
分かりやすい記事 知識の蒸留(ディスティレーション):「小さなモデル」にも「大きな知恵」を持たせよう。

知識蒸留は、事前に訓練された大きなモデル(すなわち「教師モデル」)から、より小さな「生徒モデル」へと学習を移行させることを目的とした機械学習技術である。蒸留技術は、知的対話やコンテンツ作成などの分野で使用する、より軽量な生成モデルの開発に役立ちます。
最寄り 蒸留 この言葉はよく目にする。
2日前に大きな話題となったDeepSeekチームがリリースした。 ディープシーク-R1強化学習と蒸留技術により、670Bのパラメータを持つ大規模モデルの機能を7Bのパラメータを持つ軽量モデルに移行することに成功した。
蒸留されたモデルは、同じサイズの従来のモデルを凌駕し、OpenAIのトップ小型モデルであるOpenAI-o1-miniにさえ近づいている。
人工知能の分野では、大規模な言語モデル(例えばGPT-4、 ディープシーク-R1 )は、数千億のパラメータを持つ優れた推論と生成能力を実証してきた。しかし、その膨大な計算量と高い導入コストは、モバイル機器やエッジコンピューティングなどのシナリオでの適用を厳しく制限している。
パフォーマンスを落とさずにモデルサイズを圧縮するには?知識の蒸留(知識蒸留)は、この問題を解決するための重要なテクニックである。
1.知識の蒸留とは何か
知識蒸留は、事前に訓練された大きなモデル(すなわち「教師モデル」)から、より小さな「生徒モデル」に学習を移行させることを目的とした機械学習技術である。
ディープラーニングでは、特に大規模なディープニューラルネットワークにおいて、モデル圧縮と知識伝達の一形態として使用される。
知識の蒸留の本質は知識の移動教師モデルの出力分布を模倣することで、生徒モデルはその汎化能力と推論ロジックを継承します。
- 教師モデル(教師モデル):通常、多数のパラメータと十分なトレーニングを備えた複雑なモデル(例:DeepSeek-R1)で、その出力には予測結果だけでなく、暗黙的にカテゴリ間の類似性情報も含まれる。
- 学生モデル(生徒モデル:教師モデルのソフトターゲットに合わせることで、能力の伝達を可能にした、パラメータが少なくコンパクトなモデル。
訓練データセットで提供されるサンプル出力により近い予測を行うように人工ニューラルネットワークを訓練することが目標である従来のディープラーニングとは異なり、知識の蒸留では、生徒のモデルが正解に適合すること(難しい目標)だけでなく、教師のモデルの「思考の論理」を学習することも要求される。-つまり確率分布(ソフトターゲット)。
例えば、画像の分類タスクでは、教師モデルは「この写真は猫です」(90%確信)と示すだけでなく、「キツネのようです」(5%)、「他の動物です」(5%)などの可能性も与える。"(5%)などの可能性も示す。
これらの確率値は、試験問題を採点する際に教師がマークする「簡単な点数」のようなものである。 相関関係(例えば、ネコとキツネは耳のとがり方が似ていて、毛の特徴も似ている)をとらえることで、学生モデルはやがて、標準的な答えを機械的に暗記するのではなく、より柔軟な識別能力を身につけるようになる。
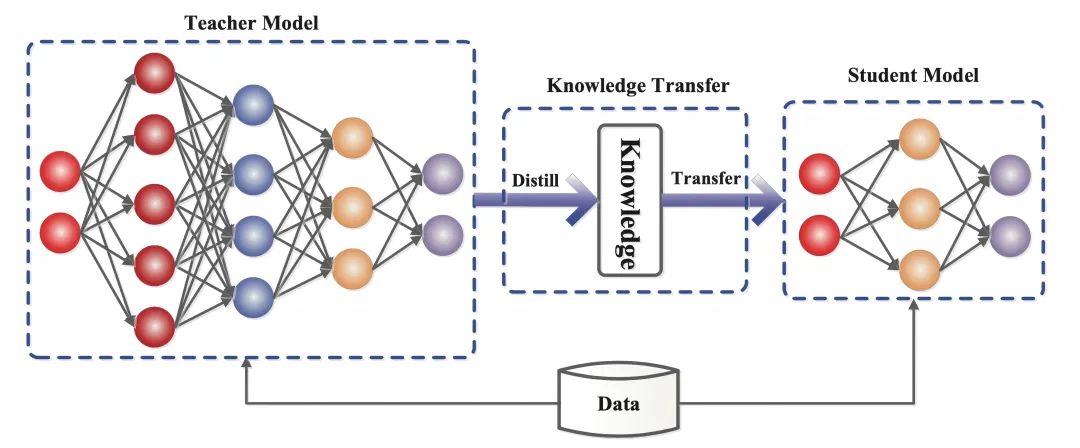
2.蒸留の仕組みに関する知識
2015年の論文『Distilling the Knowledge in a Neural Network』では、異なる目的を持つ2つの段階に訓練を分割することを提案しているが、著者らは次のようなアナロジーを描いている:多くの昆虫は、環境からエネルギーと栄養分を抽出するために最適化された幼虫の形態と、移動と繁殖のために最適化された成虫の形態があるが、従来のディープラーニングでは、要求が異なるにもかかわらず、訓練と展開の段階で同じモデルを使用している。従来のディープラーニングは、トレーニング段階と展開段階で、それぞれ異なる要件があるにもかかわらず、同じモデルを使用している。
論文における「知識」の理解もさまざまだ:
この論文が発表される以前は、学習モデルの知識と学習されたパラメータ値を同一視する傾向があり、モデルの形式を変えても同じ知識が維持されるとは考えにくかった。
知識をより抽象的にとらえれば、それは学習されたものである。入力ベクトルから出力ベクトルへのマッピング.
知識蒸留の技術は、教師のモデルのアウトプットを複製するだけでなく、教師の「思考プロセス」も模倣する。LLMの時代において、知識蒸留は、スタイル、推論能力、人間の好みや価値観との一致といった抽象的な資質の移転を可能にする。
知識蒸留の実現は、3つのコアステップに分けることができる:
2.1 ソフトターゲット生成:答えを「ファジ化」する
教師モデルは渡される高温ソフトマックスこの技術は、「白か黒か」の答えを、詳細な情報を含む「あいまいなヒント」に変換する。
温度(Temperature)が高くなるにつれて(例えばT=20)、モデル出力の確率分布はより滑らかになる。
例えば、"キャット(90%)、フォックス(5%)"と判定する。
猫(60%)、狐(20%)、その他(20%)」となる可能性がある。
この調整により、生徒のモデルはラベルを機械的に記憶するのではなく、カテゴリー間の相関関係(例えば、ネコとキツネの耳の形は似ている)に集中するようになる。
2.2 目的関数の設計:ソフト目的とハード目的のバランス
学生モデルの学習目的は2つある:
- 教師の論理的思考を真似る(ソフトターゲット):教師の高温確率分布のマッチングによるクラス間の関係の学習。
- 正解を覚えておこう。(ハードターゲット):基本的な精度の低下がないようにする。
学生モデルの損失関数は、ソフトターゲットとハードターゲットの重み付き組み合わせであり、両方の重みを動的に調整する必要がある。
例えば、ソフトターゲットに70%、ハードターゲットに30%のウェイトを割り当てる場合、生徒が70%の時間を教師の解答の研究に費やし、30%の時間を標準解答の定着に費やし、最終的に柔軟性と正確性のバランスを達成するのと似ている。
2.3 温度パラメータの動的調節、知識の「伝達粒度」の制御。
温度パラメーターは、知的蒸留の "難易度のつまみ "である:
- 高温モード(例:T=20):回答は非常に曖昧で、複雑な関連付けを伝えるのに適している(例:猫の品種を区別する)。
- 低温モード(例:T = 1): 答えは元の分布に近く、単純なタスク(例:数字の認識)に適している。
- ダイナミック戦略最初は高温で知識を吸収し、後で冷却して重要な機能に集中する。
例えば、音声認識タスクでは、精度を維持するために低い温度が必要となる。このプロセスは、教師が生徒のレベルに合わせて指導の深さを調整するのと似ている。
3.知識の蒸留の重要性
与えられたタスクに対して最高のパフォーマンスを発揮するモデルは、ほとんどの実世界のユースケースに対して大きすぎたり、遅すぎたり、高価だったりする傾向があるが、それらはそのサイズと大量の学習データで事前学習する能力から来る優れたパフォーマンスを持っている。
対照的に、より小さなモデルは、より高速で計算負荷が少ない反面、より多くのパラメータを持つより大きなモデルに比べて、正確さ、洗練度、知識において劣る。
例えば、知識の蒸留の応用の価値がここで発揮される:
DeepSeek-R1の670Bパラメータの大規模モデルは、知識蒸留技術により、その能力を7Bパラメータの軽量モデルに移行します: DeepSeek-R1-7Bは、GPT-4o-0513のような非推論モデルをすべての面で上回ります。DeepSeek-R1-32B と DeepSeek-R1-70B は、ほとんどのベンチマークで o1-mini を大幅に上回っています。
これらの結果は、蒸留の強い可能性を示している。知識蒸留は重要な技術ツールとなっている。
自然言語処理の分野では、多くの研究機関や企業が、翻訳、対話システム、テキスト分類などのタスクのために、大きな言語モデルを小さなバージョンに圧縮する蒸留技術を使用しています。
例えば、大規模なモデルを蒸留すれば、モバイルデバイスで実行でき、強力なクラウドコンピューティングリソースに依存することなく、リアルタイムの翻訳サービスを提供できる。
知識の蒸留の価値は、IoTやエッジコンピューティングではさらに大きくなる。伝統的な大規模モデルはしばしば強力なGPUクラスタサポートを必要とするが、小規模モデルはマイクロプロセッサや消費電力のはるかに低い組み込みデバイスで実行できるように蒸留される。
この技術により、導入コストが大幅に削減されるだけでなく、ヘルスケア、自律走行、スマートホームなどの分野でインテリジェント・システムがより広く利用されるようになる。
将来、知識蒸留の応用可能性はさらに広がるだろう。ジェネレーティブAIの発展とともに、蒸留技術は知的対話、コンテンツ作成、その他の分野での軽量なジェネレーティブモデルの開発に役立つだろう。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません