を返す。
- ゆうせい結果はより正確で、複雑な問題に適しています。
5.バッチ処理
フォルダ内のファイルのバッチインポートに対応:
docs = db.ingest_directory("data/documents", recursive=True, pattern="*.pdf")
- 官能性カタログを再帰的にスキャンし、すべてのPDFをインポートします。
- 取る大量のデータ処理に適している。
注目の機能操作
Morphik Coreのハイライトは、マルチモーダルサポートと効率性です。以下はその詳細です:
ColPaliマルチモーダル埋め込み
ColPaliは、テキストと画像を連動させることができます。例えば
db.ingest_file("report.pdf", use_colpali=True)
chunks = db.retrieve_chunks("查找2024年的销售数据图", use_colpali=True)
- 効果テキストを返すだけでなく、チャートを見つけることもできる。
- 使用ビジュアルコンテンツを含む文書の分析
効率的なキャッシュ
高速検索のためにデータを前処理する:
db.cache_documents(filters={"category": "research"})
chunks = db.retrieve_chunks("AI最新进展", k=5)
- マイレージ応答時間の短縮と計算コストの削減 80%
- 銘記するキャッシュはスペースを取るので、定期的に掃除する。
スケーラビリティ
データベースに接続し、大規模なデータを処理する:
db.connect_storage("postgresql://user:password@localhost:5432/dbname")
docs = db.ingest_directory("large_data")
- アジュバントPostgreSQLやMongoDBで何百万ものドキュメントを管理できます。
- テンポ検索時間は秒単位のままです。
ほら
- 初めて使う前に、GitHubの
README.mdそして公式文書。 - Pythonのバージョンが3.12で、依存関係が正しくインストールされていることを確認してください。
- 質問はDiscord (https://discord.gg/BwMtv3Zaju) またはGitHubでissueとして提出できます。
以上の手順で、Morphik Coreを簡単にインストールし、様々なデータニーズに対応できるようになります。
アプリケーションシナリオ
- 研究論文マネジメント
研究者は論文PDFをインポートし、ルールを使ってタイトルとアブストラクトを抽出し、ナレッジグラフを生成し、関連研究を素早く見つける。 - 企業データ分析
同社はレポートや契約を処理し、ColPaliで図表やテキストを検索し、効率化のためにデータをキャッシュする。 - 教育資料の照合
教師は教科書やビデオをインポートし、重要なポイントを抽出するルールを設定し、生徒はコースの内容を調べることができる。
品質保証
- モルフィックコアは有料ですか?
MITによってライセンスされたオープンソースプロジェクトであり、無料で使用できる。 - サーバーが必要ですか?
そう、セルフホスティングにはローカルでサーバーを動かす必要があり、将来的にはクラウドホスティングの選択肢も出てくるだろう。 - ビデオをサポートしていますか?
ビデオを解析し、テキストとコンテンツを抽出するサポート。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません