
Molmo:Ai2によって構築された一連のマルチモーダルオープン言語モデル

はじめに
MolmoはAllen Institute for AI (Ai2)によって開発されたマルチモーダルオープン言語モデルです。Molmoは、テキストとビジュアルのデータ処理能力を組み合わせて、画像内のオブジェクトを認識し、正確な説明を生成します。Molmoは、多くのベンチマークで優れた性能を発揮し、特に文書の読み取りや視覚的推論などの複雑なタスクでその威力を発揮しています。モデルとデータセット今後数ヶ月のうちに、さらに多くのモデルや拡張テクニカルレポートを発表する予定であり、研究者により多くのリソースを提供することを目指している。 テクニカル・レポート.
Molmoの主な革新点は、全く新しい画像記述データセットを使用していることである。PixMoは、高度に選択された100万組の画像とテキストからなるデータセットである。これらのデータセットは、音声説明を通じて人間のアノテーターによってのみ収集された。さらにMolmoは、自然言語だけでなく非言語的な手がかりも使って質問に答えることを可能にする革新的な2Dポインティングデータを含む、微調整のための多様なデータセットを導入している。

MolmoはQwen2-72Bをベースにしており、OpenAIのCLIPをビジュアル・バックボーンとして使用し、画像やテキストの処理能力を高めている。
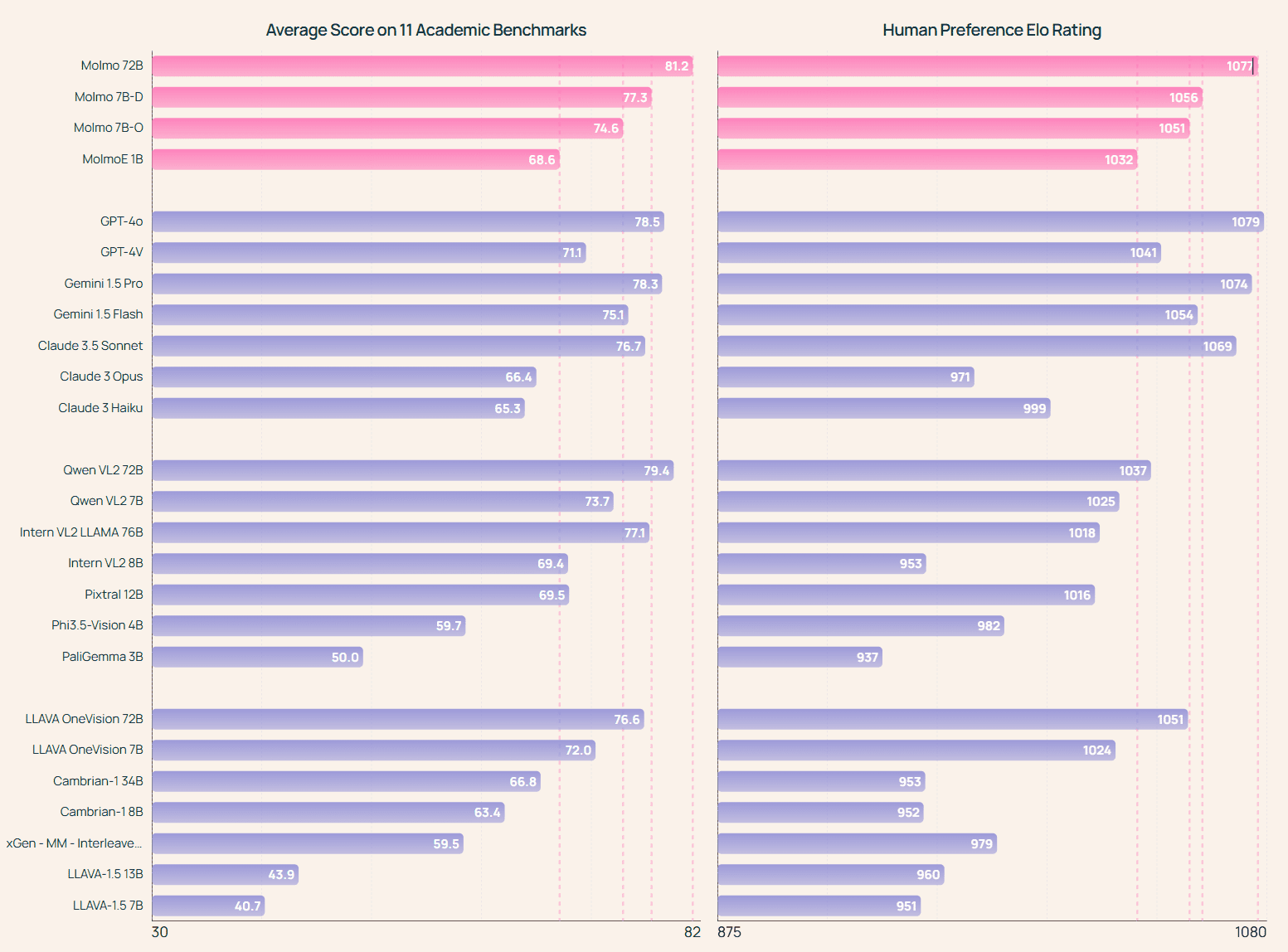
Molmo-72B:アカデミックベンチマークテストで最高得点を獲得し、手動評価ではGPT-4oをわずかに下回る2位にランクされた。 また、以下を含むいくつかの最先端の専有システムも上回った。 ジェミニ 1.5プロ、フラッシュ クロード 3.5 Sonnet: MolmoE-1B: 完全にオープンなOLMoE-1B-7BハイブリッドエキスパートLLMに基づく最も効率的なMolmoモデルで、学術的ベンチマークと手動評価の両方でGPT-4Vとほぼ同等の性能を示す。 Molmo-7Bの両モデル:学術ベンチマークと手動評価の両方でGPT-4VとGPT-4oの中間の性能を示し、最近リリースされたPixtral 12Bモデルを両ベンチマークで大幅に上回る。
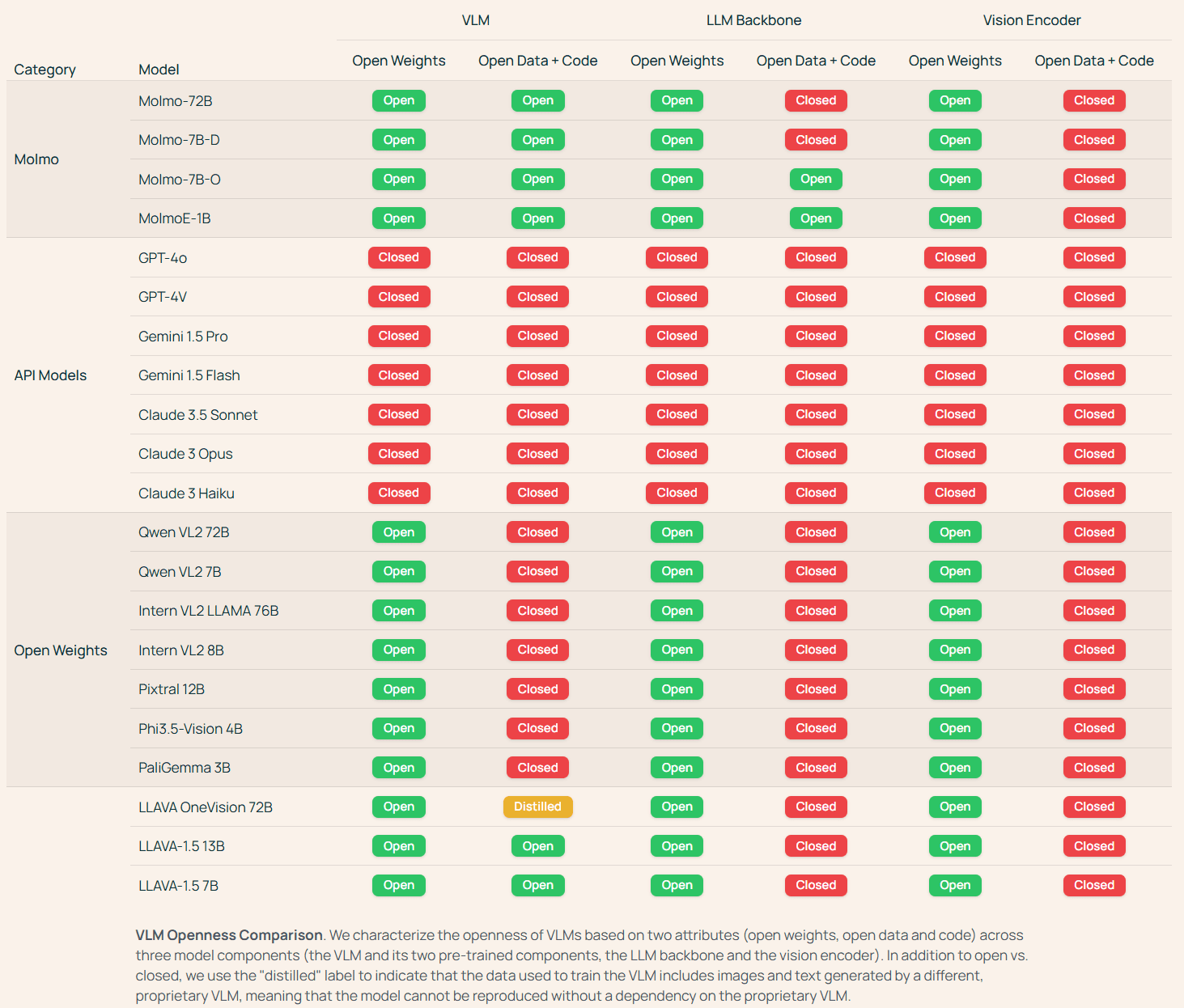
より多くのウェイトとデータモデルを開放する
機能一覧
- 画像認識:画像内のオブジェクトを認識し、説明を生成する能力。
- テキスト生成:入力テキストまたは画像に基づいて、関連するテキスト説明を生成します。
- マルチモーダルデータ処理:複雑なタスクのためにテキストデータと視覚データを組み合わせる。
- オープンソースリソース:モデルやデータセットのオープンソースリソースが研究者のために用意されている。
- オンラインデモ:ユーザーが画像をアップロードし、説明を生成できるオンラインデモ機能を提供します。
ヘルプの使用
使用ガイドライン
- 画像認識ウェブサイトのトップページにある「画像のアップロード」ボタンをクリックし、認識させたい画像ファイルを選択します。アップロード後、システムが自動的に画像の説明を生成します。
- テキスト生成テキストボックスに説明文を生成したい文章や質問を入力し、「生成」ボタンをクリックすると、入力された内容に従って説明文が生成されます。
- マルチモーダルデータ処理ユーザーは画像とテキストの両方をアップロードすることができ、システムは2つを組み合わせて包括的な説明を生成します。
- オープンソースリソースHuggingFaceプラットフォームでMolmoモデルを検索し、提供されているオープンソースリソースをダウンロードして使用することができます。
- オンラインデモ: ホームページの「オンラインデモ」ボタンをクリックすると、デモページにアクセスできます。ユーザーは画像をアップロードしたり、テキストを入力したりして、モルモの機能をリアルタイムで体験することができます。
機能 操作の流れ
- 画像認識::
- モルモのウェブサイトを開き、「画像のアップロード」ボタンをクリックします。
- 認識する画像ファイルを選択し、「アップロード」をクリックします。
- システムが処理し、画像の説明を生成するのを待つ。
- 生成された説明を表示し、保存する。
- テキスト生成::
- テキストボックスに、説明を生成するテキストまたは質問を入力します。
- 生成」ボタンをクリックし、システムが処理するのを待つ。
- 生成された説明文を表示し、必要に応じて編集または保存します。
- マルチモーダルデータ処理::
- 画像とテキストを同時にアップロードし、「処理」ボタンをクリックします。
- このシステムは、画像処理とテキスト処理を組み合わせて包括的な説明を生成する。
- 生成されたコンポジットの説明を表示し、保存する。
- オープンソースリソースの利用::
- ハギング・フェイス・プラットフォームにアクセスし、モルモのモデルを検索する。
- モデルとデータセットをダウンロードし、インストールと使用の指示に従ってください。
- 提供されているサンプルコードとドキュメントは、二次開発や研究にご利用ください。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません