DeepSeek-R1の複製:8Kの数学的事例が強化学習による推論のブレークスルーを小さなモデルにもたらす

Github。 https://github.com/hkust-nlp/simpleRL-reason
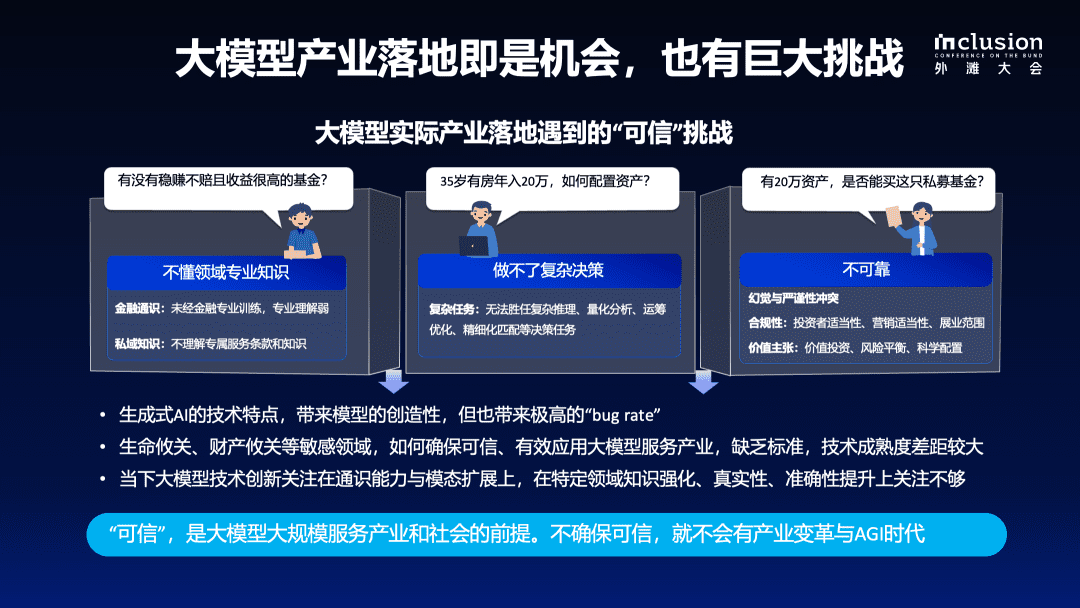
紹介

Qwen2.5-SimpleRL-Zeroの動的バリエーション。Qwen2.5-Math-7Bのベースモデルから開始し、SFTを実行せず、報酬モデルも使用しない。ベンチマークの平均精度と長さは、8つの複雑な数学的推論ベンチマークに基づいている。Qwen2.5-Math-7Bベースモデルは、言語とコードの両方を応答として生成する傾向があり、その結果、出力が長くなる。このデフォルトパターンはRL中にすぐに抑制され、モデルはより適切なフォーマットで出力することを学習し、その後、長さは規則的に増加し始めました。わずか数回のトレーニングステップで、DeepSeek-R1の論文で「epiphany moment(啓示の瞬間)」と表現されているような、モデルの応答における自己反省も経験しました。
多くの研究者が、蒸留、MCTS、プロセスベースの報酬モデル、強化学習など、O型モデルを学習するための可能な道を模索している。最近ではディープシーク-R1歌で応えるキミk1.5このゴールへの道程で、MCTSや報酬モデルを使用せずに、単純なRLアルゴリズムを使用して、長時間の連鎖思考(CoT)と自己反省の創発パターンを学習し、強力な結果を得るための極めてシンプルなレシピを実証した。しかし、彼らの実験は大規模なRLセットアップにおける巨大なモデルに基づいている。より小さなモデルでも同様の振る舞いを示すことができるのか、どれだけのデータが必要なのか、定量的な結果が他の手法とどのように比較されるのかは不明である。このブログでは、Qwen-2.5-Math-7B(ベースモデル)から開始し、ルールベースの報酬モデルによるRLのためのオリジナルのMATHデータセットから8K例(クエリ、最終回答)のみを使用して、複雑な数学的推論に関するDeepSeek-R1-ZeroとDeepSeek-R1のトレーニングを再現します。MATHの例だけを使うことで、他の外部信号なしに、この7Bの基本モデルをここまで持ち上げることができることに驚いた:
結果はすべてパス@1の精度
| AIME 2024 | 数学500 | AMC | ミネルバ算数 | オリンピアードベンチ | 平均。 | |
|---|---|---|---|---|---|---|
| Qwen2.5-Math-7B-Base | 16.7 | 52.4 | 52.5 | 12.9 | 16.4 | 30.2 |
| Qwen2.5-Math-7B-Base + 8K MATH SFT | 3.3 | 54.6 | 22.5 | 32.7 | 19.6 | 26.5 |
| クウェン-2.5-数学-7B-インストラクター | 13.3 | 79.8 | 50.6 | 34.6 | 40.7 | 43.8 |
| Llama-3.1-70B-Instruct | 16.7 | 64.6 | 30.1 | 35.3 | 31.9 | 35.7 |
| rStar-Math-7B | 26.7 | 78.4 | 47.5 | - | 47.1 | - |
| ユーラス-2-7B-プライム | 26.7 | 79.2 | 57.8 | 38.6 | 42.1 | 48.9 |
| Qwen2.5-7B-シンプルRL-ゼロ | 33.3 | 77.2 | 62.5 | 33.5 | 37.6 | 48.8 |
| Qwen2.5-7B-シンプルRL | 26.7 | 82.4 | 62.5 | 39.7 | 43.3 | 50.9 |
Qwen2.5-7B-SimpleRL-Zeroは、ベースモデルから直接、8K MATH例のみを使用したシンプルなRLトレーニングです。ベースモデルと比較して、平均で20ポイント近い絶対的な成長を達成しています。さらに、Qwen2.5-7B-SimpleRL-Zero は、Qwen-2.5-Math-7B-Instruct を平均で上回り、最近リリースされた Qwen-2.5-Math-7B-Instructと比較しても優れています。ユーラス-2-7B-プライム歌で応えるrStar-Math-7B(これらはQwen-2.5-Math-7Bにも基づいている)とほぼ同等である。これらのベースラインは、報酬モデルなどのより複雑なコンポーネントを含み、少なくとも50倍以上の高度なデータを使用している:
さまざまな方法の比較データ
| Qwen2.5-数学-7B-インストラクター | rStar-Math-7B | ユーラス-2-7B-プライム | Qwen2.5-7B-シンプルRL-ゼロ | |
|---|---|---|---|---|
| ベースモデル | Qwen2.5-数学-7B | Qwen2.5-数学-7B | Qwen2.5-数学-7B | Qwen2.5-数学-7B |
| SFTデータ | 250万ドル(オープンソースおよび自社製) | ~7.3M(MATH、NuminaMathなど) | 230K | 0 |
| RMデータ | 618K(社内) | ~7 k(社内) | 0 | 0 |
| RM | クウェン2.5-Math-RM(72B) | なし | ユーラス-2-7B-SFT | なし |
| RLデータ | 66Kクエリー×32サンプル | ~3.647 M × 16 | 150Kクエリー×4サンプル | 8Kクエリー×8サンプル |
我々は、わずか8KのMATH例で達成された大幅な成長に興奮し、驚いている。注目すべきは、**MATHクエリはAIMEやAMCのような多くの困難なベンチマークよりもはるかに実行しやすいにもかかわらず、この単純なRL定式化は、ベースモデルと比較して少なくとも10絶対ポイント性能を向上させ、有意な汎化力を示していることです。**このわかりやすい汎化効果は、同じデータセットで標準的なSFTトレーニングを行うことでは予測できなかったものです。我々は、このトレーニングコードと詳細を完全にオープンソース化し、コミュニティが推論におけるRLの可能性をさらに探求するための強力なベースライン設定として役立つことを期待している。
次に、私たちのセットアップの詳細と、長いCoTや自己反省パターンの出現など、このRLトレーニングのプロセスで何が起こるのかについて掘り下げていく。
シンプルなRLのレシピ
DeepSeek R1 と同様に、我々の RL の定式化は非常にシンプルで、報酬モデルや MCTS のような技法は使用しません。生成された応答の形式と正しさに基づいて報酬を割り当てる、ルールベースの報酬関数を持つPPOアルゴリズムを使用する:
- 指定された形式で最終的な答えを提示し、それが正しければ、+1のボーナスが与えられる。
- その回答が最終的な回答であるが不正解であった場合、報酬は-0.5に設定される。
- 回答が最終的な答えを提供できなかった場合、報酬は-1に設定される。
実装はオープンRLHF.我々の予備実験によれば、この報酬関数は、戦略モデルが迅速に収束し、望ましい形式の応答を生成するのに役立つ。
実験セットアップ
私たちの実験ではQwen2.5-Math-7B-Baseモデルは、AIME2024、AMC23、GSM8K、MATH-500、Minerva Math、およびOlympiadBenchを含む難易度の高い数学的推論ベンチマークで開始され、評価された。トレーニングは、難易度レベル3~5のMATHトレーニングデータセットから約8,000クエリを使用して実行された。DeepSeek-R1-ZeroとDeepSeek-R1に従って、それぞれ以下の2つの設定で実験を行った:
- シンプルなRL-ゼロSFTを行わず、ベースモデルから直接RLを行う。8K MATH (query, answer)のペアのみを使用する。
- シンプルRLSFTデータは、QwQ-32B-Previewから抽出された8K MATHクエリとその応答である。次に、同じ8K MATHの例をRLの定式化に使用する。
パート1:シンプルなRL-ゼロ ゼロからの集中学習
SimpleRL-ZeroはQwen2.5-Math-7B-Instructを上回り、PRIMEやrStar-Mathと同等の結果を達成した。以下では、学習ダイナミクスといくつかの興味深いパターンを紹介する。
トレーニング・ダイナミクス
トレーニングのインセンティブと展開される反応の長さ

8つのベンチマークにおける精度(pass@1)と応答長さの評価

上図に示すように、すべてのベンチマークにおいて、学習中の精度は着実に向上しているが、長さは最初に減少し、その後徐々に増加している。さらに調べてみると、Qwen2.5-Math-7Bのベースモデルは、最初に大量のコードを生成する傾向があり、これはモデルの元々の学習データ分布に起因していると考えられる。RLの学習により、このパターンが徐々に排除され、通常の言語による推論ができるようになるため、まず生成長が減少することがわかった。その後、次の例のように、生成長が再び増加し始め、自己反省的なパターンが現れ始める。
自己反省の出現
ステップ40くらいで、モデルが自己反省的なパターン、つまりDeepSeek-R1の論文の「啓示の瞬間」を生成し始めることがわかります。以下にその例を示す。

パート II: シンプルRL 模倣的なウォームアップ練習による集中学習
前述したように、RLに進む前に長時間連鎖的思考を行うSFTでウォームアップを行った。SFTデータセットは、QwQ-32B-Previewから回答を抽出した8KのMATH例である。このコールドスタートの潜在的な利点は、モデルが長い連鎖思考モードからスタートし、すでに自己反省していることである。
主な成績
| AIME 2024 | 数学500 | AMC | ミネルバ算数 | オリンピアードベンチ | 平均。 | |
|---|---|---|---|---|---|---|
| Qwen2.5-Math-7B-Base | 16.7 | 52.4 | 52.5 | 12.9 | 16.4 | 30.2 |
| Qwen2.5-Math-7B-Base + 8K QwQ 蒸留 | 16.7 | 76.6 | 55.0 | 34.9 | 36.9 | 44.0 |
| ユーラス-2-7B-プライム | 26.7 | 79.2 | 57.8 | 38.6 | 42.1 | 48.9 |
| Qwen2.5-7B-シンプルRL-ゼロ | 36.7 | 77.4 | 62.5 | 34.2 | 37.5 | 49.7 |
| Qwen2.5-7B-シンプルRL | 26.7 | 82.4 | 62.5 | 39.7 | 43.3 | 50.9 |
Qwen2.5-Math-7B-Base+8KQwQ蒸留と比較すると、RL学習前のQwen2.5-7B-SimpleRLを絶対値で平均6.9%向上させた。さらに、Qwen2.5-7B-SimpleRL は 5 つのベンチマークのうち 3 つで Eurus-2-7B-PRIME を上回り、Qwen2.5-7B-SimpleRL-Zero を上回った。の強力な長鎖思考教師モデルであることを考えると、QwQ蒸留段階がゼロ設定よりも大きな利益をもたらさなかったことは少し驚きである。
トレーニング・ダイナミクス
トレーニングのインセンティブと展開される反応の長さ

トレーニングステート
8つのベンチマークにおける精度(pass@1)と応答長さの評価

Qwen2.5-SimpleRLのトレーニングダイナミクスはQwen2.5-SimpleRL-Zeroに似ている。興味深いことに、RLの最初の方では、SFTの高度な長時間連鎖思考にもかかわらず、長さの減少が観察される。これは、抽出されたQwQ推論パターンが、小さな戦略モデルに好まれないか、あるいはその能力を超えているためだと思われる。その結果、SFTはQwQ推論を放棄することを学習し、自ら新しい長い推論を開発するのである。
結語
シンプルさは究極の複雑さである。
- レオナルド・ダ・ヴィンチ(1452-1519)イタリア・ルネサンス期の画家
謝辞と引用
我々が実装した強化学習アルゴリズムは、以下のものに基づいている。オープンRLHFより拡大。私たちはブイエルエルエムに基づいて推論を行い、アルゴリズムを開発する。Qwen2.5-数学評価スクリプトの開発者に感謝します。特に、DeepSeek-R1とKimi-k1.5の開発者の革新とオープンソースコミュニティへの貢献に感謝します。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません