FineVision - Hugging Faceがオープンソースの視覚言語データセットを発表

ファインビジョンとは
FineVisionは、高度な視覚言語モデルをトレーニングするためのHugging Faceのオープンソースの視覚言語データセットです。1,730万枚の画像、2,430万個のサンプル、8,890万ラウンドの対話、95億個の回答トークンが含まれています。このデータセットは200以上のソースからのデータを集約し、マルチモーダルかつマルチラウンドの対話を特徴としており、視覚と言語の組み合わせをサポートしている。各画像には、モデルが自然言語を理解し生成するのに役立つテキスト・キャプションが添えられています。 FineVisionは、10個のベンチマークで平均20%以上の性能向上に貢献しました。ハギング・フェイスの datasets このライブラリを使えば、データセットを簡単に読み込んで使うことができる。
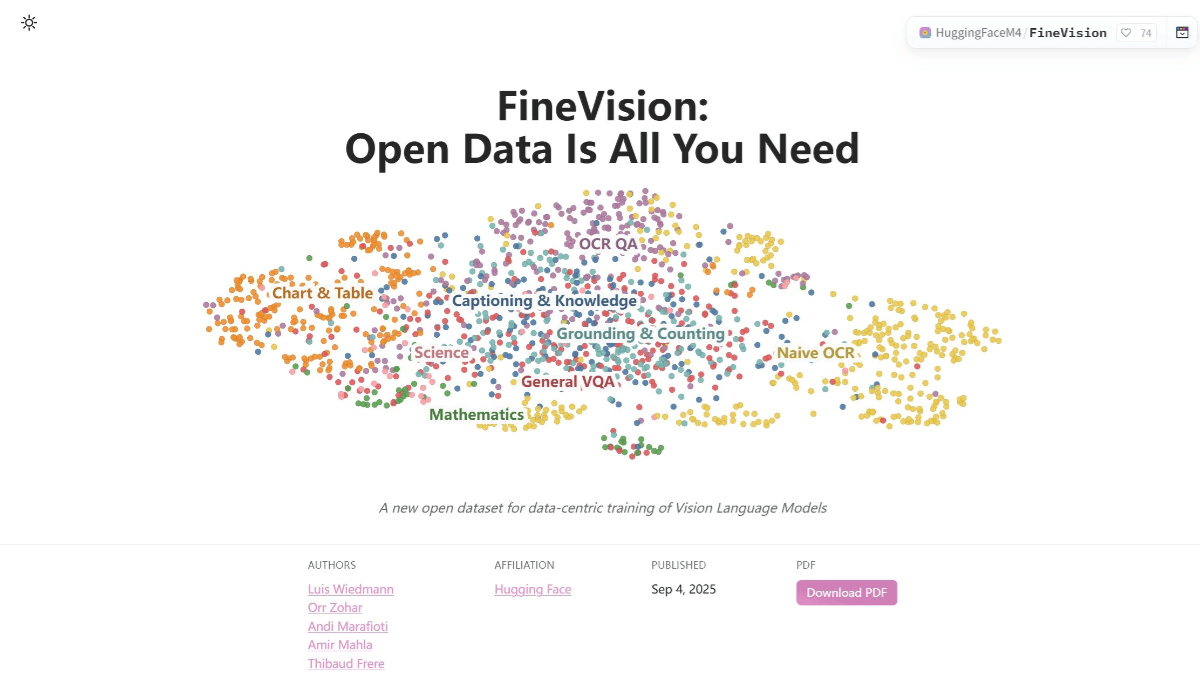
ファインビジョンの特徴
- マルチモーダルフュージョン画像とテキストを組み合わせることで、視覚情報と言語情報の両方を処理できるようになり、複雑なシーンの理解が向上する。
- 多ラウンド対話データ自然言語のコミュニケーションパターンをモデルが学習し、対話能力を向上させるために、豊富なマルチラウンド対話サンプルを提供します。
- 膨大なデータ量膨大な画像とテキストのサンプルを持つことは、モデルの学習に十分なリソースを提供し、モデルの汎化を促進します。
- パフォーマンスの大幅な改善ヘルプモデルは、複数のベンチマークで性能を大幅に向上させ、視覚言語モデリング技術を進歩させます。
- オープンソースで使いやすいハギング・フェイスズ経由
datasetsライブラリを使えば、ユーザーは簡単にデータセットをロードして利用することができ、利用への障壁が低くなる。
ファインビジョンの強み
- 膨大なデータモデル学習に十分なリソースを提供するために、膨大な画像とテキストのサンプルを含んでいます。
- マルチモーダルフュージョン画像とテキストを統合することで、視覚情報と言語情報を一緒に処理する能力を向上させる。
- 多ラウンド対話支援豊富な多ラウンド対話データにより、モデルの対話能力と言語理解の深さを向上。
ファインビジョンの公式ウェブサイトは?
- プロジェクトのウェブサイト:: https://huggingface.co/spaces/HuggingFaceM4/FineVision
- HuggingFaceデータセット:: https://huggingface.co/datasets/HuggingFaceM4/FineVision
ファインビジョンの対象者
- 人工知能研究者視覚言語モデルの開発と最適化、新しいアルゴリズムとアーキテクチャの探求。
- 機械学習エンジニアFineVisionのデータセットを実際のプロジェクトに適用し、モデルのパフォーマンスを向上させます。
- 自然言語処理(NLP)エキスパート言語理解とモデル生成の向上に重点を置く。
- コンピュータ・ビジョンの専門家視覚認識と理解を向上させるための画像データの利用。
- データサイエンティスト大規模なマルチモーダルデータを分析・処理し、その価値をマイニングする。
- 学生と教育者視覚言語モデルを理解し、練習するための教材として。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事

コメントはありません