百川インテリジェンス、百川-Omni-1.5全方位大型モデルを発表、いくつかの測定でGPT-4o Miniを上回る

年末にかけて、国内の大型モデル分野に再び朗報が飛び込んできた。BCinksインテリジェンスは最近、以下のような大型モデル製品を発表した。全シーン深層推論モデルBaichuan-M1-プレビュー歌で応える医療強化オープンソースモデル Baichuan-M1-14B続いてフルモードモデル Baichuan-Omni-1.5.
Baichuan-Omni-1.5は "Big Model Generalist "と呼ばれ、マルチモーダル融合技術における国産ビッグモデルの著しい進歩を示している。テキスト、画像、音声、ビデオなどのマルチモーダルな情報を提供する。テキストとオーディオバイモーダルなコンテンツ生成。
同時に、Baichuan Intelligenceもオープンソース化した。オープンMMメディカル歌で応えるOpenAudioBench2つの高品質評価データセットは、国内オールモーダルモデル技術エコシステムの繁栄を促進することを目的としている。公開された総合評価結果によると、百川-オムニ-1.5は多くのマルチモーダル能力において総合性能はGPT-4o Miniを上回る特に医療分野では、BCinks Intelligenceがますます深みを増している。医療画像審査のスコアは重要なリードこれは、BCinksインテリジェンスが大型モデル分野のリーダーとしての強い強さと決意を十分に示しています。 これは、百川インテリジェンスが大型モデル分野の国内リーダーとして、技術革新と産業応用の着地における強い強さと確固たる決意を十分に示している。
モデル体重の住所
バイチュアン-オミニ-1.5: https://huggingface.co/baichuan-inc/Baichuan-Omni-1d5 https://modelers.cn/models/Baichuan/Baichuan-Omni-1d5
百川-オムニ-1.5-ベース: https://huggingface.co/baichuan-inc/Baichuan-Omni-1d5-Base https://modelers.cn/models/Baichuan/Baichuan-オムニ-1d5-ベース
GitHubアドレス:https://github.com/baichuan-inc/Baichuan-Omni-1.5
テクニカルレポート:https://github.com/baichuan-inc/Baichuan-Omni-1.5/blob/main/baichuan_omni_1_5.pdf
