DeepSearch/DeepResearchにおける最適なテキストセグメントの選択とURLの再配置

すでにジーナの最後の長い名文、「ザ・クラシック」をお読みになった方は、次の記事をお読みいただきたい。DeepSearch/DeepResearchの設計と実装"であれば、答えの質を劇的に向上させることができる詳細をもう少し掘り下げてみる価値がある。今回は2つのディテールに焦点を当てる:
長いウェブページから最適なテキストセグメントを抽出するレイト・チャンキング・アルゴリズムを使って、長いウェブコンテンツから最も関連性の高いスニペットを選択する方法。 収集したURLの再編成LLM Agentが数百のURLの中からクロールするURLを賢く選択するためにRerankerを使うには?
DeepSearchでは、EmbeddingsモデルはSTS(意味的テキスト類似度)などのタスクのクエリ重複排除にのみ適しており、RerankerはDeepSearchプログラミングのオリジナル実装にすら含まれていない "という前回の記事の結論を覚えている人もいるかもしれない。
今にして思えば、どちらのタイプのリコールモデルも、我々が通常考えるような方法ではないだけで、その価値はまだある。私たちは常に検索における「80対20」の原則に従っており、情緒的な価値を考慮したり、エンベッディングやリランカーのプロバイダーとして市場での存在感を証明したりするために、モデルをハードワイヤリングしようとはしません。私たちは80対20の原則を実践しています。検索システムにとって最も必要なことだけに気を配るという点で、実用的である。
そこで、何週間も試行錯誤を繰り返した結果、DeepSearch/DeepResearchシステムにおけるEmbeddingsとRerankerの、型破りだが非常に効果的なアプリケーションを発見した。これらの方法を使用した後、私たちはJina DeepSearchの品質を大幅に向上させました(ぜひ体験してください)。私たちはまた、これらの経験をこの分野で一緒に働いている仲間たちと共有したいと思っています。
長いテキストから最適なテキストセグメントを選択
問題はこうだ。 ジーナ・リーダー ウェブページの内容を読んだら、それをエージェントが推論するための知識として、エージェントのコンテキストに入れる必要がある。コンテンツ全体を一気にLLMのコンテキストに詰め込むのが最も面倒のない方法ですが、LLMのコンテキストが トークン コストと生成スピードの点で、これが最良の選択肢でないことは確かです。実際には、問題に最も関連するコンテンツの部分を特定し、その部分のみをエージェントのコンテキストに知識として追加する必要があります。
💡 ここでは、Jina ReaderでMarkdownをクリーンアップしても、コンテンツが長すぎる場合について説明します。例えば、GitHubのIssues、Redditの投稿、フォーラムのディスカッション、ブログの投稿のような長いページです。
LLMベースのスクリーニング法にも同じようなコストとレイテンシーの問題がある:多言語をサポートする、より小型で安価なモデルが必要なのだ。質問や文書が常に中国語であるという保証はないため、これは重要な要素である。
一方には質問(オリジナルのクエリ、または「情報不足」の質問)があり、もう一方には多くのMarkdownコンテンツがある。私たちは、質問に最も関連する部分を選び出す必要があります。これは ラグ 2023年以来、コミュニティが解決しようとしてきたチャンキング問題。レトリーバー・モデルを使って、関連するチャンクだけを取り出し、要約のためのコンテキスト・ウィンドウに入れる。
しかし、我々の状況には2つの重要な違いがある:
有限個の文書に含まれる有限個のテキストブロック。
各ブロックに約500のトークンがあると仮定すると、典型的な長いウェブ文書には約20万から100万のトークンがある(99パーセンタイル)。私たちはJina Readerを使って一度に4-5個のURLをクロールし、数百のテキストブロックを生成する。これは数百のベクトルと数百の余弦類似度を意味する。これはJavaScriptでメモリ内で簡単に処理でき、ベクトルデータベースは必要ない。
知識を効果的に要約するには、連続したテキストブロックが必要だ。
1-2、6-7、9、14、17、...】のような要約は認められない。 このような散漫な文章からなる要約。より有用な知識の要約は、[3-15, 17-24, ...]のようなものでしょう。 のようなものであった方が、文章の一貫性が保たれる。そうすれば、LLMは知識ソースからのコピーや引用が容易になり、「錯覚」の数も減るだろう。
残りの部分は、開発者が文句を言うのと同じ注意点である:ベクトルモデルが長すぎるコンテキストを扱えないので、テキストの各ブロックは長すぎてはいけない;チャンキングはコンテキストの損失を招き、テキストの各ブロックのベクトルを独立かつ同一に分布させる;そして、可読性とセマンティクスの両方を維持する最適な境界線を一体どうやって見つけるのか?私たちが話していることがわかるなら、あなたのRAG実装でもこれらの問題に悩まされている可能性がある。
しかし、手短に言えば、次のようになる。 jina-embeddings-v3 な レイト・チャンキングこの3つの問題を完璧に解決する。「後期分割」は、各ブロックの文脈情報を保持し、境界の影響を受けず、そして jina-embeddings-v3 は、非対称多言語検索タスクにおける最先端の技術である。興味のある読者は、ジーナのブログ記事か論文で実装全体の詳細を見ることができる。
🔗 https://arxiv.org/pdf/2409.04701

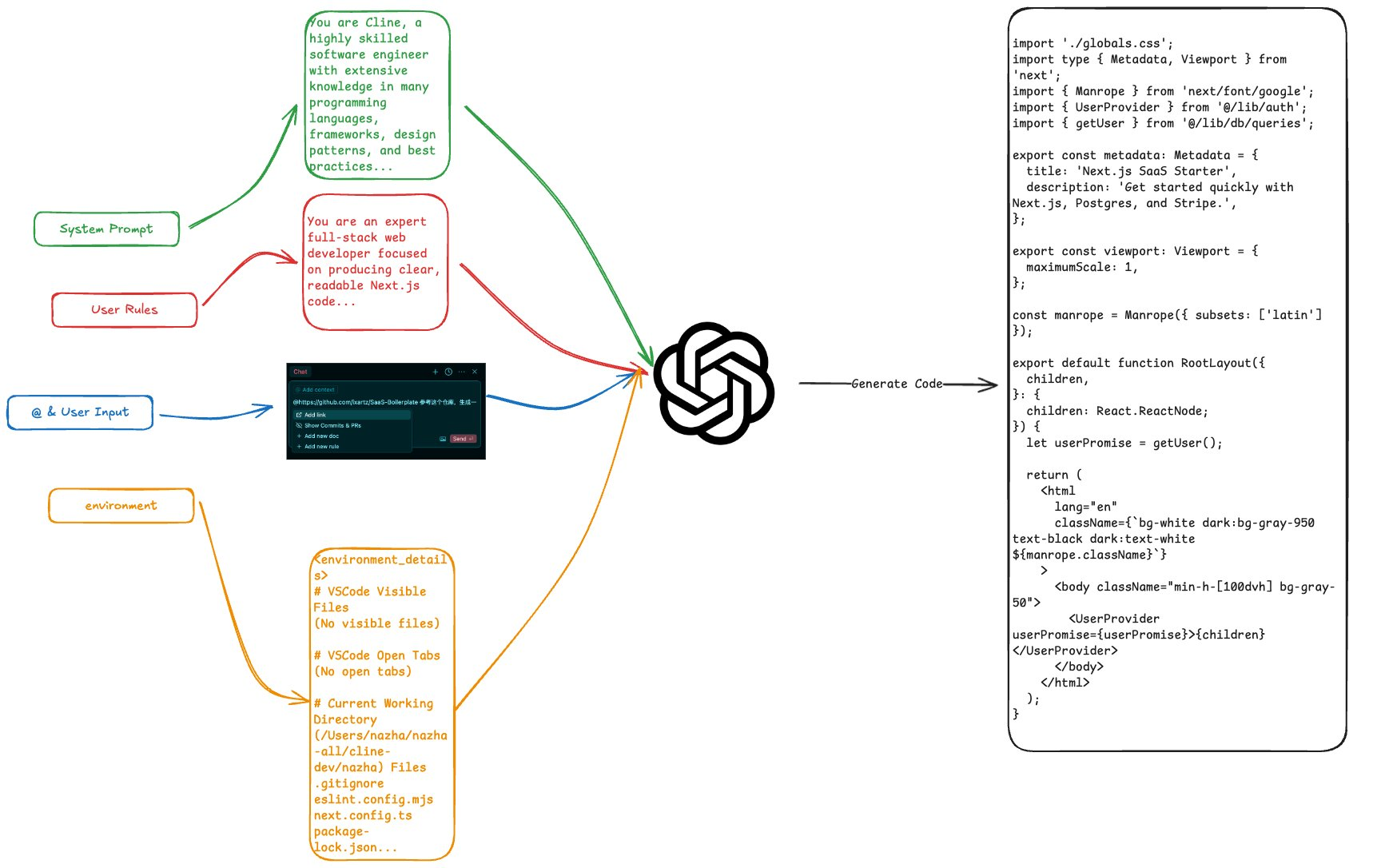
レイトスコアを用いたフラグメント選択のフローチャート
この図は要約選択アルゴリズムを示すもので、一次元畳み込み(Conv1D)のように動作する。このプロセスでは、まず長い文書を一定の長さのチャンクに分割し、次にレイトパーティショニングを有効にした jina-embeddings-v3 これらのテキストブロックをベクトル化する。各ブロックと質問の間の類似性スコアを計算した後、スライディングウィンドウがこれらの類似性スコアの上を移動し、最も高い平均を持つウィンドウを見つける。
これが概略的なコードだ。「1次元畳み込み」に似た後期分割と平均プーリングを使って、問題に最も関連する箇所を選び出す。
function cherryPick(question, longContext, options) {
if (longContext.length < options.snippetLength * options.numSnippets)
return longContext;
const chunks = splitIntoChunks(longContext, options.chunkSize);
const chunkEmbeddings = getEmbeddings(chunks, "retrieval.passage");
const questionEmbedding = getEmbeddings([question], "retrieval.query")[0];
const similarities = chunkEmbeddings.map(embed =>
cosineSimilarity(questionEmbedding, embed));
const chunksPerSnippet = Math.ceil(options.snippetLength / options.chunkSize);
const snippets = [];
const similaritiesCopy = [...similarities];
for (let i = 0; i < options.numSnippets; i++) {
let bestStartIndex = 0;
let bestScore = -Infinity;
for (let j = 0; j <= similarities.length - chunksPerSnippet; j++) {
const windowScores = similaritiesCopy.slice(j, j + chunksPerSnippet);
const windowScore = average(windowScores);
if (windowScore > bestScore) {
bestScore = windowScore;
bestStartIndex = j;
}
}
const startIndex = bestStartIndex * options.chunkSize;
const endIndex = Math.min(startIndex + options.snippetLength, longContext.length);
snippets.push(longContext.substring(startIndex, endIndex));
for (let k = bestStartIndex; k < bestStartIndex + chunksPerSnippet; k++)
similaritiesCopy[k] = -Infinity;
}
return snippets.join("\n\n");
}
Jina Embeddings APIを呼び出す際には、忘れずに task 検索に設定し late_chunking属truncate また、以下のように設定する:
await axios.post(
'https://api.jina.ai/v1/embeddings',
{
model: "jina-embeddings-v3",
task: "retrieval.passage",
late_chunking: true,
input: chunks,
truncate: true
},
{ headers });
問題をベクトル化する場合は、次のように書くことを忘れないこと。 task 換える retrieval.queryそれから電源を切る。 late_chunking.
完全な実装コードはGitHubにある:https://github.com/jina-ai/node-DeepResearch/blob/main/src/tools/jina-latechunk.ts
次を読むためのURLソート
DeepSearchの長いプロセスでは、検索エンジンの結果ページ(SERP)から大量のURLを収集することがあります。ウェブページを開くたびに、その過程で多くの新しいリンクを見つけることができ、強調を外した後でも、数百のURLを簡単に見つけることができます。同様に、LLMにこれらすべてのURLを詰め込んでもうまくいくはずはなく、貴重な文脈の長さの無駄遣いであり、さらに悪いことに、LLMは基本的にただやみくもに選んでいることがわかった。そこで私たちは、LLMが答えを含む可能性が最も高いURLを選び出すよう導く方法を見つけなければならなかった。
curl https://r.jina.ai/https://example.com \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
-H "X-Retain-Images: none" \
-H "X-Md-Link-Style: discarded" \
-H "X-Timeout: 20" \
-H "X-With-Links-Summary: all"
これは、DeepSearchでページをクロールするためにJina Readerを設定する最良の方法です。ページ上のすべてのリンクを抽出し、リンクフィールドに入れ、コンテンツフィールドから削除します。
これは "in-context PageRank "と考えることができるが、1つのセッションで何百ものURLをスコアリングしている点は異なる。
最終更新時刻、ドメイン名の出現頻度、ページパスの構造、そして最も重要な質問との意味的関連性など、いくつかの要素を考慮して複合スコアを算出します。しかし、私たちが利用できるのは、URLをクリックする前の情報だけです。

1.周波数信号URLが異なるソースに何度も表示される場合、そのURLはより重視される。また、あるドメイン名が検索結果に頻繁に表示される場合、そのドメインからのURLはさらに加点される。これは、一般的に、人気のあるドメインは、より権威のあるコンテンツを含む傾向があるためです。
2.路線構成URLのパス構造を分析し、どのようなコンテンツが集まっているかを判断します。複数のURLがすべて同じパス階層に属していれば、スコアは高くなりますが、パスが深くなればなるほど、スコアボーナスは徐々に減っていきます。
3.意味的関連性を使用する。 jina-reranker-v2-base-multilingual これは、質問の意味的関連性と各URLのテキスト情報(タイトルや抄録など)を評価するためのもので、典型的な並べ替え問題である。各URLのテキスト情報はいくつかの場所から得られる:
Search Engine Results Page (SERP) API タイトルと要約を返す (https://s.jina.ai/ このインターフェイスは、'X-Respond-With': 'no-content'で、タイトルと要約だけを返し、特定のコンテンツは返しません)。 ページ上のURLのアンカーテキスト(https://r.jina.ai のインターフェイスを使い、'X-With-Links-Summary': 'all'を設定すると、ページ内のすべてのリンクの要約情報、つまりアンカーテキストが返されます)。
4.最終更新日DeepSearchのクエリの中には、高い適時性が要求されるものがあるため、一般的には、新しいURLほど高い値が付けられます。しかし、Googleの大規模なインデックス作成能力がなければ、ウェブページの最終更新時刻を正確に判断することは困難です。そこで、以下のシグナルを組み合わせてタイムスタンプと信頼スコアを与え、必要なときに最新のコンテンツを優先的に表示できるようにしています:
SERP APIが提供するフィルタリング機能(例えば、s.jina.aiのtbsパラメータは時間によるフィルタリングを可能にする)。 HTTPヘッダー情報の分析(Last-ModifiedやETagフィールドなど)。 メタデータの抽出(メタタグやSchema.orgのタイムスタンプなど)。 コンテンツパターン認識(HTMLに表示される日付を認識)。 特定のCMSプラットフォーム(WordPress、Drupal、Ghostなど)の指標
5.制限されたコンテンツソーシャルメディアプラットフォームの中には、アクセスが制限されていたり、有料であったりするコンテンツがあります。ログインせずにこのコンテンツに合法的にアクセスする方法はありません。したがって、私たちは積極的にこれらの問題のあるURLやドメインのブラックリストを維持し、ランキングを下げ、このアクセスできないコンテンツにコンピューティングリソースを浪費しないようにしています。
6.ドメイン名の多様性上位のURLがすべて同じドメインからのものであることがあり、DeepSearchが「局所最適」に陥り、最終結果の品質に影響を与えることがあります。前述したように、上位のURLはすべてStackOverflowからのものであるため、結果の多様性を高めるために、「exploit-and-exploit」戦略を使用することができます: 各ドメインから上位K個のURLを選択します。
URLソートの完全な実装コードはGithubにあります: https://github.com/jina-ai/node-DeepResearch/blob/main/src/utils/url-tools.ts#L192
<action-visit>
- Crawl and read full content from URLs, you can get the fulltext, last updated datetime etc of any URL.
- Must check URLs mentioned in <question> if any
- Choose and visit relevant URLs below for more knowledge. higher weight suggests more relevant:
<url-list>
+ weight: 0.20 "https://huggingface.co/docs/datasets/en/loading": "Load - Hugging FaceThis saves time because instead of waiting for the Dataset builder download to time out, Datasets will look directly in the cache. Set the environment ...Some datasets may have more than one version based on Git tags, branches, or commits. Use the revision parameter to specify the dataset version you want to load ..."
+ weight: 0.20 "https://huggingface.co/docs/datasets/en/index": "Datasets - Hugging Face🤗 Datasets is a library for easily accessing and sharing datasets for Audio, Computer Vision, and Natural Language Processing (NLP) tasks. Load a dataset in a ..."
+ weight: 0.17 "https://github.com/huggingface/datasets/issues/7175": "[FSTimeoutError] load_dataset · Issue #7175 · huggingface/datasetsWhen using load_dataset to load HuggingFaceM4/VQAv2, I am getting FSTimeoutError. Error TimeoutError: The above exception was the direct cause of the following ..."
+ weight: 0.15 "https://github.com/huggingface/datasets/issues/6465": "`load_dataset` uses out-of-date cache instead of re-downloading a ...When a dataset is updated on the hub, using load_dataset will load the locally cached dataset instead of re-downloading the updated dataset."
+ weight: 0.12 "https://stackoverflow.com/questions/76923802/hugging-face-http-request-on-data-from-parquet-format-when-the-only-way-to-get-i": "Hugging face HTTP request on data from parquet format when the ...I've had to get the data from their data viewer using the parquet option. But when I try to run it, there is some sort of HTTP error. I've tried downloading ..."
</url-list>
</action-visit>
概要
2025年2月2日にジーナのDeepSearchが利用可能になって以来、品質を劇的に向上させることができる2つのエンジニアリングの詳細が発見された。興味深いことに、どちらの詳細も、多言語EmbeddingとRerankerモデルを「in-context window」方式で利用している。これらのモデルが通常必要とする、事前に計算された膨大なインデックスに比べれば大したことはない。
このことは、検索技術の未来が二極化した方向に進むことを予感させるかもしれない。この傾向を理解するために、カーネマンの二重過程論を借りることができる:
早く考えろ。 高速思考 (grep、BM25、SQL): 最小限の計算で高速なルールベースのパターンマッチング。 ゆっくり考える スローシンク (LLM):深い文脈理解を伴う包括的な推論を行うが、計算量が多い。 ミディアムバンド ミッドシンク (エンベッディング、リランカー他、リコールモデル):ある程度の意味理解を持ち、単純なパターンマッチングよりは良いが、LLMよりははるかに推論が少ない。
ひとつの可能性がある:二層構造の検索アーキテクチャがますます普及している軽量で効率的なSQL/BM25が検索の入力を担当し、その結果を直接LLMに送り、出力を検索する。中間層モデルの残存価値は、特定のコンテキスト・ウィンドウ内のタスク(例えば、フィルタリング、重複排除、ソートなど)にシフトされる。このようなシナリオでは、LLMで完全な推論を行うのは非効率的である。
しかし、とにかくだ。キークリップの選択 歌で応える URLソート それでもなお、DeepSearch/DeepResearch システムの品質に直接影響する基本的な側面は変わりません。私たちの調査結果が、皆様のシステムの改善に役立つことを願っています。
クエリーの拡大も、クオリティを決める重要な要素だ。野菜だ。単純なプロンプトベースの書き換えから、小さなモデル、推論ベースのアプローチまで、様々なアプローチを積極的に評価しています。今後の研究成果にご期待ください!
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません