
ディープシーク、v3モデルの初のオープンソース版をリリース。
DeepSeek-V3は、総パラメータ6710億、各トークンに対して37億のパラメータを持つ強力なMoE(Mixture-of-Experts)言語モデルです。このモデルは、革新的なマルチヘッドポテンシャルアテンション(Mu...
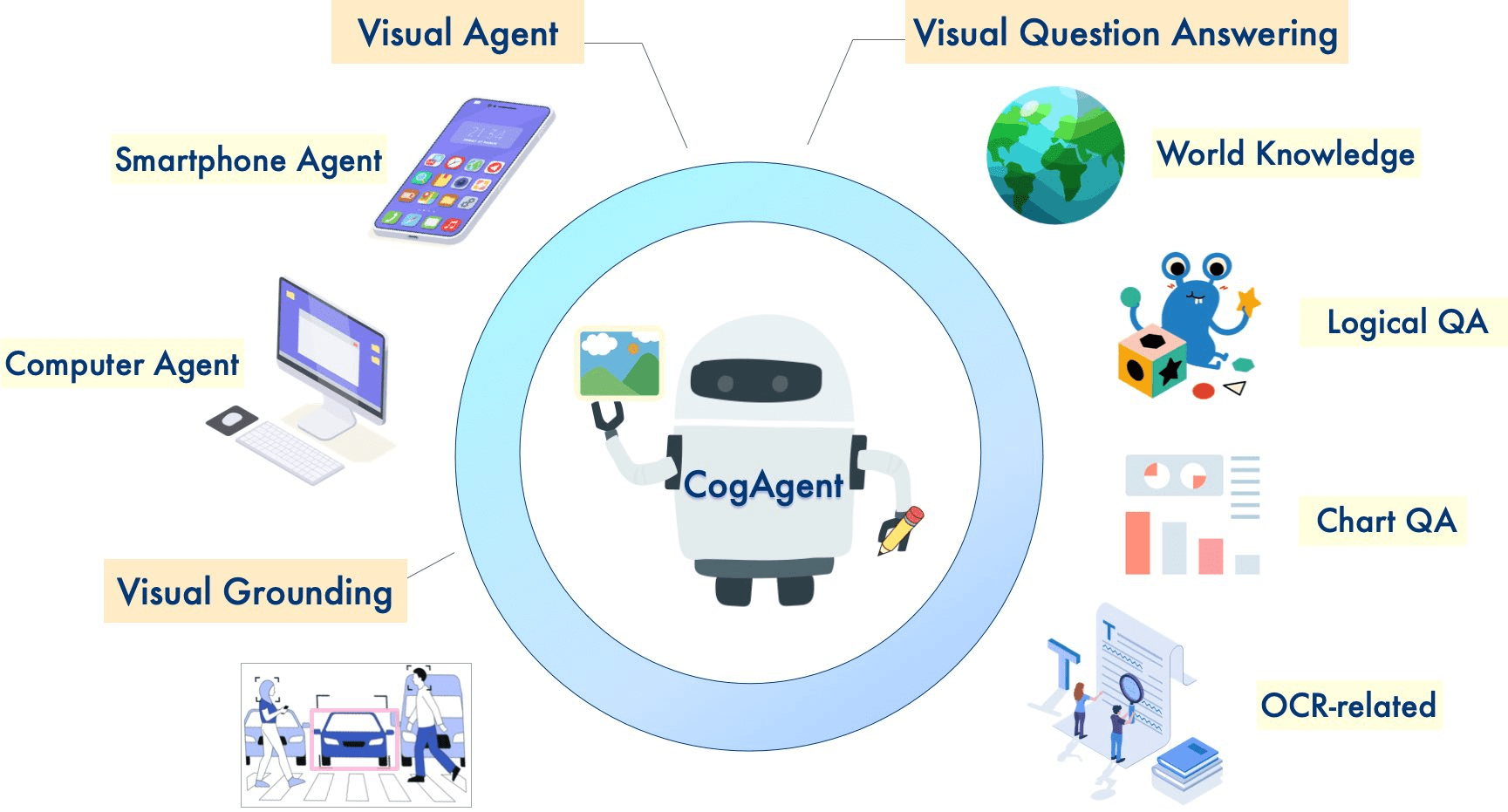
CogAgent: Smart Spectrumのグラフィカル・インターフェース自動化のためのオープンソースのインテリジェント視覚言語モデル
包括的な紹介 CogAgentは清華大学データマイニング研究グループ(THUDM)によって開発されたオープンソースの視覚言語モデルであり、プラットフォーム間のグラフィカルユーザインタフェース(GUI)操作の自動化を目的としている。このモデルはCogVLM(GLM-4V-9B)をベースにしており、中国語と英語の二ヶ国語をサポートしている。
