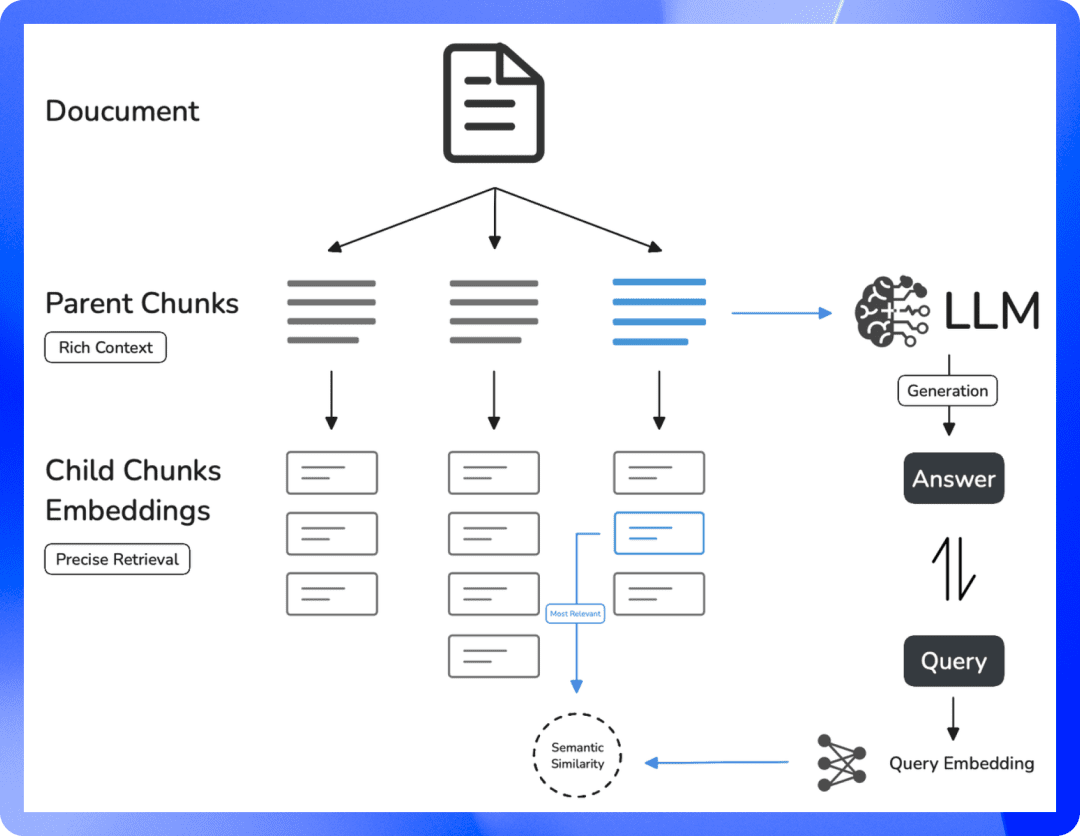
AIリサーチ・アシスタント・コンペティション:主流5ツールの徹底レビューと選考ガイド

AIリサーチ・アシスタントの台頭:宿題を手伝ってくれるのは誰?
情報化時代における研究とは、しばしば膨大な量のデータを踏破することを意味する。かつて研究者は、重要なコンテンツを次のような人々に提供する前に、手作業で情報を検索し、ふるいにかけ、整理する必要があった。 チャットGPT そのような大きな言語モデルが分析される。しかし、OpenAIのDeep Research機能の登場により、状況は変わり始めている。ユーザーが質問するだけで、AIが自律的にウェブを検索し、データを分析し、引用を含むレポートを生成するのだ。これは多くの場合、OpenAIのo3のような高度なビッグ・ランゲージ・モデルによって推進され、事前に訓練された知識を利用するだけでなく、積極的に最新の情報を取得し、多段階の推論を実行する。
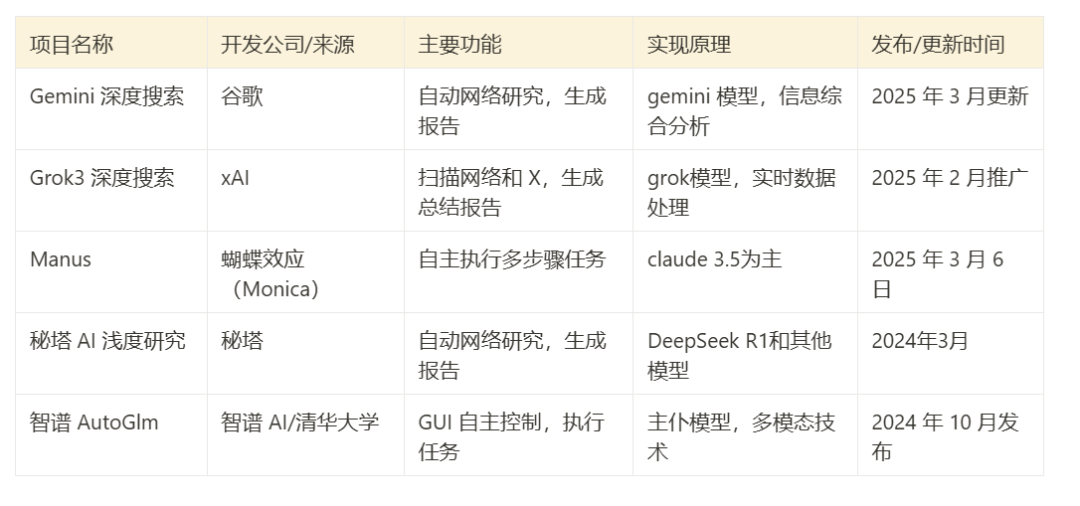
2023年3月以降、複数の企業が独自の自動調査ツールやAIエージェント(Agent)を発表しており、これらはしばしば「AI検索アシスタント」や「ディープリサーチ」ツールと呼ばれている。これらのツールの核となるコンセプトは似ている。強力なAIモデリング機能をウェブ検索と組み合わせることで、調査タスクを自律的に実行し、結果を提供するというものだ。

この記事では、市場で高く評価されているこれらの製品のいくつかに注目し、実際のテストを通じて、それぞれの性能の違い、能力の限界、最適なシナリオを探ることを目的とする。この比較に使用したツールは以下の通り:
- ジェミニ・ディープ・サーチグーグルの ジェミニ 情報を総合し分析する能力を重視した一連のモデル。
- Grok 3 ディープ・サーチxAIの活用 グロック 3 独立したタスクを実行するように設計されたモデルで、おそらくリアルタイム情報に重点を置いている。
- マヌス様々なAIモデルをサポートするシステム(例. アンソロピック な クロード やAli's Qwen)のプラットフォームは、マルチステップタスクを実行することで知られている。
- 三田AIシャローリサーチR1モデルとロジカルフレームワークの分解を組み合わせ、独自のモデルでウェブ検索と統合を行う。
- ZhipuオートGLMZhipu AIの大規模言語モデルをベースに、GUI(グラフィカル・ユーザー・インターフェース)を通じてユーザーの操作をシミュレートすることで、デジタル機器を自律的に制御し、情報収集や情報処理を行う。
これらのツールの実際の性能を理解するために、5つの製品すべてに同じ比較的複雑な調査タスクを提示した。
比較テスト:AIモデル研究の生成
ミッションの要件
以下のアウトラインに基づき、AIモデリングに関する約5,000語の研究論文を提出すること:
- 現代の大規模言語モデルの概要(GPTファミリー、Claude、LLaMA、DeepSeekなど)
- 各モデルの特徴と適用シーンの比較
- モデル能力の境界と限界の分析
- オープンソースとクローズドソースのモデル選択戦略
- モデルAPI基礎チュートリアル
- ビッグモデル技術の原理を簡潔に解説
実施する:
- ジェミニ・ディープ・サーチ:300以上のウェブページを検索するのに8分かかる。
- Grok 3ディープサーチ:160以上のウェブページを検索するのに6分かかりました。
- マヌス:21分かかり、8つのサブタスクが実行されたと報告された。
- 三田AIシャローリサーチ:300以上のウェブページを7分で検索。
- Zhipu AutoGLM:71のウェブページを検索するのに16分かかった。
注釈 待ち時間と検索量はこのテストの参考データであり、実際のパフォーマンスはタスクの複雑さ、ネットワーク状況、サーバーの負荷によって異なる可能性があります。
各ツールの回答のまとめ:

(画像は、各ツールで作成されたレポートのスクリーンショットまたはサマリーの一部です。)
独立評価:クロードによる鋭い評価 3.7
比較的客観的な第三者の視点を得るために、私たちは生成された5つのレポートをAnthropicのClaude 3.7モデルに提出し、評価を受けました。以下は、各レポートに対するClaude 3.7の評価の要約である:
ZhipuオートGLM
71もの参考文献を引用することで、学術論文の形式を模倣しようとしているが、これはかなり空虚である。言葉遣いが過度にアカデミックで、まるで中身のなさをレトリックでごまかしているかのようだ。モデルの長所と短所の分析は、製品説明を繰り返すようなもので、洞察に深みがない。
マヌス
この報告書は極端に言えば、複雑な技術的問題を「政策立案者のため」という名目で単純化しすぎ、綿密な分析を表面的なマーケティングコピーに変えている。量子物理学の子供向け本のように、深みも正確さもない。
ジェミニ・ディープ・サーチ
報告書はアカデミックな文体を採用しているが、引用符が多用されており、読み進める妨げになっている。実質的な情報を追加することなく、単純な概念の説明に多くのスペースを割いている。非専門家向けと言いながら、説明不足の専門用語が多く、目的を達していない。
Grok 3 ディープ・サーチ
簡潔版と詳細版の両方が用意されているのは特徴だが、内容の一貫性に問題があることも露呈している。簡潔版は簡略化されすぎており、詳細版の予測(2025年など)の中には、十分な論拠や必要な前提条件が示されていないため、やや憶測的なものもある。
三田AIシャローリサーチ
情報を構造化するために表を多用しているため、情報収集の効率は向上しているが、表や区切り文字に過度に依存しているため、内容の機械的な表現につながり、物語としての一貫性や深みが欠けている。また、技術的な説明は実際の適用シナリオと十分にリンクしておらず、ビジネスコスト分析では、さまざまな規模の企業に対する差別化された考慮が欠けている。
クロード3.7に関する一般的見解:
これら5つの報告書はいずれも、内容の欠点をカバーするためにさまざまな「パッケージング」を試みている。学術的なものであれ、商業的なものであれ、技術的なものであれ、核心に触れることはできていないようだ。例えば、報告書の ディープシーク 過剰な注目は、新技術を追い求める業界の一般的な姿勢を反映しているのかもしれないが、一方で、データ・プライバシーや倫理遵守といった重要な問題を軽視していることは、分析視点の限界を露呈している。優れた技術調査報告書は、言葉遊びではなく、洞察と現実的な分析を提供すべきである。この基準に照らし合わせると、5つの報告書すべてに改善の余地がある。
総合成績と採点
Claude 3.7の評価とレポート内容の直接レビューに基づき、このテストにおけるツールのパフォーマンスを総合的に評価することが可能である:
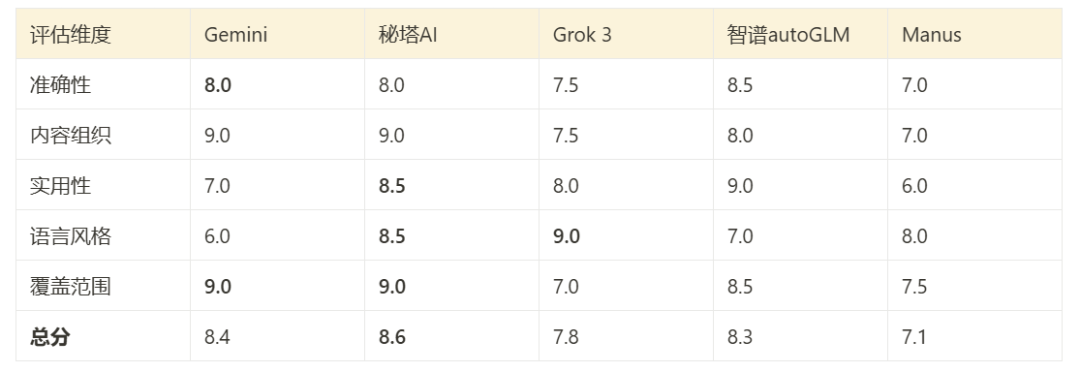
(写真はテスト結果に基づく総合採点表)
- ジェミニ・ディープ・サーチより整理されたコンテンツ、幅広いカバー範囲、多言語サポートが強みだ。
- 三田AIシャローリサーチ技術的な深みと読みやすさのバランスがよく取れている。
- Grok 3 ディープ・サーチ柔軟な言語スタイル(デュアルバージョン)と強い語用論的志向。
- ZhipuオートGLM技術的な内容は非常に正確だが、専門家以外には読みにくい。
- マヌス簡潔で理解しやすいが、分析の深さは犠牲になっている。
選び方:さまざまなシーンでの使い方の提案
このテストと各ツールの特徴に基づき、選択のための提案を以下に示す:
検索機能の概要
- ジェミニ・ディープ・サーチ検索は幅広く、グローバルな多言語リソースを統合するのに適しているが、中国語のコンテンツを深く理解するには、ローカライズされた製品ほど優れていないかもしれない。
- Grok 3 ディープ・サーチ特にビジネス情報とニュースにおいてリアルタイム性が高いが、技術的な内容の深さは比較的弱い。
- ZhipuオートGLM引用文献の質は高く、技術的概念を深く理解しているが、検索は比較的限定的である。
- 三田AIシャローリサーチ英語と中国語の情報の強力な統合、専門分野のより包括的なカバー、構造化された情報の正確な抽出。
- マヌスしかし、このプラットフォームは、複数のソースからの情報の統合や複雑なワークフローをサポートするように設計されている。
このテストに基づく)検索および調査スキルの予備的ランキング:
- 三田AIシャローリサーチ専門分野でのディープサーチ、英語と中国語のバイリンガル処理で卓越したパフォーマンス。
- ジェミニ・ディープ・サーチ世界の資源を最も多用途かつ広範囲にカバー。
- ZhipuオートGLM中国の技術文献の取り扱いに長け、深い理解がある。
- Grok 3 ディープ・サーチリアルタイムのビジネス情報やニュースへのアクセスをリードしています。
- マヌス純粋な検索ランキングよりも、タスク実行の柔軟性や複数モデルの呼び出しに強みがあるかもしれない。
シナリオに基づく提言
- 学術研究Zhipu AutoGLM(参考文献の質の高さ)が優先され、Mita AI(専門領域のカバー率)がそれに続いた。
- ビジネス分析グロック3(リアルタイム、ビジネス情報)が優先され、ジェミニ(グローバルビジョン)がそれに続く。
- 技術開発三田AI(文書理解、構造抽出)、Zhipu AutoGLM(技術的な深さ)の順。
- 日常的な情報アクセス/一般的なリサーチジェミニ(広いカバー範囲)が優先され、グロック3(適時性)がそれに続く。
- 綿密な中国語コンテンツ調査Zhipu AutoGLMまたはMita AIは、母国語と文脈の理解に優れているため、優先的に採用されます。
重要なヒント
- 交差検証重要な情報や重要な意思決定については、情報の正確性と完全性を保証するために、少なくとも2つの異なるツールを用いた比較検証を行うことを強く推奨する。
- タスクマッチング万能のツールはありません。どの製品を選ぶべきかは、具体的な調査タスク、必要な情報のタイプ(リアルタイムか詳細か、技術的か商業的か)、レポートの形式と深さに関する要件によって大きく異なります。
- テストの制限この比較は1つのタスクのみに基づいています。同じように マヌス タスクフローとマルチフォーマット配信機能を重視するこのようなツールの利点は、他のタイプのタスクが実行されるまでは、十分に実感できないかもしれない。さらに、ユーザー・インターフェース、コスト、API統合能力も、実際の選択において考慮すべき要素である。
これらのAIリサーチ・アシスタント・ツールは、情報へのアクセスや分析方法における将来のトレンドであることは間違いない。現在のところ、それぞれに長所と短所があるが、急速なペースで進化しており、継続的な注目に値する。適切なツールを選択し、効果的な使い方を習得することで、研究や意思決定が大幅に強化されるだろう。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事




コメントはありません