01 . マルチモーダル機能における包括的なブレークスルー:テキスト、グラフィック、オーディオ、ビデオ処理評価における卓越した性能
Baichuan-Omni-1.5の性能のハイライトは、次のように要約できる。包括的な能力と高いパフォーマンス". このモデルの最大の特徴は包括的に具体的には、テキスト、画像、動画、音声などのマルチモーダルコンテンツを理解するだけでなく、テキストと音声のバイモーダル生成もサポートしている。
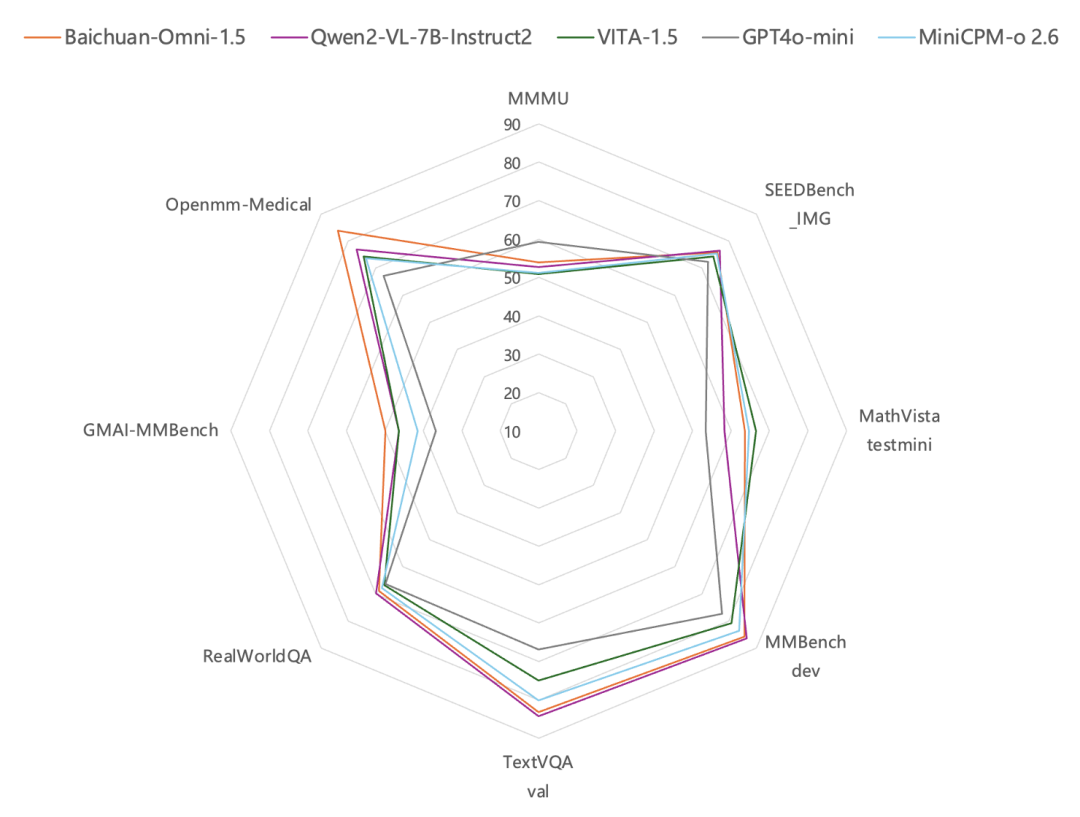
MMBench-dev、TextVQA valなどの一般的な画像評価ベンチマークのテスト結果によると、画像理解の面では、白川-オムニ-1.5の性能は以下の通りである。GPT-4oミニより良い.特に興味深いのは、その一般的な能力に加えて、百全インテリジェンスのオール・モーダル・モデルがヘルスケア分野で特に強いという事実である。それは医療画像レビュー・データセット GMAI-MBenchとOpenmm-Medicalのレビューによれば、Baichuan-Omni-1.5の医用画像理解における能力は以下の通りである。GPT-4oミニを大幅に上回る性能.
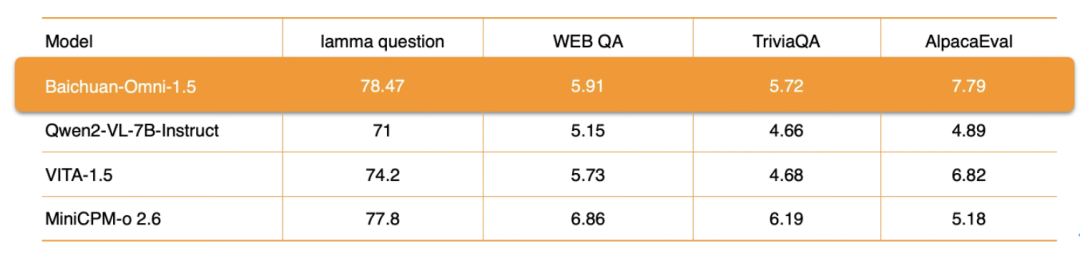
オーディオ処理に関しては、Baichuan-Omni-1.5は、以下の機能をサポートしているだけでなく、以下の機能もサポートしています。多言語対話また、エンド・ツー・エンドのオーディオ合成機能にも依存しており、次のような機能を統合しています。 ASR(自動音声認識) 歌で応える TTS(音声合成) 関数の実装をサポートしている。さらに、このモデルはオーディオとビデオのリアルタイム・インタラクション.具体的な性能評価指標については、lamma questionやAlpacaEvalなどのデータセットにおけるBaichuan-Omni-1.5の総合的な性能は、以下のとおりです。を大きく上回る Qwen2-VL-2B-Instruct、VITA-1.5、MiniCPM-o 2.6が類似モデルである。
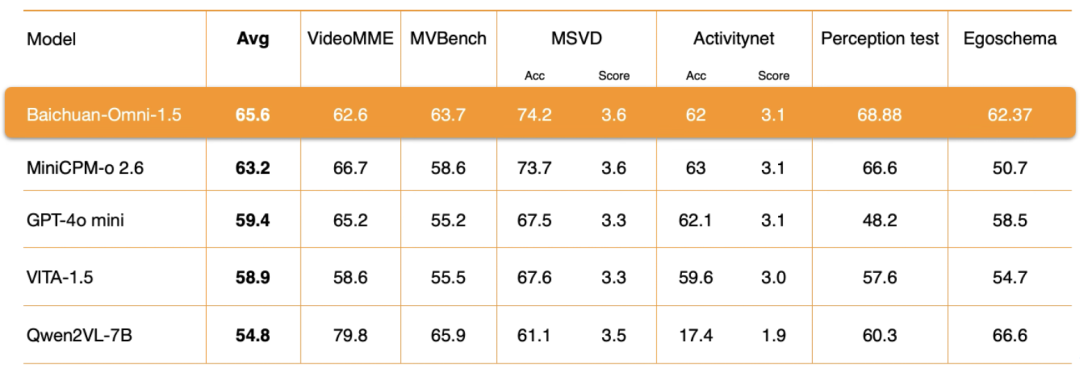
ビデオ理解Baichuan-Omni-1.5のレベルでは、Baichuan Intelligenceは、エンコーダアーキテクチャ、トレーニングデータの品質、トレーニング方法の戦略など、いくつかの重要な側面において徹底的な最適化を実施しました。評価結果は、そのビデオ理解総合性能もGPT-4o-miniを大きく上回っている。.
まとめると、Baichuan-Omni-1.5は、全体としてGPT4o-miniを汎用性の面で上回るだけでなく、より重要なことは、GPT4o-miniを実現したことである。完全なモード理解と生成の統一これは、より一般化されたAIシステムを構築するための基礎を築くものである。
マルチモーダルモデリング研究をさらに進めるため、Baichuan Intelligenceは2つの専門家によるレビューデータセットをオープンソース化した:OpenMM-MedicalとOpenAudioBench. その中で オープンMMメディカル データセット医療用のマルチモーダルなタスクにおけるモデルの性能を評価するように設計されている。ACRIMA(眼底画像)、BioMediTech(顕微鏡画像)、CoronaHack(X線画像)など、一般に公開されている42の医療画像データセットのデータを統合し、合計88,996枚の画像を収録している。
ダウンロードアドレス
https://huggingface.co/datasets/baichuan-inc/OpenMM_Medical
OpenAudioBench である。モデルの音声理解スキルを効率的に評価するための包括的な評価プラットフォーム音声のエンドツーエンド理解のための5つのサブ評価セットが含まれており、そのうちの4つは公開評価データセット(Llama Question、WEB QA、TriviaQA、AlpacaEval)から派生したもので、残りの1つはBaichuan Intelligenceによる自作の音声論理推論評価セットで、2,701個のデータが含まれている。
ダウンロードアドレス
https://huggingface.co/datasets/baichuan-inc/OpenAudioBench
BCinks Intelligenceは、国内のオープンソースエコシステムの構築と繁栄に積極的に参加し、推進しています。 オープンソースの評価データセットは、研究者や開発者に統一された標準化された評価ツールを提供し、異なるマルチモーダルモデルの性能を客観的かつ公正に比較分析するのに役立ち、新世代の言語理解アルゴリズムとモデルアーキテクチャの革新的な開発を促進します。
02 . 全方位的なテクノロジーの最適化:データ、アーキテクチャ、プロセスの相乗効果で、マルチモーダルモデルのボトルネックを打破する
初期のユニモーダルモデルの開発からマルチモーダル融合モデル、そして今日のオールモーダルモデルへと、この技術進化の旅は、様々な産業におけるAI技術の地上応用のためのより広い空間を広げてきた。しかし、AI技術がさらに発展するにつれてマルチモーダルモデルにおける理解と生成の統一性をいかに効果的に達成するかは、現在のマルチモーダル分野の研究において重要なホットスポットであり、技術的な困難となっている。.