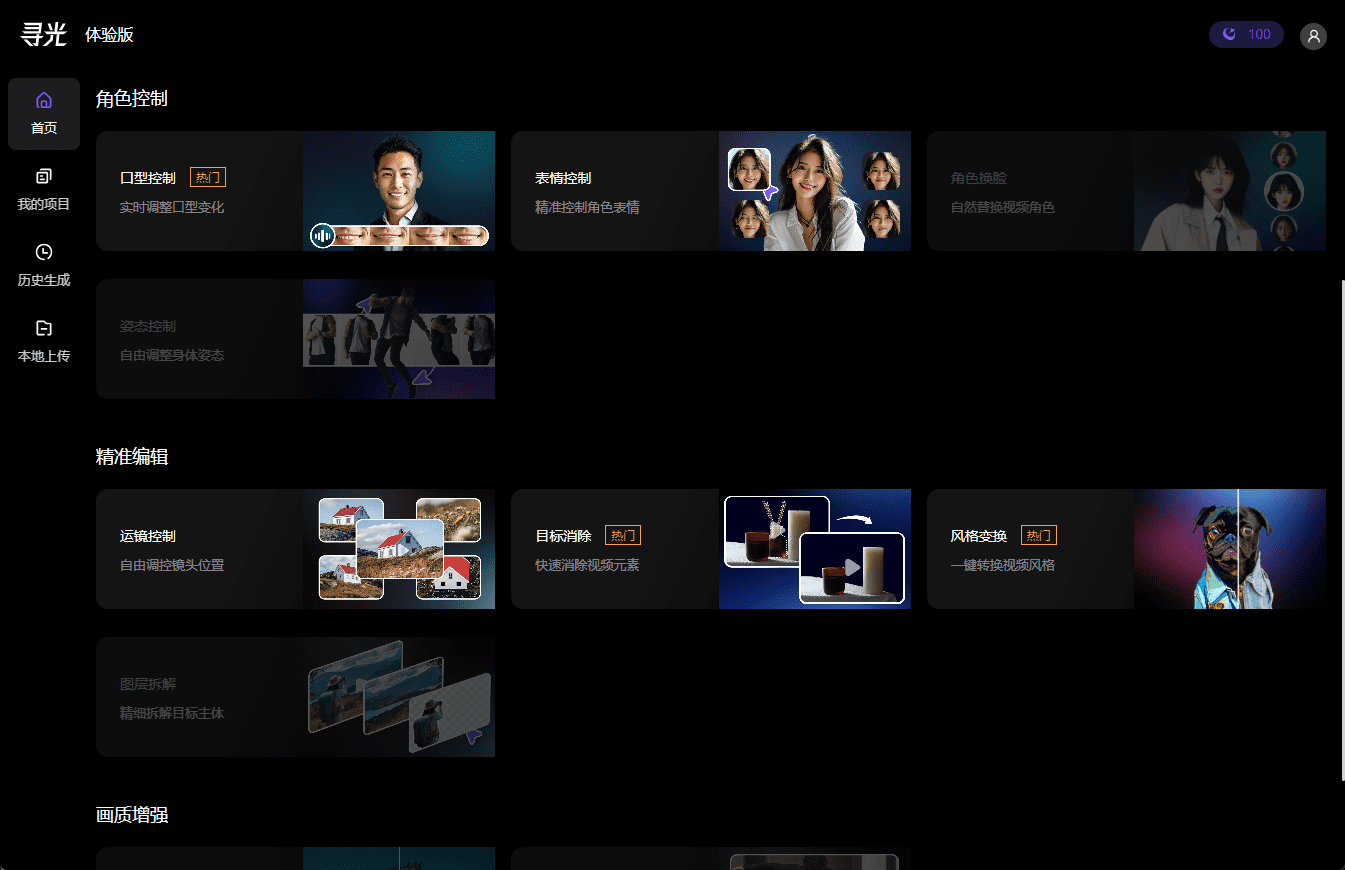
ダルマ・インスティテュート「サーチライト」ビデオ制作プラットフォーム フルレビュー
本日未明、「サーチライト」の社内テスト申請が承認されたとの連絡を受けたので、寝る前に簡単なレビューをアップする。 このプラットフォームはダーマ・インスティテュートの「ビジュアル技術能力アプリケーション・プラットフォーム」と位置づけられており、現在は(ローンチ時に比べて)アプリケーションの数が少なく、徐々にビジュアル・アプリケーションを開放していくことを楽しみにしている。 光の検索は2つのアドレスに分かれている:https...
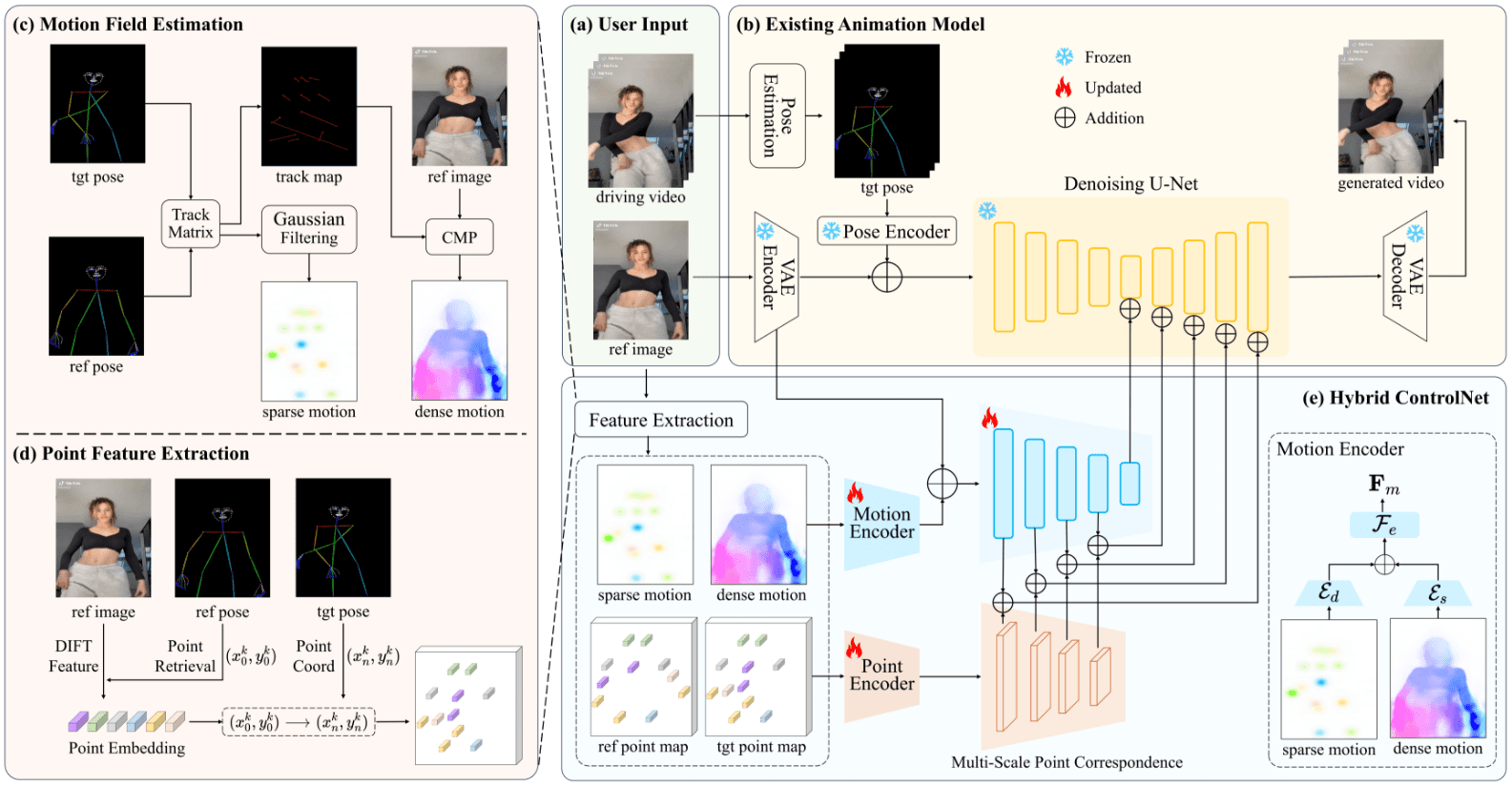
ディスポーズ:人間の姿勢を精密に制御してビデオを生成し、踊る女性を作り出す
一般的な紹介 DisPoseは、制御されたキャラクター画像アニメーション生成に焦点を当てた革新的なオープンソースの人工知能プロジェクトです。研究者チームによって開発され、GitHubでオープンソース化されたこのプロジェクトは、高度なディープラーニング技術を用いて、骨格のポーズ情報を分解することで正確なキャラクターアニメーションの制御を実現しています。

Smolagents:AIインテリジェンスの迅速な開発とインテリジェンスの軽量化のためのオープンソースプロジェクト
包括的な紹介 Smolagentsは、HuggingFaceによって開発された軽量インテリジェントエージェントライブラリで、AIエージェントシステムの開発プロセスを簡素化することに重点を置いています。このプロジェクトは、約1000行のコアコードしかないシンプルな設計思想で知られていますが、強力な機能統合機能を提供しています。このライブラリの最も ...

文書をMarkdown形式の文書に視覚的に抽出するための複合キュー・ワード・コマンド
このコマンドはVision Parseプロジェクトから来たもので、2つのステップでマークダウン文書を抽出します。 画像解析プロンプト(img_analysis.prompt):この画像を解析し、...

ナプキンAI中国語スタートガイド
Napkin AIでビジュアルコンテンツを作成するには?(アカウント作成、ビジュアル生成、pdfや画像ファイルへのエクスポート...) テキストを簡単に美しいビジュアルに変換できるツール、Napkin AIへようこそ。このガイドでは...

Vision Parse: 視覚言語モデルを用いたPDFドキュメントのMarkdownフォーマットへのインテリジェント変換
包括的な紹介 Vision Parseは画期的な文書処理ツールで、最先端の視覚言語モデル(Vision Language Models)技術と、PDF文書を高品質のMarkdown形式にインテリジェントに変換する機能を巧みに組み合わせています...
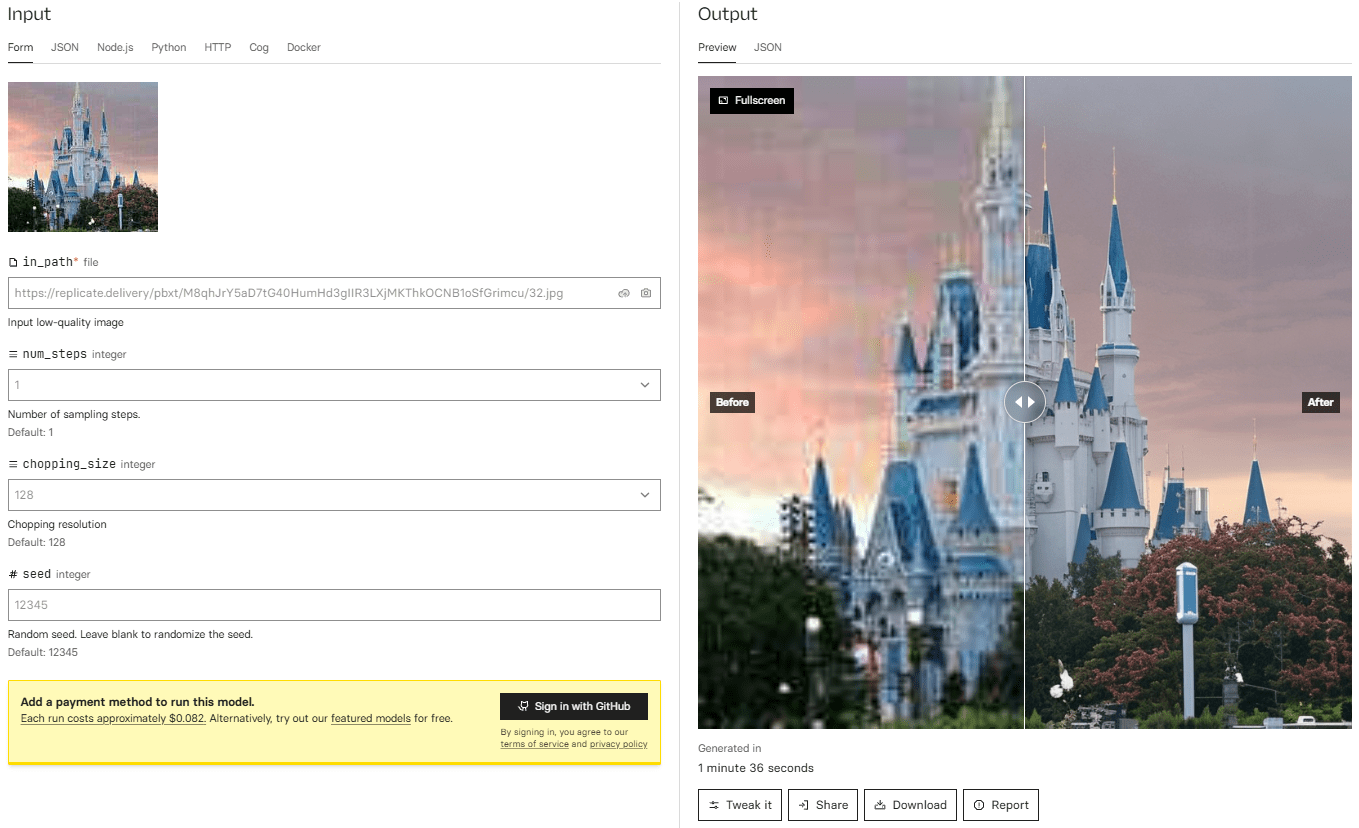
InvSR: 画像解像度の質を向上させるオープンソース画像超解像プロジェクト
一般的な紹介 InvSRは、低解像度画像を高品質な高解像度画像に変換できる拡散インバージョン技術に基づいた革新的なオープンソースの画像超解像プロジェクトです。このプロジェクトは、事前に訓練された大規模拡散モデルに埋め込まれた豊富な画像事前知識を利用し、柔軟なサンプリングメカニズムを通じて、...
無限大:無制限の高解像度画像生成のためのビット単位の自己回帰モデリング
概要 Infinityは、FoundationVisionチームによって開発された画期的な高解像度画像生成フレームワークです。このプロジェクトは、革新的なビットレベルの視覚的自己回帰モデリング・アプローチによって、従来の画像生成モデルの限界を打ち破ります。