サポートベクターマシン(サポートベクターマシン)とは何か、読んで理解するための記事サポートベクターマシン(SVM)は、統計的学習理論に基づく教師あり学習アルゴリズムで、主に分類や回帰分析に用いられる。中心的な目的は、異なるカテゴリのデータ点を分離し、2つのデータ点の差を最大化する最適な決定超平面を見つけることである。AIアンサー3ヶ月前022.1K
評価指標とは何か?評価メトリクス(Evaluation Metrics)とは、機械学習モデルの性能を測定するための定量的な基準の体系である。人体の健康状態を総合的に評価する多次元健康診断レポートのようなものである。分類タスクでは、精度はモデルの判断の全体的な正しさを反映し、精度(Pr...AIアンサー3ヶ月前021K
ニューラル・アーキテクチャ・サーチ(NARS)とは?ニューラル・アーキテクチャ・サーチ(NAS)は、ニューラルネットワークの構造設計の自動化に焦点を当てた人工知能の最先端分野である。AIアンサー3ヶ月前020.8K
CGAAN(Conditional Generative Adversarial Network)とは?条件付き生成逆説ネットワーク(CGAN)は、2014年にMehdi Mirzaらによって提案された生成逆説ネットワーク(GAN)の重要な変種である。従来の生成的逆数ネットワークとは対照的に、...AIアンサー3ヶ月前019K
グリッドサーチ(Grid Search)とは何か、理解するための記事グリッドサーチは、機械学習における最適なハイパーパラメータの組み合わせを系統的に見つけるための自動化された手法である。この手法は、各ハイパーパラメータの候補値の範囲を事前に定義し、可能なパラメータの組み合わせをすべて洗い出し、モデルを1つずつ訓練して性能を評価し、最終的に最も性能の良いハイパーパラメータを選択する。AIアンサー4ヶ月前028K
ランダム・サーチ(無作為検索)とは何か、見て理解するための記事ランダムサーチ(RS)はハイパラメトリック最適化手法の一つで、パラメータ空間内の候補点をランダムにサンプリングすることで最適なコンフィギュレーションを見つける。AIアンサー4ヶ月前027.8K
データ補強(Data Augmentation)とは何か、見て理解するための記事データ補強(DA)とは、新しいデータを人為的に作成することで、トレーニングデータセットを補強する技術的アプローチである。AIアンサー4ヶ月前025.4K
ナイーブ・ベイズとは何か?ナイーブベイズ・アルゴリズムは、ベイズの定理に基づく教師あり学習アルゴリズムである。「ナイーブベイズはベイズの定理に基づいており、特徴は互いに条件付きで独立であると仮定している。この仮定を単純化することで、計算の複雑さが大幅に軽減され、実用的なアプリケーションにおいて効率的なアルゴリズムとなる。AIアンサー5ヶ月前032.5K
K-Meansクラスタリング(K-Means Clustering)とは何か?K-Meansクラスタリング(K-Means Clustering)は、古典的な教師なし機械学習アルゴリズムである。主にデータ集合をK個の不連続なクラスターに分割するために使用される。このアルゴリズムの目的は、各データ点が最も近いクラスタ中心に対応するクラスタに属するように、n個のデータ点をK個のクラスタに割り当てることである。AIアンサー5ヶ月前027K
フィードフォワード・ニューラル・ネットワーク(FNN)とは?フィードフォワード・ニューラル・ネットワーク(FNN)は、人工ニューラルネットワークの基本的なモデルであり、広く使われている。ネットワークの接続はループやフィードバック経路を形成せず、情報は入力層から出力層へと厳密に一方向に流れる。AIアンサー5ヶ月前030.1K
K-最近傍アルゴリズム(K-Nearest Neighbors)とは何か?K-最近傍(K-Nearest Neighbors)は、分類や回帰タスクに使用できるインスタンスベースの教師あり学習アルゴリズムである。AIアンサー5ヶ月前027K
畳み込みニューラルネットワーク(CNN)とは何か?畳み込みニューラルネットワーク(CNN)は、格子構造を持つデータを処理するために特別に設計された人工ニューラルネットワークであり、画像や映像解析の分野で優れている。AIアンサー5ヶ月前027.6K
クロスバリデーション(交差検証)とは何か?クロスバリデーションは、機械学習におけるモデルの汎化能力を評価するための中核的な手法である。基本的な考え方は、元のデータを訓練セットとテストセットに分割し、訓練と検証を異なるデータ部分集合でローテーションすることで、より信頼性の高い性能推定値を得ることである。このアプローチでは、...AIアンサー5ヶ月前031.2K
ランダムフォレスト(無作為の森)とは何か、読んで理解するための記事ランダムフォレスト(Random Forest)は、複数の決定木を構築し、それらの予測値を組み合わせることで機械学習タスクを実行する統合学習アルゴリズムである。このアルゴリズムは、ブートストラップ集計の考えに基づいており、元のデータセットから複数のサンプルのサブセットをランダムに抽出し、各ツリーに対してプットバックを行う...AIアンサー5ヶ月前028.3K
損失関数(ロス・ファンクション)とは何か、読んで理解するための記事損失関数(LF)は機械学習の中核をなす概念であり、モデルの予測誤差を定量化するという重要な役割を担っている。この関数は、モデルの予測値と真の値との差の程度を数学的に測定し、モデルの最適化のための明確な方向性を提供する。AIアンサー5ヶ月前027.1K
ハイパーパラメーター(ハイパーパラメーター)とは何か、見て理解するための記事機械学習において、ハイパーパラメータとは、データから学習するのではなく、モデルの学習を開始する前に手動でプリセットされる設定オプションのことである。中心的な役割は、アルゴリズムの動作ルールを設定するように、学習プロセス自体を制御することである。例えば、学習...AIアンサー6ヶ月前031.1K
デシジョンツリー(決定木)とは何か?決定木(DT)は、人間の意思決定プロセスをシミュレートするツリー型の予測モデルであり、一連のルールによってデータを分類または予測する。各内部ノードは特徴テストを表し、枝はテスト結果に対応し、葉ノードは最終決定を格納する。このアルゴリズムは分割統治戦略を用いる...AIアンサー6ヶ月前029.2K
勾配降下(グラディエント・ディセント)とは何か、読んで理解するための記事勾配降下は、関数の最小値を解くための中心的な最適化アルゴリズムです。このアルゴリズムは、関数の勾配(それぞれの偏導関数からなるベクトル)を計算し、θ = θ - η - ∇J(θ)の規則に従ってパラメータを繰り返し更新することにより、降下の方向を決定します。AIアンサー6ヶ月前029.8K
ロジスティック回帰(ロジスティック回帰)とは何か、読んで理解するための記事ロジスティック回帰は、バイナリ分類問題を解くのに使われる統計的学習手法である。中心的な目的は、入力特徴に基づいてサンプルが特定のカテゴリに属する確率を予測することである。このモデルは、S字関数を用いて固有値を線形結合することにより、線形出力を0と1の間にマッピングする...AIアンサー6ヶ月前027.7K
正則化(レギュラー化)とは何か、見て理解するための記事正則化は、モデルのオーバーフィッティングを防ぐための、機械学習や統計学における中核的な手法である。正則化は、モデルの複雑さに関連するペナルティ項を目的関数に追加することで、フィッティングの度合いを制御する。一般的な正則化にはL1正則化とL2正則化があり、L1正則化はスパース解を生成し、...AIアンサー6ヶ月前031.3K
Generative Adversarial Network(GAN)とは?Generative Adversarial Network(GAN)は、2014年にIan Goodfellowらによって提案されたディープラーニングモデルである。このフレームワークは、2つのニューラルネットワークを互いに学習させることで生成モデルを実装する...AIアンサー6ヶ月前030.6K
自己注意(Self-Attention)とは何か、読んで理解するための記事自己アテンションは、ディープラーニングにおける重要なメカニズムであり、元々はTransformerアーキテクチャで提案され、広く使われている。コアとなるアイデアは、モデルが入力シーケンス内のすべての位置に同時にアテンションし、各位置を...AIアンサー6ヶ月前040.8K
拡散モデル(拡散モデル)とは何か、読んで理解するための記事拡散モデルは、画像、音声、テキストなどの新しいデータサンプルを作成するために特別に設計された生成モデルです。このモデルの中核は、物理学における拡散のプロセスにインスパイアされており、高濃度の領域から低濃度の領域への粒子の自然な拡散をシミュレートする。マシンでは...AIアンサー6ヶ月前041.8K
ファインチューニングとは何か?モデルの微調整(Fine-tuning)は、機械学習における転移学習の具体的な実装である。中核となるプロセスは事前学習モデルに基づいており、大規模なデータセットを用いて一般的なパターンを学習し、広範な特徴抽出能力を開発する。ファインチューニングの段階では、次にタスクに特化したデータセットを導入し、...AIアンサー6ヶ月前034.2K
アテンション・メカニズム(注意のメカニズム)とは何か?注意メカニズム(Attention Mechanism)は、人間の認知プロセスを模倣する計算技術で、当初は機械翻訳の分野で応用され、後にディープラーニングの重要な一部となった。AIアンサー6ヶ月前040.1K
トランスフォーマー・アーキテクチャーとは?Transformerアーキテクチャは、機械翻訳やテキスト要約のようなシーケンス間のタスクを処理するために設計された深層学習モデルである。コアとなる革新的な点は、従来のループや畳み込み構造を排除し、自己注意メカニズムのみに依存する点にある。モデルがシーケンスの全ての要素を並列に処理できるようにすることで、大規模な...AIアンサー6ヶ月前038.7K
事前学習済みモデル(Pre-trained Model)とは何か、読んで理解するための記事事前学習済みモデル(PTM)は、人工知能における基本的かつ強力な手法であり、大規模なデータセットで事前学習された機械学習モデルを表す。モデルは大量の情報を処理し、データから一般的なパターンや特徴を学習することで、幅広い知識ベースを形成する。AIアンサー6ヶ月前037.4K
LLM(ラージ・ランゲージ・モデル)とは?大規模言語モデル(Large Language Model:LLM)は、Transformerアーキテクチャを中核とし、膨大なテキストデータに対して学習されたディープラーニングシステムである。このアーキテクチャの自己アテンションメカニズムは、言語の長距離依存関係を効果的に捉えることができる。このモデルの「ラージ...AIアンサー6ヶ月前037.3K
長短期記憶(LSTM)ネットワークとは何か?ロング・ショート・ターム・メモリー(LSTM)は、シーケンスデータを処理するために特別に設計されたリカレント・ニューラル・ネットワークの変種である。人工知能の分野では、シーケンスデータは時系列予測、自然言語処理、音声認識などのタスクで広く使用されている。AIアンサー6ヶ月前032.2K
フェデレーテッド・ラーニングとは何か?Federated Learning(FL)は、2016年にグーグルの研究者チームによって初めて提案された革新的な機械学習アプローチで、データプライバシーと分散コンピューティングの課題に対処することを目的としている。AIアンサー6ヶ月前037.4K
リカレント・ニューラル・ネットワーク(RNN)とは何か?リカレントニューラルネットワーク(RNN)は、逐次データを処理するために設計されたニューラルネットワークアーキテクチャである。逐次データとは、言語テキスト、音声信号、時系列など、時間的順序や依存関係を持つデータの集まりを指す。AIアンサー7ヶ月前040.2K
人工知能フェアネス(AIフェアネス)とは何か?AIの公平性とは、AIシステムが、その設計、開発、配備、運用のライフサイクルを通じて、すべての個人や集団を公平かつ不偏の態度で扱うことを保証する学際的な分野である。AIアンサー7ヶ月前036.9K
1記事でわかるメタラーニング(メタ学習)とは?メタ学習(学習方法の学習)は、機械学習分野の重要な一分野であり、新しいタスクに素早く適応できる学習アルゴリズムの開発に焦点を当てている。AIアンサー7ヶ月前041.3K
人工知能の安全性(AI Safety)とは何か?人工知能の安全性(AI Safety)とは、AIシステム、特にますます強力になり自律的に動作するAIシステムが、そのライフサイクルを通じて、有害な結果を招くことなく、人間の意図に従って確実かつ予測可能に動作することを保証する最先端の学際的分野である。AIアンサー7ヶ月前035K
自己教師あり学習(SSL)とは何か?自己教師あり学習(SSL)は、機械学習分野における新たな学習パラダイムであり、その中核となる考え方は、ラベル付けされていないデータから教師あり信号を自動的に生成し、モデルを訓練してデータの有用な表現を学習することである。AIアンサー7ヶ月前036K
超人工知能(ASI) ASI(人工超知能)とは何か?人工超知能(ASI)とは、認知、創造性、問題解決、意思決定などあらゆる領域で人間を凌駕する能力を持ち、人間の知能を凌駕する知的システムである。AIアンサー7ヶ月前049.5K
トランスファー・ラーニング(転移学習)とは何か?転移学習(Transfer Learning:TL)は、機械学習の分野における重要な一分野であり、その中核となる考え方は、あるタスクやドメインから学んだ知識を、関連はするが異なる別のタスクやドメインに適用することである。AIアンサー7ヶ月前036.2K
人工知能ガバナンス(AIガバナンス)とは何か?AIガバナンスとは、技術、倫理、法律、社会を網羅する包括的な枠組みであり、AIシステムの設計から開発、導入、最終利用までのライフサイクル全体を効果的に指導、管理、監督するものである。中心的な目標は、技術革新を妨げることではなく、AI技術の開発と応用が確実に始まるようにすることである。AIアンサー7ヶ月前043.9K
半教師付き学習(SSL)とは何か?半教師付き学習は機械学習の分野で重要な分野であり、学習効果と汎化能力を向上させるために、少量のラベル付きデータと大量のラベルなしデータを用いてモデルを共学習させる。AIアンサー7ヶ月前041.9K
強化学習とは何か?強化学習は機械学習の重要な一分野であり、インテリジェンスが環境との継続的な相互作用を通じて、長期的な累積報酬を最大化するために最適な決定を下す方法を自律的に学習できるようにすることに主眼が置かれている。AIアンサー7ヶ月前035.5K
教師あり学習(SL)とは何か?教師あり学習は、機械学習の最も一般的で基本的な手法のひとつであり、その核となる考え方は、「正解」のある既存のデータセットを使って、予測や判断を行う方法をコンピューターモデルに教えることである。AIアンサー7ヶ月前037.8K
ディープラーニング(深層学習)とは何か、理解するための記事ディープラーニング(DL)は機械学習の一分野であり、データ中の複雑なパターンを学習し表現するための多層人工ニューラルネットワークの使用を中心としている。AIアンサー7ヶ月前038.8K
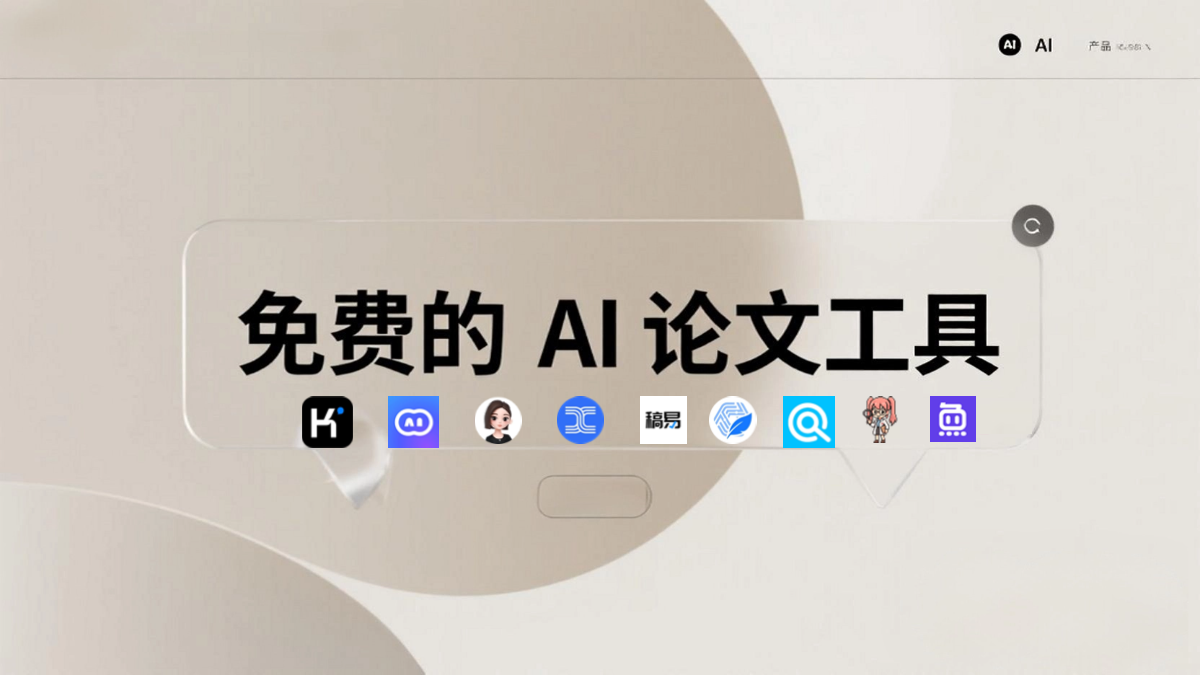
おすすめのAI小論文作成ツールとは?おすすめの無料AIアカデミック小論文アシスタント15選人工知能ブームの時代、AIツールは私たちの生活を変え、学術研究や論文執筆を大いに助けてきた。ユーザーがより効率的に仕事や勉強ができるように、このまとめでは、最先端の無料のAI学術論文アシスタントを15個厳選して紹介する。AIアンサー7ヶ月前046.9K
弱小AI(ナローAI)とは何か?弱い人工知能(Narrow AI)は現在、現実世界におけるAI技術開発の主流である。弱いAIは、特定の、明確に定義されたタスクを、その特定の領域において人間を凌駕するかもしれない知能レベルで実行するように設計され、訓練される。AIアンサー7ヶ月前045.1K
人工知能 AI(人工知能)とは何か?人工知能(AI)とは、人間の知能をシミュレートし、拡張し、さらにはそれを凌駕するような理論的・技術的システムを構築することを目的とするコンピューター科学の中核的な一分野である。AIアンサー7ヶ月前056.8K
AGI(人工知能)とは何か?一般人工知能(AGI)とは、あらゆる認知タスクにおいて人間と同様、あるいはそれ以上に理解し、学習し、推論し、適応し、創造することができる知的システムのことである。AIアンサー7ヶ月前042.6K
デジタル・ツイン(Digital Twin)とは何か、見て理解するための記事デジタル・ツイン(Digital Twin)は、高精度、高忠実度、リアルタイムの双方向インタラクションを備えた仮想デジタル空間において、物理的実体や複雑なシステムのミラーモデリング、ダイナミック・マッピング、フルライフサイクル管理を行うための技術システムである。AIアンサー7ヶ月前042.1K
AIを使ったPPTの作り方、おすすめ4 AIエージェント・フリージェネレーションより質の高いPPTを作成するためのツールはないかと、しばしば友人に尋ねられます。 「PPTを作るのは、コンテンツを書くよりも難しいんだ。AIハンズオンチュートリアル10ヶ月前065.1K
9つの主流ビッグモデル・セキュリティ・フレームワークの徹底分析と比較大規模な言語モデリング技術の急速な発展と幅広い応用に伴い、その潜在的なセキュリティリスクはますます業界の注目の的となっています。このような課題に対処するため、世界トップクラスのテクノロジー企業、標準化団体、研究機関の多くが、独自のセキュリティフレームワークを構築し、公開している。本稿では、その中から9つを分析する。AI知識ベース11ヶ月前066.1K
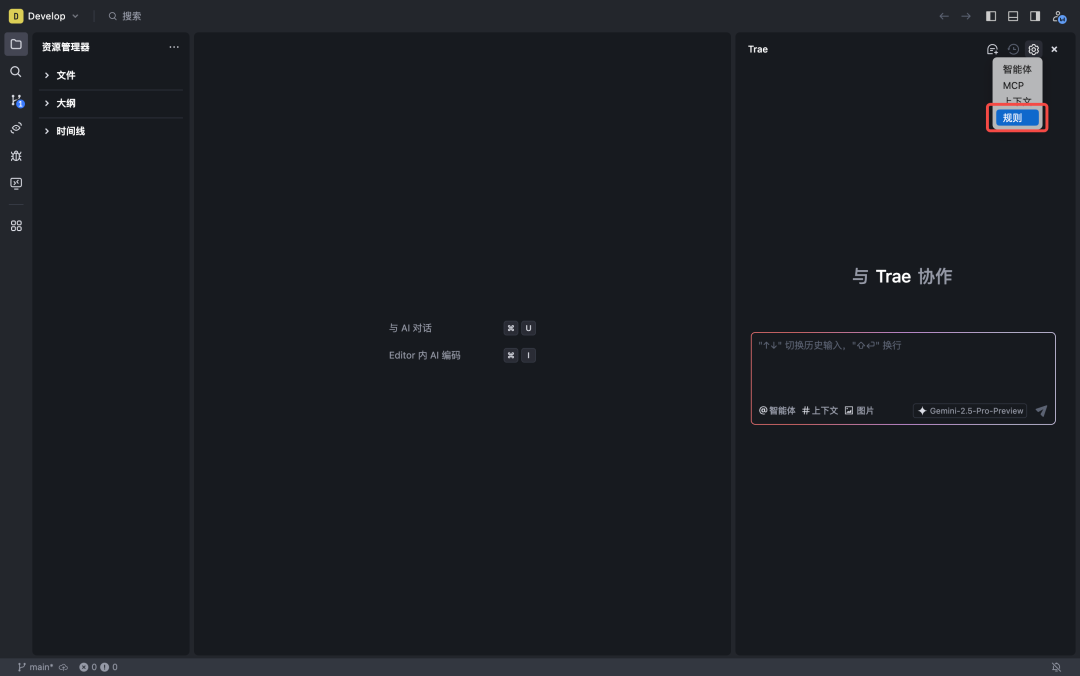
Trae IDEガイド: カスタムAIルールの簡単設定 (Trae Rules)プログラミングにおけるAIの応用がますます深化するにつれ、多くの開発者はAIによるプログラミングの利便性を体験した後、自分たちのニーズをよりよく理解してくれる「専属AIエンジニア」の存在を期待するようになる。この需要の核心は、開発者の個人的な指示に正確に従うAIの能力にある...AIハンズオンチュートリアル10ヶ月前0216.6K
ボタン・スペース・システム Cue word あなたはタスク実行のエキスパートであり、ユーザーのニーズに応じて複数のツールを呼び出して手元のタスクを完了させることを得意としています。 #メッセージモジュールの説明 - ツール(関数呼び出し)を使用して応答する必要があります。AIユーティリティ・コマンド11ヶ月前262.5K
NotebookLM システムプロンプト 最近、NotebookLMは中国語でサポートされるようになったが、私の意見では、無料の製品の中でより推奨される個人的な知識管理ツールの一つである。 NotebookLMの2つの主な機能は、質問と答えに正確なソースを引用することと、2人の会話のポッドキャストを生成することです。 正確な出典の引用...AIユーティリティ・コマンド11ヶ月前081.6K
マイクロソフトGitHubコパイロットシステムプロンプトワード説明ラージ・ランゲージ・モデル(LLM)を効率的に使いたいユーザーや開発者にとって、よく設計されたシステム・プロンプトは不可欠です。システム・プロンプトは、AIの行動や動作のマニュアルとして機能し、AIの応答の質に直接影響します。AIユーティリティ・コマンド11ヶ月前081.9K
クロードのウェブ版とAPI体験の違い:システム・プロンプトの約10万語を解明する多くのユーザーが、AnthropicのClaude APIを直接呼び出した場合と、公式のClaudeウェブバージョンを呼び出した場合の体験に、微妙だが感じられる違いがあるようだと観察している。この違いの多くは、ウェブバージョンの背後にある複雑なシステムプロンプト(Sy...AIユーティリティ・コマンド11ヶ月前075K
PDF文書をビジュアルなWebページに変換するためのヒントプロンプトの言葉 コンテンツを分析し、美しく素敵な中国語ビジュアルウェブポートフォリオに変換するためにファイルをお渡しします: ## コンテンツの要件 - すべてのページコンテンツは簡体字中国語でなければなりません - 元のファイルのコア情報を維持しますが、より読みやすく、視覚的な方法でそれを提示 - ページの下部に追加...AIユーティリティ・コマンド11ヶ月前059.6K
カーソル あなたのコーディング作業に最適なAIモデルは?最近、AI支援プログラミングツールの『Cursor』が、開発者が好むAIモデルのリストを発表したが、そのデータによると、クロード3.7のソネット・モデルがリストのトップになっている。 この公式データは、間違いなく開発者のかなりの部分の選択を反映している。しかし、この...AIアンサー11ヶ月前094.8K
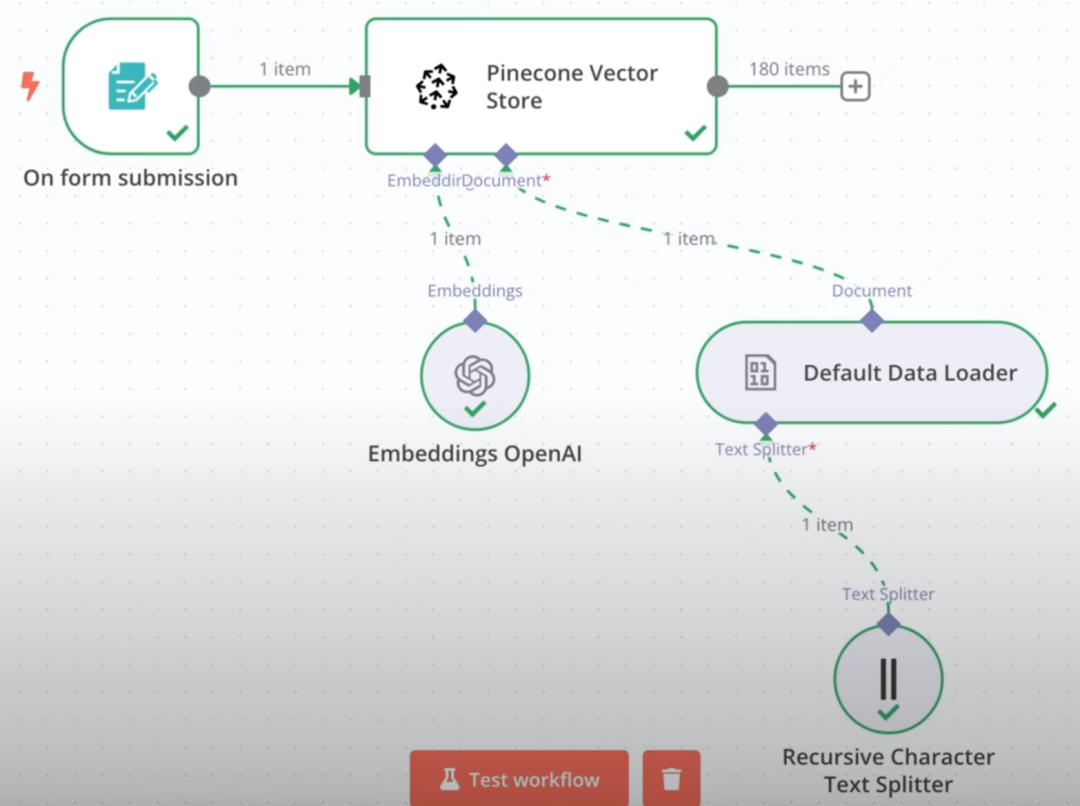
チュートリアル:FastGPTナレッジベースをn8nワークフローにシームレスに統合(MCPプロトコルに基づく)背景:RAGナレッジベース統合によるn8nの挑戦 n8nは、強力なオープンソースの自動ワークフローツールとして支持を集めている。元『パイレーツ・オブ・カリビアン』のビジュアルデザイナーであるヤン・オーバーハウザー氏によって、2019年に設立された。AIハンズオンチュートリアル11ヶ月前075.3K
OpenRouterリチャージガイド:アリペイとWeChat決済の使い方背景:OpenRouterとその支払いオプション OpenRouterは、開発者とユーザーが統一されたAPIインターフェースを通じて、異なるプロバイダーから複数の大規模言語モデルにアクセスできる統合プラットフォームを提供する。これらの高度なAI機能を利用したいユーザーにとって...AIアンサー11ヶ月前0194.6K
OpenRouter、無料クレジットとレート制限を調整世界有数の大規模言語モデルのAPIを集約したプラットフォームであるOpenRouterは、最近、無料利用ポリシーと料金制限を大幅に変更した。このプラットフォームは使いやすさで知られており、1つのAPIキーでDeepSeek、Qw...などのAPIを呼び出すことができる。AIアンサー11ヶ月前0285K
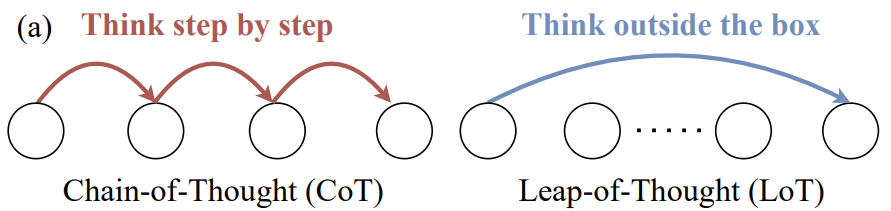
大規模言語モデルの創造性を評価する:多肢選択式LoTbenchパラダイムを超えてラージ・ランゲージ・モデリング(LLM)研究の分野では、Chain-of-Thoughtに代表される論理的推論能力と同様に、モデルのLeap-of-Thought能力、すなわち創造性が重要である。しかし、現在のLLMの創造性...AI知識ベース12ヶ月前050.1K
クロード・コードを使いこなす:AIプログラミングの生産性を高める実践ガイドクロード・コードを使いこなす:最前線からの実践的エージェント・コーディングのヒント クロード・コードは、エージェント・コーディングのためのコマンドライン・ツールです。エージェントコーディングとは、AIに自律性を与えることを意味します。AI知識ベース12ヶ月前072.3K
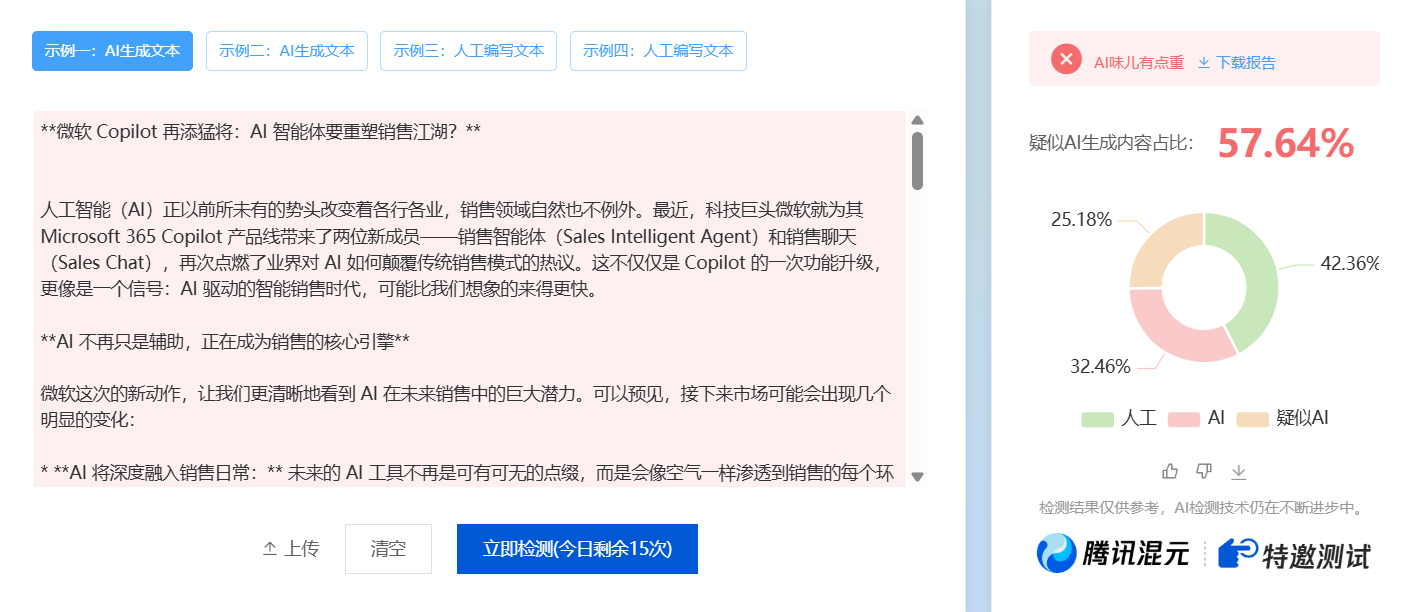
例なしでGemini 2.5 Proを使用して記事からAIフレーバーを削除するGemini 2.5 Proでのみテスト、注「推論モデルで実行する必要があります」、パフォーマンス 拡大されたテキスト、1000語 拡大された2000語かそこら Zhu Zhuの大きなモデルは、AIのフレーバーが22%以下しか改善されないことを検出する。AIユーティリティ・コマンド12ヶ月前068K
GPT-4.1オフィシャル・ティップス・エンジニアリング・ガイド(中国語版)GPT-4.1ファミリーは、GPT-4oと比較して、コーディング、命令順守、長いコンテキストの処理能力が大幅に向上しています。具体的には、コード生成と修復タスクでより優れた性能を発揮し、複雑な命令をより正確に理解して実行し、長い入力テキストを効率的に処理することができます。AI知識ベース12ヶ月前059K
ゼロから学ぶAI支援プログラミング「Vibe Coding」とは?バイブ・コーディング:コードが消える、直感駆動型ソフトウェア開発の新潮流? ジェネレーティブな人工知能の飛躍的な成長により、産業が再構築されつつあるが、ソフトウェア開発も例外ではない。2025年の初め頃、シリコンバレーに新しい考え方の波が押し寄せ始めた。AIハンズオンチュートリアル12ヶ月前086.9K
インスタントドリームを使ってテキストベースの記事グラフィックスを生成する(プロンプトワード)写真や中国のポスター、さらに最適化のための神と記事の生成を容易にするために、その夢3.0モデルのボタンの使用のリリース以来、以下の共有、記事のカバーとして使用するためのより適切な、画像の本体としてテキストを生成することができます。 コアプロンプトの単語は次のとおりです プロンプトの単語の役割は、画像を生成するために生成することです...AIユーティリティ・コマンド12ヶ月前057.5K
n8n 無料クラウド導入ガイド:ハグ顔でパブリックアクセス背景:なぜパブリックアクセスが必要なのか n8n n8nは強力なオープンソースのワークフロー自動化ツールであり、ユーザーは様々なアプリケーションやサービスを接続して自動化されたプロセスを作成することができる。しかし、使用中にn8nの多くのAppノード(特にサードパーティのサービス付与に関わるもの)が...AIハンズオンチュートリアル12ヶ月前088.3K
セルフパブリッシング・プラットフォームの質問にAIで答えて小遣い稼ぎ。ヘッドライン、WeChat Ask、Baikeなど。ヘッドラインを例にしてみましょう。 1.あなたは、Androidエミュレータが必要な場合があります(いくつかのプラットフォームは、APPでの操作のみを許可し、効率が悪い、コンピュータがAndroidエミュレータをダウンロードすることをお勧めします)2.トピック、答えるべき質問を見つける このようなリアルタイムのメッセージをしないでください...AIユーティリティ・コマンド12ヶ月前059.5K
永続的なマイクロソフトQRコードのサーバーフリー生成概要 serverless-qrcode-hubは、WeChatのグループチャットでQRコードが頻繁に失敗する問題を解決するために設計されたオープンソースツールです。Cloudflare WorkersとD1データベースをベースにしており、従来のサーバーを必要としません。AIハンズオンチュートリアル# AI Java オープンソースプロジェクト12ヶ月前071.5K
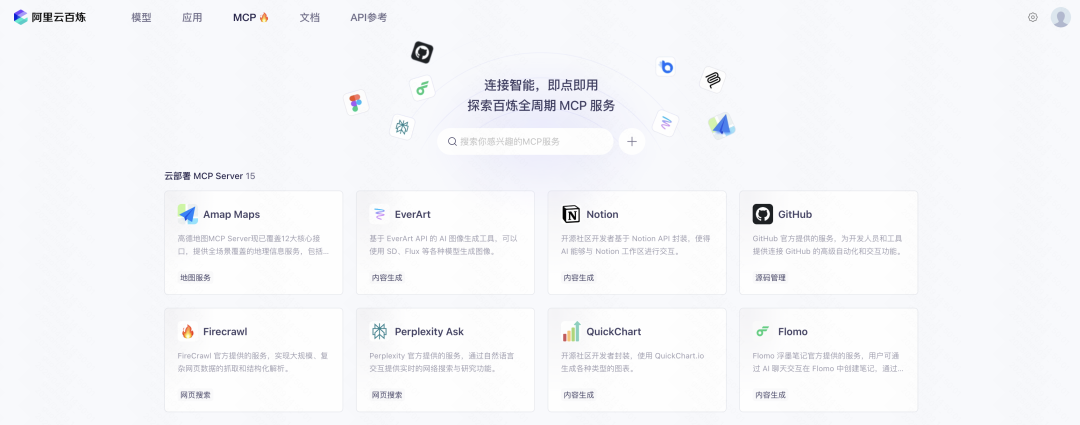
AliCloud百錬MCPサービス評価とエージェント構築の実践最近、MCP(Model Calling Protocol)という言葉が技術界で頻繁に使われるようになった。簡単に言えば、MCPは、大規模言語モデル(LLM)用の外部ツールやサービスを使用するプロセスを簡素化し、開発者やユーザーが構築する必要性を大幅に減らすように設計されている。AIハンズオンチュートリアル12ヶ月前062.4K
Crawl4AIを使いこなす:LLMとRAGのための高品質ウェブデータの準備従来のウェブクローラーフレームワークは汎用性が高いが、データを処理する際に追加のクレンジングやフォーマットが必要になることが多く、大規模言語モデル(LLM)との統合が比較的複雑になっている。多くのツールの出力(生のHTMLや構造化されていないJSONなど)には多くのノイズが含まれており、直接使用するには適していません...AIハンズオンチュートリアル12ヶ月前086.4K
自分の写真からQ-Mengスタイルの漫画ステッカーセットを生成します! アバターをアップロードして、以下のプロンプトを入力してください。 プロンプト ユーザーのイメージをフィーチャーした6つのユニークなポーズで、新しいちびステッカーを作成します。AIユーティリティ・コマンド12ヶ月前058.8K
マジックはマジックを打ち負かす:ジュビリー合格のためのヒント・ワード 前後例によるAI検出Jubileeの大規模なモデルのAIコンテンツ検出を突破しようとして以来、技術記事は、 "洗濯 "プロンプトワードをリリースしました。JubileeのAI検出で "人工的な "と識別された上記の2つの割合は高くありません。 その理由は非常に簡単で、前提の元の構造と情報内容を破壊することなく記事を書き換えることで、基本的にAIの上で行うことは困難である。AIユーティリティ・コマンド10ヶ月前072.6K
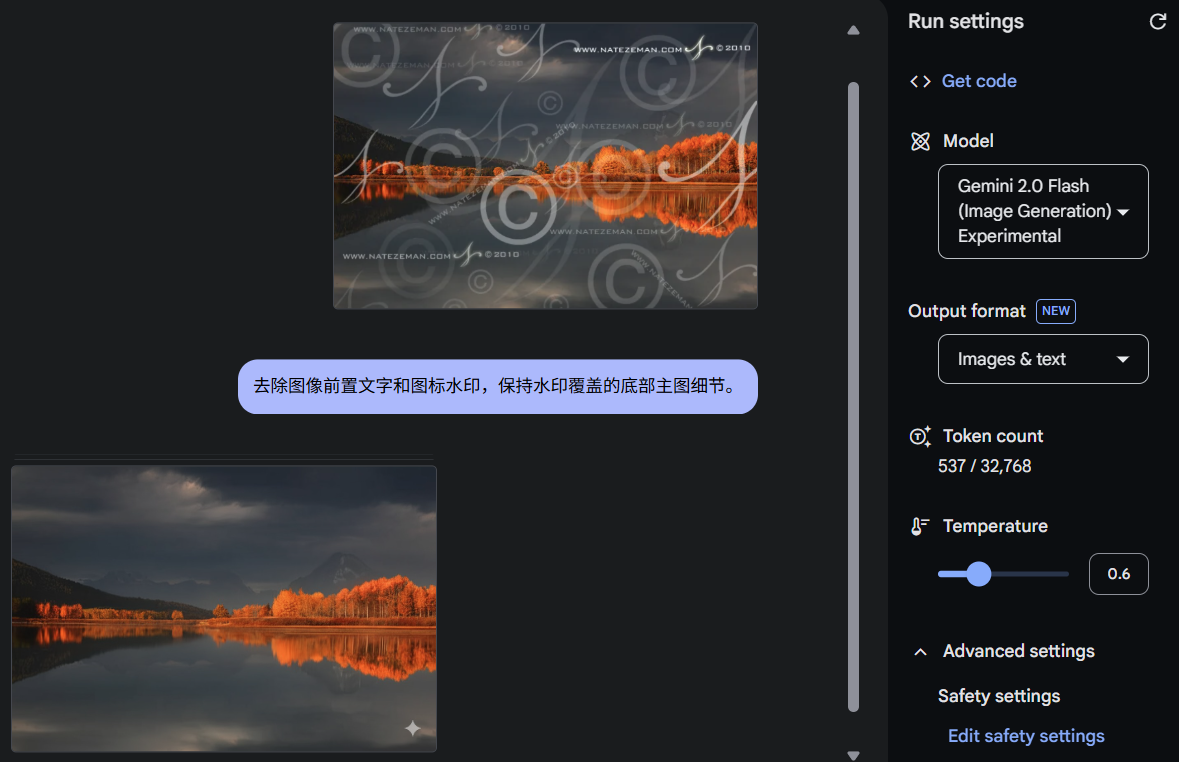
Gemini 2.0 フラッシュ 画像透かしの簡単な除去プロンプトの単語 画像から透かしを取り除く 前面のテキストとアイコン、(その他の要件)... # 以下のプロンプトは同じ効果があります 画像から透かしを取り除く どこで使うのですか? Google AI Studi...AIユーティリティ・コマンド12ヶ月前072.4K
GTRフレームワーク:異種グラフと階層検索に基づくクロステーブルQ&Aの新しいアプローチ1.はじめに 今日の情報爆発では、大量の知識がウェブページ、ウィキペディア、リレーショナ ルデータベースのテーブルの形で保存されている。しかし、従来の質問応答システムは、複数のテーブルにまたがる複雑なクエリを処理するのに苦労することが多く、人工知能の分野では大きな課題となっている。この課題に対処するため、研究者たちは...AI知識ベース1年前047.2K
Cloudflare AI Gateway設定ガイド:AI APIコールサービスの一元化大規模言語モデル(LLM)や様々なAIサービスの普及に伴い、開発者がアプリケーションにこれらの機能を統合することが一般的になりつつある。しかし、OpenAIやHugging Faceなどのサービス・プロバイダーからAPIエンドポイントを直接呼び出すと、多くの場合、管理...AIハンズオンチュートリアル1年前082.1K
ヴァンセンヌのキューワードを拡張するフレームワーク:AI画像生成の改善近年、さまざまなTTI(Text-to-Image)AI技術が急速に発展している。しかし、初心者からプロのクリエイターまで、これらのツールを活用する際にしばしば直面するのが、頭の中にあるクリエイティブなビジョンを、明確であれ曖昧であれ、いかに洗練されたものに変換するかという課題だ。AIユーティリティ・コマンド1年前062.9K
Copilot エージェントの機能の拡張:VS Code MCP 構成の詳細VS Code 1.99でモデル・コンテキスト・プロトコルのサポートを導入 Visual Studio Code(VS Code)は、1.99リリースでモデル・コンテキスト・プロトコル(MCP)のサポートを正式に導入した。AIハンズオンチュートリアル1年前0102.2K
AI搭載ウェブコンテンツキャプチャツール - Obsidian Web Clipperウェブコンテンツを効果的に取り込み、整理し、活用することは、デジタル情報がますます豊かになる今日、重要なスキルとなっている。Notion、Instapaper、Readwiseなどのツールを試したことがあるユーザーの多くは、不完全なコンテンツの取り込み、不便な検索管理...に遭遇するかもしれない。AIハンズオンチュートリアル1年前066.8K
Button i.e. Dream 3.0モデルを使って、記事グラフィックや中国語ポスターを簡単に作成できる。その夢が提供する3.0画像生成モデル枠は常に十分ではなく、今日のストレートテストは使い切ることはありません。また、その夢を直接記事の表紙を生成する日常的な使用もやや不便である。 そこで、その夢の3.0画像モデル(標準名はseedream3.0...)を参考にバックルを使うことを考えた。AIハンズオンチュートリアル12ヶ月前063.2K
リトル・レッド・ブックの表紙をより人目を引くものにする方法黒板の前で講義をしているピチピチのプロフェッショナルな服(OLスタイル)を着た女性教師の写真を生成し、全体はただ黒板と女性教師が必要で、女性教師は25歳くらいで、メガネをかけていて、セクシーな体つきをしていて、アジアの美学に沿ったルックスで、現実的なスタイルである必要があり、黒板には「よく勉強し、毎日...」と書かれている。AIユーティリティ・コマンド1年前055.9K
ライティングとビジネス報告のナビゲート:起業家の効率アップに役立つDeepSeekの8つのプロンプトテンプレート数あるAIチャットボットの中でも、DeepSeekは無料で使えるだけでなく、中国語のタスクを処理し、ビジネス分析を支援する優れた能力で注目されている。強力な大規模言語モデルとして、DeepSeekは中国語の文脈を理解し...AIユーティリティ・コマンド1年前051.5K
MCP設定とハンズオン:AIと共通アプリケーションの接続チュートリアル最近、MCP(Model Context Protocol)が技術愛好家や開発者コミュニティで注目を集めている。この技術は、ラージ・ランゲージ・モデル(LLM)が様々な外部ツールやサービスと相互作用する方法を簡素化することを目的としたもので、私たちのやり方を再構築することが期待されている。AIハンズオンチュートリアル1年前071.2K
ChatGPTはjson構造化キューワードを使って3Dアイコンを生成する楽しくて便利なgpt-4oマッピングのプロンプトをミニマルな3Dイラストスタイルで。 いくつかテストして安定した結果が得られたので、最後の画像はオリジナルの一押しから。 適切に使えば、資料(記事、ウェブサイト、販促物)に多くのポイントを加えることができるはずだ。 プロム...AIユーティリティ・コマンド1年前068.6K
AIにおける剽窃の防止:インストラクショナル・デザインからの防止戦略と実践人工知能(AI)の普及は教育界に変革の機会をもたらしたが、同時に深刻な課題も伴っており、その最たるものがアカデミック・インテグリティへの影響である。AIツールがテキストを生成できるようになったことで、伝統的な意味での剽窃の境界が曖昧になり、教育者にとってかつてない困難が生じた。AIハンズオンチュートリアル1年前056.3K
ChatGPTプロジェクトとGPTで生産性向上ChatGPTは単なる対話アシスタントではなく、ユーザーが反復的なタスクやプロジェクトを体系的に処理できるよう、より高度な機能を提供しています。今回はChatGPTのプロジェクトとGPT(カスタマイズGPT)を紹介します ...AIアンサー1年前069.8K
ChatGPTが肖像画のデュアルスタイル比較キューワードを生成キュー・ワード 宮崎駿の正面からクローズアップしたドラマチックなポートレート。 構図は完璧にシンメ...AIユーティリティ・コマンド1年前056.9K
Gemini 2.5とThree.jsが出会えば、デモアニメーションを教えるソリューションが完成する!Three.jsは、ウェブページに「3次元」画像を表示するためのツールだ。開発者がウェブページに立方体や球体などの3D図形を描けるようにするツール一式を提供する。 また、これらの3D図形を動かすこともできる。AIハンズオンチュートリアル12ヶ月前063.7K
ChatGPTが手書きメモ風画像を生成 追記:リトルレッドブックのノートカバーやマルチイメージノートを作成するには、やはりかなり便利です。 プロンプト・ワード・クリエイト・ピクチャー A4サイズの紙の上に、次の文章のコンセプトを説明する中国語の独白をペンと青インクで書いてください。その上に赤いマーカーペンで印を書き、他の人の参考になるようにする。AIユーティリティ・コマンド1年前079.1K
シームレスなテクスチャ画像を生成するChatGPTのキュー プロンプトワードの例 "ファンタジーRPGにインスパイアされた、シームレスで舗装可能な、手描きの石畳の道路のテクスチャを生成してください。" "異なるサイズの石と自然なアースカラーが特徴で、ゲームでの使用に適しており、高解像度です。" "シームレスで継ぎ目のない金属表面のテクスチャを作成...AIユーティリティ・コマンド1年前051.3K
Geminiで画像をWojakスタイル画像に変換する最近ジブリ新海誠を見て嘔吐、少し楽しいプレー。 将来的にのみ、より市場性の高いWojakスタイルの画像。 安定しすぎていない、そのような詳細に記述することができる: "背景のスタイルを維持するために、既存のキャラクターのライン、輪郭、顔の特徴を維持するために全体としてフロントキャラクターの画像は、変更されないまま、唯一のフロントキャラクターを回すために...AIユーティリティ・コマンド1年前054K
EQ-Bench 大規模言語モデルにおける感情的知性と創造性の評価方法ラージ・ランゲージ・モデル(LLM)の能力が急速に進化する中、MMLUのような従来のベンチマーク・テストでは、トップ・モデルを見分けることに限界が見えてきています。知識クイズや標準化されたテストに頼るだけでは、実世界でのやり取りにおいて重要なモデルのニュアンスに富んだ能力を完全に測定することは難しくなっています。AI知識ベース1年前066.6K
Graphiti MCP、カーソルに永続的なメモリを提供AIによるソフトウェア開発の人気が高まるにつれて、重要な課題が浮上している。それは、AIコーディングアシスタントが人間の開発者のようにセッションを横断する「記憶」を持ち、プロジェクトのコーディング仕様、嗜好、特定のプロセス、さらには要件の詳細まで記憶して適用できるようにするにはどうすればいいか、ということだ。現在、人気のある...AIハンズオンチュートリアル1年前065.3K
大きな言語モデルによる推論:「アンダーシンキング」と「オーバーシンキング」のバランス大規模言語モデル(LLM)は急速に進化しており、その推論能力は知能レベルを示す重要な指標となっている。特に、OpenAIのo1、DeepSeek-R1、QwQ-32B、Kimi K1.5のような長い推論能力を持つモデル...AI知識ベース1年前054K