一方では、理解と生成の統一は、自然な人間の相互作用をシミュレートし、より自然で効率的な人間とコンピュータのコミュニケーションを実現するための鍵であり、一般的な人工知能(AGI)への重要なリンクでもあります。オールモーダルモデル学習が直面する最大の課題の一つである。
Baichuan-Omni-1.5のリリースは、Baichuan Intelligenceが上記の技術的問題を解決し、効果的な技術的道筋を探る上で大きな進歩を遂げたことを示している。オムニモーダルモデルのトレーニングにおける「知的劣化」という共通の問題を克服するため、百全知能の研究チームは、モデル構造の設計、トレーニング戦略の最適化、トレーニングデータの構築に至る全プロセスの綿密な最適化を実施し、最終的に理解と生成の効果的な統一を実現した。
初モデリング一方、Baichuan-Omni-1.5の入力層は様々なモーダルデータをサポートし、対応するエンコーダー/トーケナイザーを通して処理のために大規模言語モデルに供給される。出力層では、モデルはテキストオーディオインターリーブ出力設計を採用し、テキストトケナイザーとオーディオデコーダーを通して、テキストとオーディオコンテンツの両方を同時に生成することができる。出力レイヤーでは、モデルはテキスト-オーディオ・インターリーブ出力設計を採用し、テキスト・トークナイザーとオーディオ・デコーダーを通じて、テキストとオーディオ・モダリティの両方を同時に生成することができる。 オーディオ・トークナイザーはOpenAIのオープンソース音声認識・翻訳モデルに基づいています。 ウィスパー このモデルは段階的に学習され、高度な意味抽出と忠実度の高い音声再構成を提供する。モデルが異なる解像度の画像を扱えるようにするため、Baichuan-Omni-1.5はNaViTモデルを導入し、最大4K解像度までの画像入力と複数画像の推論をサポートすることで、モデルが画像情報を完全に取り込み、画像内容を正確に理解できるようにしている。
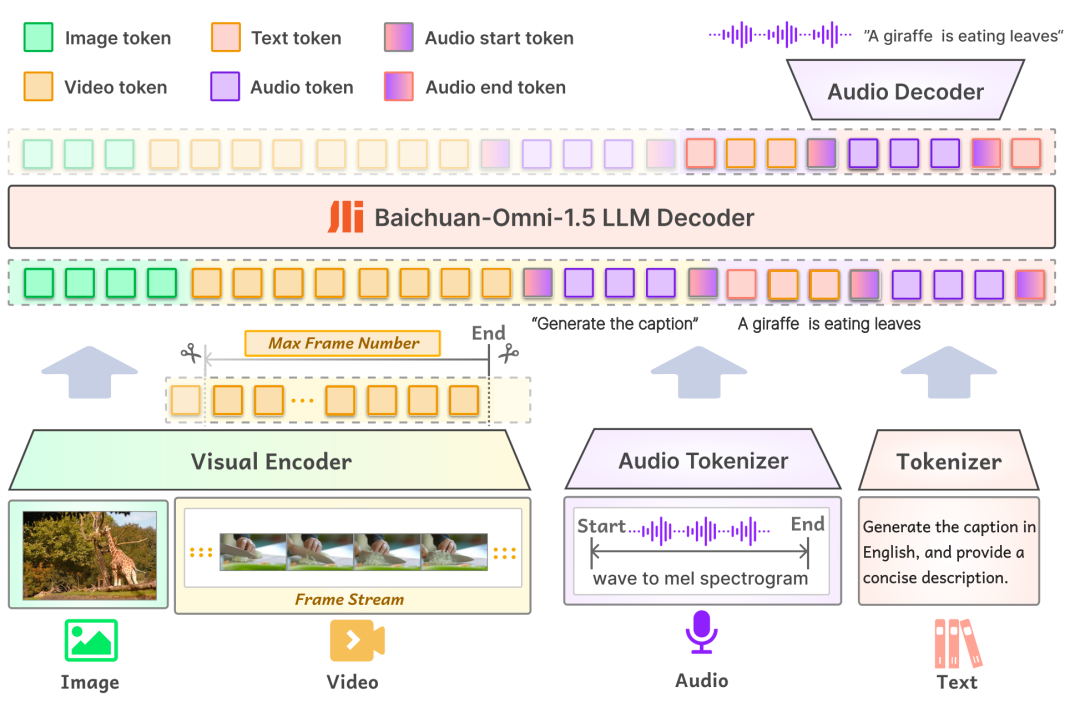
第二にデータレベルBCIは、3億4,000万件の高品質な画像/動画/テキストデータと、100万時間近い音声データを含む巨大なデータベースを構築しており、その中から1,700万件のフルモーダルデータが、モデルのSFT(教師あり微調整)フェーズ用に選択されている。 従来のモデルのデータ構成とは異なり、オムニモーダルモデルの学習には、大規模なデータサイズだけでなく、多様なデータタイプとインターモダリティが必要である。 現実世界では、情報は通常複数のモダリティの融合として提示され、異なるモダリティのデータには相補的な情報が含まれている。マルチモーダルデータの効果的な融合は、モデルのより一般的なパターンや法則の学習に役立ち、モデルの一般化能力を向上させる。 これは、高性能なオールモーダルモデルを構築する上で重要な要素の一つである。
モデルのクロスモーダル理解能力を向上させるため、百川知能は高品質なビジュアル・オーディオ・テキスト・インターリーブデータを構築し、1,600万個のグラフィックデータ、30万個のプレーンテキストデータ、40万個のオーディオデータ、および上記のクロスモーダルデータを使用して、アライメントによるモデルの学習を行った。 さらに、ASR、TTS、音色切り替え、音声エンドツーエンドQ&Aなど、多様な音声タスクを同時に実行できるようにするため、研究チームは、アラインメントされたデータの中に、これらのタスクに特化したデータサンプルも構築した。
3つ目の重要な技術ポイントはトレーニングプロセスモデルの最適設計は、高品質なデータがモデルのパフォーマンスを効果的に向上させるためのコア・リンクです。BCinks Intelligenceでは、モデルの効果を総合的に向上させるため、事前学習とSFTの両フェーズで多段階学習スキームを採用しています。 第一段階はグラフィックデータのトレーニング、第二段階は事前トレーニングのためのオーディオデータの追加、第三段階はトレーニングのためのビデオデータの導入、そして最後の段階はマルチモーダルアライメントの段階です。
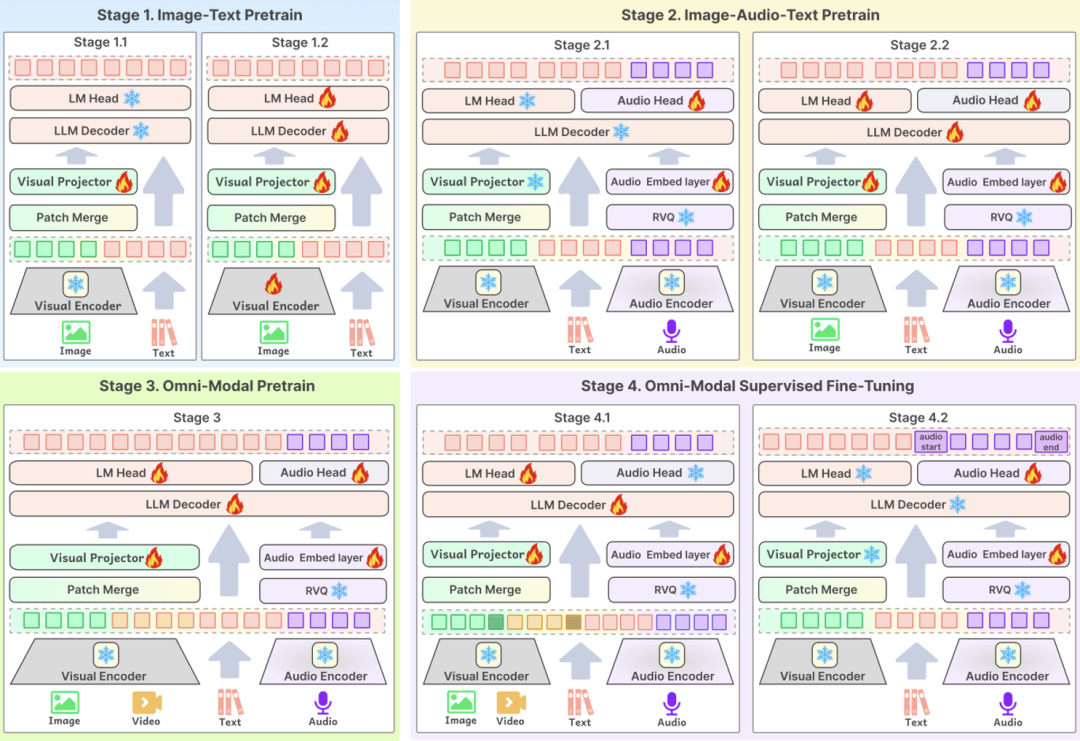
以上のような全面的な技術最適化に基づき、Baichuan-Omni-1.5の総合的な能力は、従来のシングルモーダル大規模言語モデルやマルチモーダルモデルと比較して大幅に向上している。Baichuan-Omni-1.5のリリースは、Baichuanインテリジェンスの技術研究開発におけるもう一つの重要なマイルストーンであるだけでなく、AIの開発中心がモデルの基本的な能力の向上から実用化へと加速していることを意味する。
これまでの大型モデルの能力強化は、主に言語理解や画像認識などの基本的な能力に焦点を当てていたが、Baichuan-Omni-1.5の強力なマルチモーダル融合能力は、実世界の応用シナリオとの緊密な統合を実現する技術に役立つ。 言語、視覚、音声などのマルチモーダル情報処理におけるモデルの包括的な能力を強化することで、Baichuan-Omni-1.5は、より複雑で多様な実用的応用タスクに効果的に対応することができる。例えば、医療業界では、オムニモーダルモデルの強力な理解力と生成能力を利用して、医師の疾病診断を支援し、診断の精度と効率を向上させることができ、医療分野におけるAI技術の深い応用を促進するための重要な探索価値となる。 今後、白川-オムニ-1.5のリリースは、AGI時代の医療・ヘルスケア分野におけるAI技術の応用の始まりとなる可能性があり、近い将来、AIが医療やその他の分野でより大きな役割を果たし、私たちの生活を大きく変えることを期待する理由がある。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません