
ジョイジェン:音声駆動型3D奥行き認識型トーキングビデオ編集ツール

はじめに
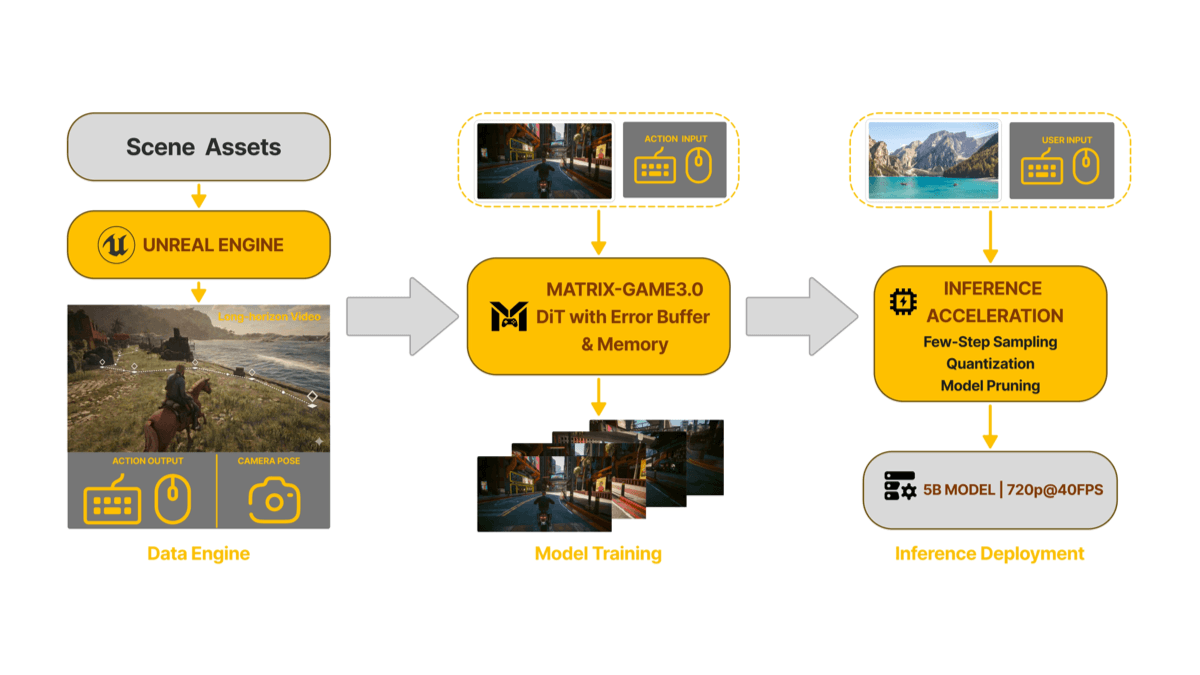
JoyGenは、音声による表情生成の問題を解決することに焦点を当てた、革新的な2段階のトーキングフェイス映像生成フレームワークである。Jingdong Technologyのチームによって開発されたこのプロジェクトは、高度な3D再構成技術と音声特徴抽出法を採用し、話者のアイデンティティ特徴と表情係数を正確にキャプチャして、高品質のリップシンクロとビジュアル合成を実現する。JoyGenフレームワークは、主に2つのフェーズで構成される。第1に、音声ベースのリップモーション生成、第2に、ビジュアルアピアランス合成である。音声の特徴と顔の深度マップを統合することで、正確なリップシンクロのための包括的な監視を提供する。このプロジェクトは中国語と英語の音声ドライバをサポートするだけでなく、完全な学習と推論パイプラインを提供し、強力なオープンソースツールとなっている。

機能一覧
- 音声による3D表情生成と編集
- 正確なリップシンク・オーディオ技術
- 中国語と英語の音声入力に対応
- 3D奥行き知覚のための視覚合成
- 顔の同一性保持機能
- 高品質のビデオ生成と編集機能
- 完全なトレーニングと推論フレームワークのサポート
- 訓練済みモデルが迅速な展開をサポート
- カスタマイズされたデータセットのトレーニングをサポート
- 詳細なデータ前処理ツールの提供
ヘルプの使用
1.環境構成
1.1 インフラ要件
- 対応GPU:V100、A800
- Pythonバージョン:3.8.19
- システム依存: ffmpeg
1.2 インストール手順
- conda環境を作成し、有効化する:
conda create -n joygen python=3.8.19 ffmpeg
conda activate joygen
pip install -r requirements.txt
- Nvdiffrastライブラリをインストールする:
git clone https://github.com/NVlabs/nvdiffrast
cd nvdiffrast
pip install .
- 訓練済みモデルのダウンロード
提供されたものからダウンロードリンク事前に訓練されたモデルを取得し、指定されたディレクトリ構造に従ってそれを./pretrained_models/カタログ
2.ご利用の流れ
2.1 推論プロセス
完全な推論パイプラインを実行します:
bash scripts/inference_pipeline.sh 音频文件 视频文件 结果目录
推論プロセスを段階的に実行する:
- 音声から表情係数を抽出する:
python inference_audio2motion.py --a2m_ckpt ./pretrained_models/audio2motion/240210_real3dportrait_orig/audio2secc_vae --hubert_path ./pretrained_models/audio2motion/hubert --drv_aud ./demo/xinwen_5s.mp3 --seed 0 --result_dir ./results/a2m --exp_file xinwen_5s.npy
- 新しい表現係数を使用して深度マップをフレームごとにレンダリングする:
python -u inference_edit_expression.py --name face_recon_feat0.2_augment --epoch=20 --use_opengl False --checkpoints_dir ./pretrained_models --bfm_folder ./pretrained_models/BFM --infer_video_path ./demo/example_5s.mp4 --infer_exp_coeff_path ./results/a2m/xinwen_5s.npy --infer_result_dir ./results/edit_expression
- 音声の特徴と顔の深度マップに基づいて顔のアニメーションを生成する:
CUDA_VISIBLE_DEIVCES=0 python -u inference_joygen.py --unet_model_path pretrained_models/joygen --vae_model_path pretrained_models/sd-vae-ft-mse --intermediate_dir ./results/edit_expression --audio_path demo/xinwen_5s.mp3 --video_path demo/example_5s.mp4 --enable_pose_driven --result_dir results/talk --img_size 256 --gpu_id 0
2.2 トレーニング・プロセス
- データの前処理:
python -u preprocess_dataset.py --checkpoints_dir ./pretrained_models --name face_recon_feat0.2_augment --epoch=20 --use_opengl False --bfm_folder ./pretrained_models/BFM --video_dir ./demo --result_dir ./results/preprocessed_dataset
- 前処理されたデータを調べ、トレーニングリストを作成する:
python -u preprocess_dataset_extra.py data_dir
- トレーニングを開始する:
config.yamlファイルを修正して実行する:
accelerate launch --main_process_port 29501 --config_file config/accelerate_config.yaml train_joygen.py© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません