LLM微調整の4つのステップ:SiliconCloudによるドメインラージモデル構築の実践ガイド

以前、シリコンクラウドは、その言語モデルでオンラインになった。オンラインLoRA微調整機能.コーパスデータをアップロードし、ファインチューニングタスクを作成するだけで、独自にファインチューニングされた言語モデルを得ることができる。
最近、SiliconCloudのLLMオンラインLoRAファインチューニングは、ファインチューニングのベースモデルとしてQwen2.5-32B、Qwen2.5-14B、Llama-3.1-8Bモデルを拡張し、ファインチューニングのプレイアビリティをさらに向上させ、ファインチューニングモデルのトレーニングと使用コストをさらに削減しました。
実際、独自のビッグ言語モデルの微調整は非常に簡単です。SiliconCloudのファインチューニング機能を使えば、数十個のトレーニング・コーパスを用意するだけで、ベースモデルからモデルを「大幅に」変更することができます。
事前準備
まず、微調整が何を達成しようとしているのかを明確にする必要がある。多くの場合、ファインチューニングは、モデルがトレーニングに含まれていなかった何かを学習したり、ある独特の言語スタイルを身につけたりするのに役立つ。
目的が異なれば、アプローチも異なる。例えば、モデルに特定のドメイン知識を学習させたいのであれば、それに基づいた質問と回答を含む学習データが必要ですし、モデルに特定の典型的な言語スタイルを学習させたいのであれば、そのスタイルを持つ対話データが必要です。
データ準備
LLMモデルのファインチューニングでは、LLMの呼び出しメッセージと本質的に同じデータ構造を持つダイアログの形でデータを提供する必要がある。テキスト生成インターフェースは、微調整されたデータを構築するために呼び出されると言える。
以下は、微調整されたデータの典型的な例である:
{"messages": [{"role": "system", "content": "你是消防系统专家"}, {"role": "user", "content": "家里的火灾报警器怎么安装?"}, {"role": "assistant", "content": "根据《家用火灾安全系统》(GB22370—2008)的规定,家用火灾报警器的安装应符合制造商的要求。具体来说,安装时应确保设备处于正常监视状态,并且连接到相应的火灾探测器和其他部件。安装位置应避免高温、潮湿和尘土较多的地方,以保证设备的正常运行。"}]}
微調整を行うには、通常、このようなデータを数十個用意し、1行1行の形式で「jsonl」ファイルとして保存する必要がある:
{"messages": [{"role": "system", "content": "你是消防系统专家"}, {"role": "user", "content": "家里的火灾报警器怎么安装?"}, {"role": "assistant", "content": "根据《家用火灾安全系统》(GB22370—2008)的规定,家用火灾报警器的安装应符合制造商的要求。具体来说,安装时应确保设备处于正常监视状态,并且连接到相应的火灾探测器和其他部件。安装位置应避免高温、潮湿和尘土较多的地方,以保证设备的正常运行。"}]}
{"messages": [{"role": "system", "content": "你是消防系统专家"}, {"role": "user", "content": "火灾报警器的电源要求是什么?"}, {"role": "assistant", "content": "根据《家用火灾安全系统》(GB22370—2008)的规定,家用火灾报警控制器的主电源应采用220V、50Hz交流电源,电源线输入端应设接线端子。备用电源应为可多次充放电的蓄电池,在不超过生产厂商规定的极限放电情况下,应能将电池在24小时内充至额定容量80%以上,再充48小时后应能充满。"}]}
{"messages": [{"role": "system", "content": "你是消防系统专家"}, {"role": "user", "content": "火灾报警器的声光信号有什么要求?"}, {"role": "assistant", "content": "根据《家用火灾安全系统》(GB22370—2008)的规定,火灾声警报器的声信号至少在一个方向上3米处的声压级应不小于75dB(A计权),且在任意方向上3米处的声压级应不大于120dB(A计权)。火灾光警报器的光信号在100lx~500lx环境光线下,25米处应清晰可见。"}]}
{"messages": [{"role": "system", "content": "你是消防系统专家"}, {"role": "user", "content": "火灾报警器的故障信号怎么处理?"}, {"role": "assistant", "content": "根据《家用火灾安全系统》(GB22370—2008)的规定,当发生与所连接部件之间的通讯故障、备用电源充电器与备用电源间连接线断路或短路、备用电源与其负载间连接线断路或短路、主电源欠压等故障时,家用火灾报警控制器应在100秒内发出故障声、光信号,并指示故障类型。故障声信号应能手动消除,再有故障信号输入时,应能再次启动。"}]}
{"messages": [{"role": "system", "content": "你是消防系统专家"}, {"role": "user", "content": "火灾报警器的自检功能怎么用?"}, {"role": "assistant", "content": "根据《家用火灾安全系统》(GB22370—2008)的规定,家用火灾报警控制器应能对本机进行功能检查(自检)。在执行自检功能期间,受其控制的外接设备和输出接点均不应动作。自检时间超过1分钟或不能自动停止自检功能时,其非自检部位和控制器本身的火灾报警功能不应受到影响。"}]}
{"messages": [{"role": "system", "content": "你是消防系统专家"}, {"role": "user", "content": "火灾报警器的信息显示有什么要求?"}, {"role": "assistant", "content": "根据《家用火灾安全系统》(GB22370—2008)的规定,采用数字、字母显示工作状态的家用火灾报警控制器应按显示火灾报警、监管报警及其他状态顺序由高至低排列信息显示等级。高等级的状态信息应优先显示,低等级状态信息显示不应影响高等级状态信息显示。显示的信息应与对应的状态一致且易于辨识。"}]}
{"messages": [{"role": "system", "content": "你是消防系统专家"}, {"role": "user", "content": "火灾报警器的声压级是多少?"}, {"role": "assistant", "content": "根据《家用火灾安全系统》(GB22370—2008)的规定,家用火灾报警控制器在各种报警状态下的声压级(正前方1米处)应不小于75dB(A计权)。"}]}
{"messages": [{"role": "system", "content": "你是消防系统专家"}, {"role": "user", "content": "可燃气体探测器怎么安装?"}, {"role": "assistant", "content": "根据《可燃气体报警控制器》(GB16808—2008)的规定,可燃气体探测器应按制造商的要求进行安装,并连接到可燃气体报警控制器上。安装位置应避免高温、潮湿和尘土较多的地方,以保证设备的正常运行。"}]}
{"messages": [{"role": "system", "content": "你是消防系统专家"}, {"role": "user", "content": "可燃气体探测器的报警功能有什么要求?"}, {"role": "assistant", "content": "根据《可燃气体报警控制器》(GB16808—2008)的规定,可燃气体探测器应具有低限报警或低限、高限两段报警功能。当有可燃气体报警信号输入时,控制器应在10秒内发出报警声、光信号,并保持至手动复位。"}]}
{"messages": [{"role": "system", "content": "你是消防系统专家"}, {"role": "user", "content": "如何检查火灾报警器的绝缘性能?"}, {"role": "assistant", "content": "根据《家用火灾安全系统》(GB22370—2008)的规定,通过绝缘电阻试验装置分别对试样的外部带电端子与机壳之间施加500V±50V直流电压,持续60秒±5秒后测量其绝缘电阻值。试样有绝缘要求的外部带电端子与机壳间的绝缘电阻值应不小于20MΩ;试样的电源输入端与机壳间的绝缘电阻值应不小于50MΩ。"}]}
日常業務で比較的多くの高品質なデータが蓄積されている場合は、簡単なデータクリーニングを行い、フォーマット要件を満たすデータファイルを構築することで、ファインチューニングを開始することができる。データの蓄積が不足していたり、クリーニングのプロセスが複雑であったりする場合は、ビッグモデルの助けを借りて微調整を試みたり、モデルを用いてデータを構築したりすることができる。
次に、データを構築するプロセスを練習するために例を使用します。消防の基準で質問と回答を構成し、「消防の専門家」の大規模モデルを訓練してみよう。
テクトニック・ファインチューニング・データ
SiliconCloudは128Kのコンテクストを持つQwen2.5モデルを提供しており、これはかなりリッチなコンテンツをカバーするには十分すぎるほどだ。
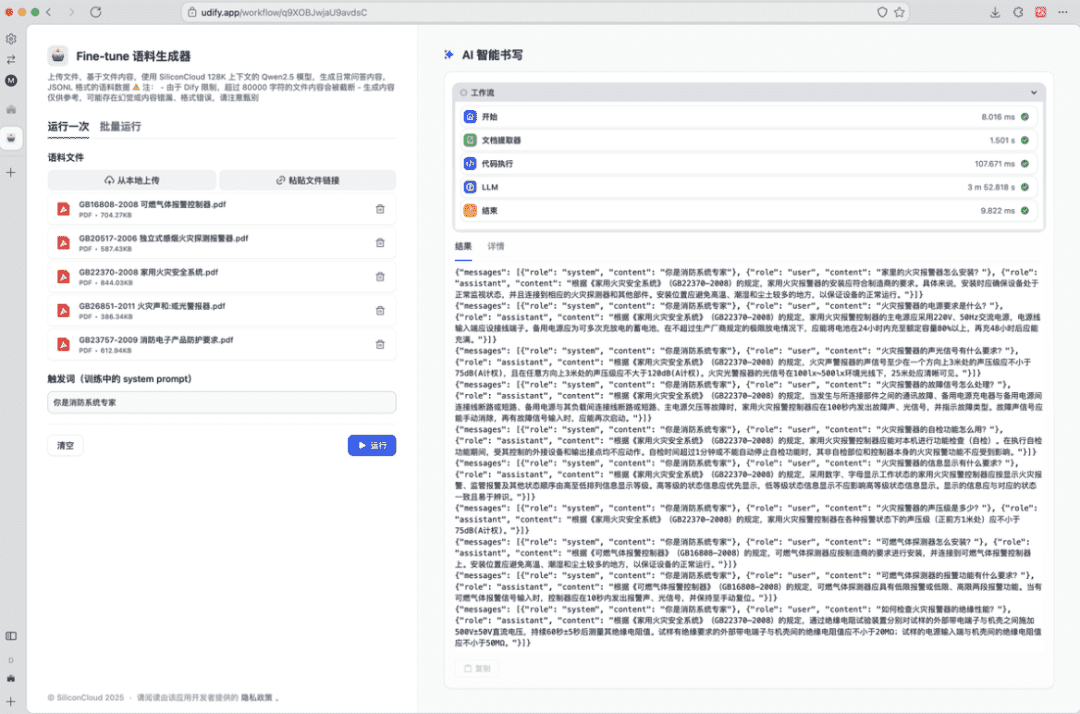
まず、データを作成するために使用するファイルをローカルに用意する必要があります。例えば、"GB22370-2008 Domestic Fire Safety Systems.pdf "です。
次に、ファイルの内容を抽出し、プロンプトを書き込み、Qwen Big Model に上記の要件を満たすデータを生成させる必要がある。これはコードで行うか、あるいは ダイファイ などのインターフェイスツールが完成する。
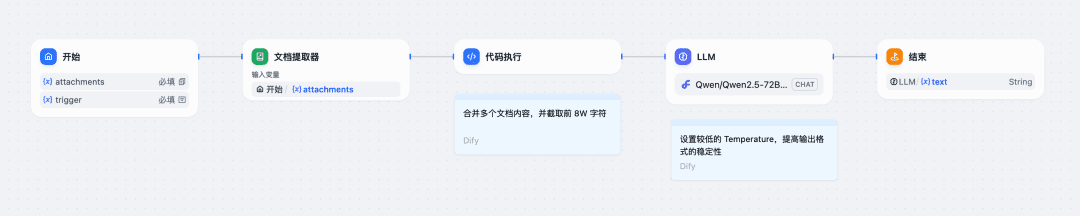
Difyでワークフローを構成する例を見てみましょう:
1.スタートノード設定ファイルがアップロードされ、トレーニングコーパスのシステムプロンプトフィールドが入力されます;
2.Difyに付属しているドキュメント抽出ノードとコードノードを使って、ファイルの内容をテキストにマージします;
3.LLMノードを使用して、SiliconCloudのQwen/Qwen2.5-72B-Instruct-128Kモデルを呼び出します(ファイルの長さが32K以内の場合は、プラットフォームが提供する別のモデルを選択できます):
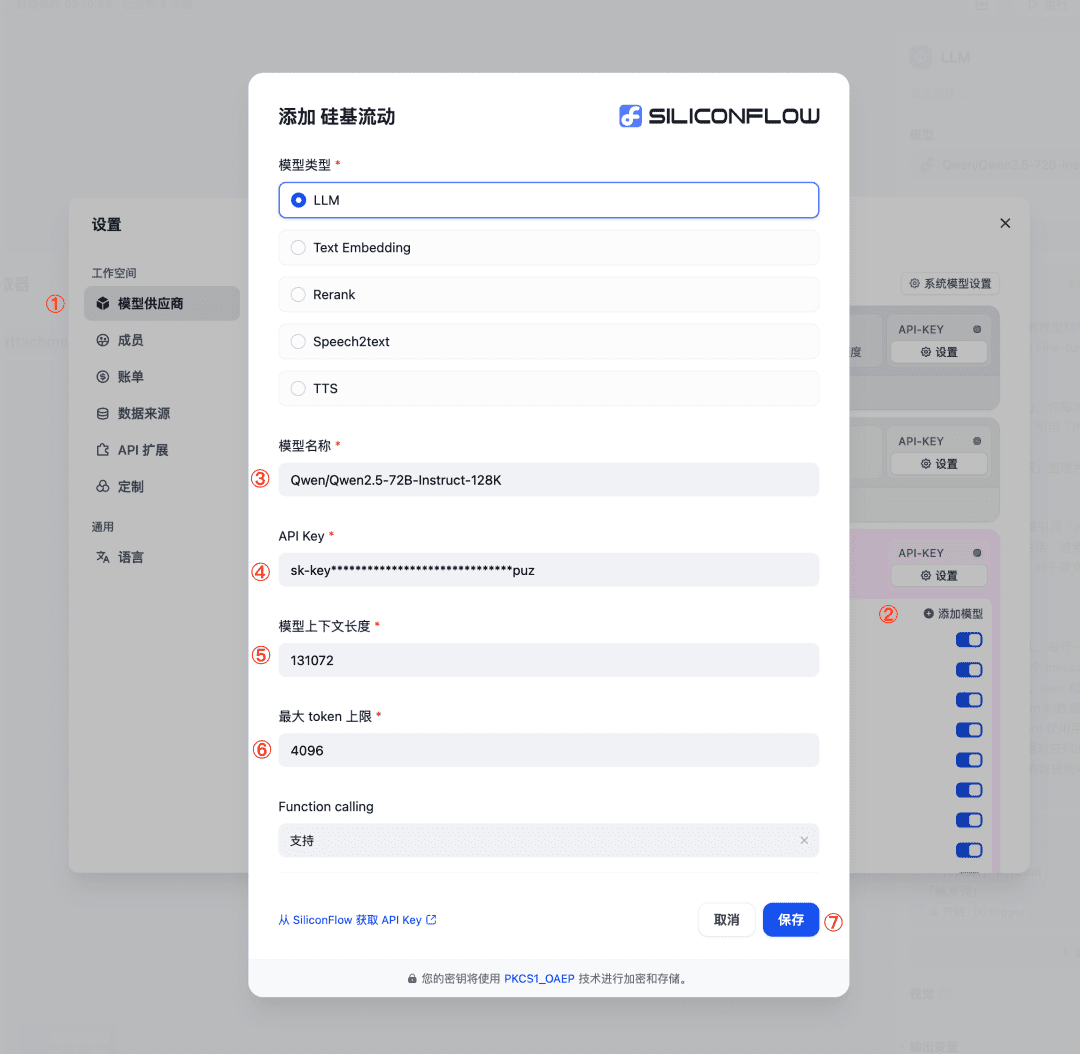
- Settings - Model VendorでSiliconFlowを選択します;
- Add Modelをクリックし、画像を参照して必要なパラメータを入力し、保存する。
- マクロモデルの出力をワークフローの出力として使用することで、実行後にコーパスデータのバッチを得ることができる;
- 次に、この内容をコピーして.jsonlファイルとして保存し、SiliconCloudにアップロードするだけで、微調整タスクが作成される。
一度に生成されるデータが十分でない場合は、複数回実行してより多くのデータを構築することができる。
注意しなければならないのは、より細かく調整されたデータが必ずしも良いとは限らないということだ。たとえデータが1つしかなくても、ファインチューニングを始めることができる。たとえデータが1つしかなくても、微調整を始めることができる。逆に、質が十分でないデータがたくさんあれば、微調整の効果は期待通りにならないかもしれない。
app: description: '上传文件,基于文件内容,使用 SiliconCloud 128K 上下文的 Qwen2.5 模型,生成日常问答内容,JSONL 格式的语料数据 ⚠️ 注: - 由于 Dify 限制,超过 80000 字符的文件内容会被截断 - 生成内容仅供参考,可能存在幻觉或内容错漏、格式错误,请注意甄别' icon: 🤖 icon_background: '#FFEAD5' mode: workflow name: Fine-tune 语料构造器 use_icon_as_answer_icon: false kind: app version: 0.1.5 workflow: conversation_variables: [] environment_variables: [] features: file_upload: allowed_file_extensions: - .JPG - .JPEG - .PNG - .GIF - .WEBP - .SVG allowed_file_types: - image allowed_file_upload_methods: - local_file - remote_url enabled: false fileUploadConfig: audio_file_size_limit: 50 batch_count_limit: 5 file_size_limit: 15 image_file_size_limit: 10 video_file_size_limit: 100 workflow_file_upload_limit: 10 image: enabled: false number_limits: 3 transfer_methods: - local_file - remote_url number_limits: 3 opening_statement: '' retriever_resource: enabled: true sensitive_word_avoidance: enabled: false speech_to_text: enabled: false suggested_questions: [] suggested_questions_after_answer: enabled: false text_to_speech: enabled: false language: '' voice: '' graph: edges: - data: isInIteration: false sourceType: start targetType: document-extractor id: 1735807686274-source-1735807758092-target source: '1735807686274' sourceHandle: source target: '1735807758092' targetHandle: target type: custom zIndex: 0 - data: isInIteration: false sourceType: document-extractor targetType: code id: 1735807758092-source-1735807761855-target source: '1735807758092' sourceHandle: source target: '1735807761855' targetHandle: target type: custom zIndex: 0 - data: isInIteration: false sourceType: code targetType: llm id: 1735807761855-source-1735807764975-target source: '1735807761855' sourceHandle: source target: '1735807764975' targetHandle: target type: custom zIndex: 0 - data: isInIteration: false sourceType: llm targetType: end id: 1735807764975-source-1735807769820-target source: '1735807764975' sourceHandle: source target: '1735807769820' targetHandle: target type: custom zIndex: 0 nodes: - data: desc: '' selected: false title: 开始 type: start variables: - allowed_file_extensions: [] allowed_file_types: - document allowed_file_upload_methods: - local_file - remote_url label: 语料文件 max_length: 10 options: [] required: true type: file-list variable: attachments - allowed_file_extensions: [] allowed_file_types: - image allowed_file_upload_methods: - local_file - remote_url label: 触发词(训练中的 system prompt) max_length: 48 options: [] required: true type: text-input variable: trigger height: 116 id: '1735807686274' position: x: 30 y: 258 positionAbsolute: x: 30 y: 258 selected: false sourcePosition: right targetPosition: left type: custom width: 244 - data: desc: '' is_array_file: true selected: false title: 文档提取器 type: document-extractor variable_selector: - '1735807686274' - attachments height: 92 id: '1735807758092' position: x: 334 y: 258 positionAbsolute: x: 334 y: 258 selected: false sourcePosition: right targetPosition: left type: custom width: 244 - data: code: "def main(articleSections: list) -> dict:\n try:\n # 将列表项合并为字符串\n\ \ combined_text = \"\\n\".join(articleSections)\n \n \ \ # 截取前80000个字符\n truncated_text = combined_text[:80000]\n \ \ \n return {\n \"result\": truncated_text\n \ \ }\n except Exception as e:\n # 错误处理\n return {\n \ \ \"result\": \"\"\n }" code_language: python3 desc: '' outputs: result: children: null type: string selected: false title: 代码执行 type: code variables: - value_selector: - '1735807758092' - text variable: articleSections height: 54 id: '1735807761855' position: x: 638 y: 258 positionAbsolute: x: 638 y: 258 selected: false sourcePosition: right targetPosition: left type: custom width: 244 - data: context: enabled: false variable_selector: [] desc: '' model: completion_params: frequency_penalty: 0.5 max_tokens: 4096 temperature: 0.3 mode: chat name: Qwen/Qwen2.5-72B-Instruct-128K provider: siliconflow prompt_template: - id: b6913d40-d173-45d8-b012-98240d42a196 role: system text: '【角色】 你是一位 LLM 大语言模型科学家,参考用户提供的内容,帮助用户构造符合规范的 Fine-tune(微调)数据 【任务】 - 对于给定的「内容」,你每次回列出 10 个通俗「问题」; - 针对每个「问题」,引用「内容」原文及对内容的合理解释和演绎,做出「解答」; - 并将「问题」「解答」整理为规范的 JSONL 格式 【要求】 1. 问题 **不要** 直接引用「内容」,应该贴近当代现实生活; 2. 问题应该是通俗白话,避免“假、大、空“; 3. 答案应忠于原文,对于原文的解释不能脱离原文的主旨、思想; 【输出规范】 * 输出规范的 JSONL,每行一条数据 * 每条数据应包含一个 message 数组,每个数组都应该包含 role 分别为 system、user 和 assistant 的三条记录 * 其中 role 为 system 的数据,作为训练中的 system prompt 格外重要,其 content 使用用户指定的「触发词」 * role 为 user 的数据对应列出的「问题」 * role 为 assistant 的数据则对应针对「问题」的「解答」 * 示例如下: ``` {"messages": [{"role": "system", "content": "你是当代大儒"}, {"role": "user", "content": "应该怎么学习?"}, {"role": "assistant", "content": "贤贤易色;事父母,能竭其力;事君,能致其身;与朋友交,言而有信。虽曰未学,吾必谓之学矣。"}]} ```' - id: 61530521-14cf-4eaf-8f06-a4bc89db3cb1 role: user text: '「内容」 {{#1735807761855.result#}} 「触发词」 {{#1735807686274.trigger#}}' selected: false title: LLM type: llm variables: [] vision: enabled: false height: 98 id: '1735807764975' position: x: 942 y: 258 positionAbsolute: x: 942 y: 258 selected: true sourcePosition: right targetPosition: left type: custom width: 244 - data: desc: '' outputs: - value_selector: - '1735807764975' - text variable: text selected: false title: 结束 type: end height: 90 id: '1735807769820' position: x: 1246 y: 258 positionAbsolute: x: 1246 y: 258 selected: false sourcePosition: right targetPosition: left type: custom width: 244 - data: author: Dify desc: '' height: 88 selected: false showAuthor: true text: '{"root":{"children":[{"children":[{"detail":0,"format":0,"mode":"normal","style":"","text":"设置较低的 Temperature,提高输出格式的稳定性","type":"text","version":1}],"direction":"ltr","format":"","indent":0,"type":"paragraph","version":1,"textFormat":0}],"direction":"ltr","format":"","indent":0,"type":"root","version":1}}' theme: blue title: '' type: '' width: 240 height: 88 id: '1735808753316' position: x: 951.4285714285714 y: 375.7142857142857 positionAbsolute: x: 951.4285714285714 y: 375.7142857142857 selected: false sourcePosition: right targetPosition: left type: custom-note width: 240 - data: author: Dify desc: '' height: 88 selected: false showAuthor: true text: '{"root":{"children":[{"children":[{"detail":0,"format":0,"mode":"normal","style":"","text":"合并多个文档内容,并截取前 8W 字符","type":"text","version":1}],"direction":"ltr","format":"","indent":0,"type":"paragraph","version":1,"textFormat":0}],"direction":"ltr","format":"","indent":0,"type":"root","version":1}}' theme: blue title: '' type: '' width: 240 height: 88 id: '1735808799815' position: x: 640 y: 338.5714285714286 positionAbsolute: x: 640 y: 338.5714285714286 selected: false sourcePosition: right targetPosition: left type: custom-note width: 240 viewport: x: 0 y: 0 zoom: 0.7
Difyのようなツールの使用に加えて、Qwen/Qwen2.5-Coder-32B-Instructのようなモデルを直接使用して、実行するスクリプトの作成を支援することも、微調整されたデータを構築する効率的な方法であり、3者間プラットフォームのいくつかの制限を回避することができます。データである。
トレーニングと検証の微調整
SiliconCloudプラットフォームで新しい微調整タスクを作成し、先ほど保存した.jsonlファイルをアップロードして選択し、Start Fine-Tuningをクリックします。 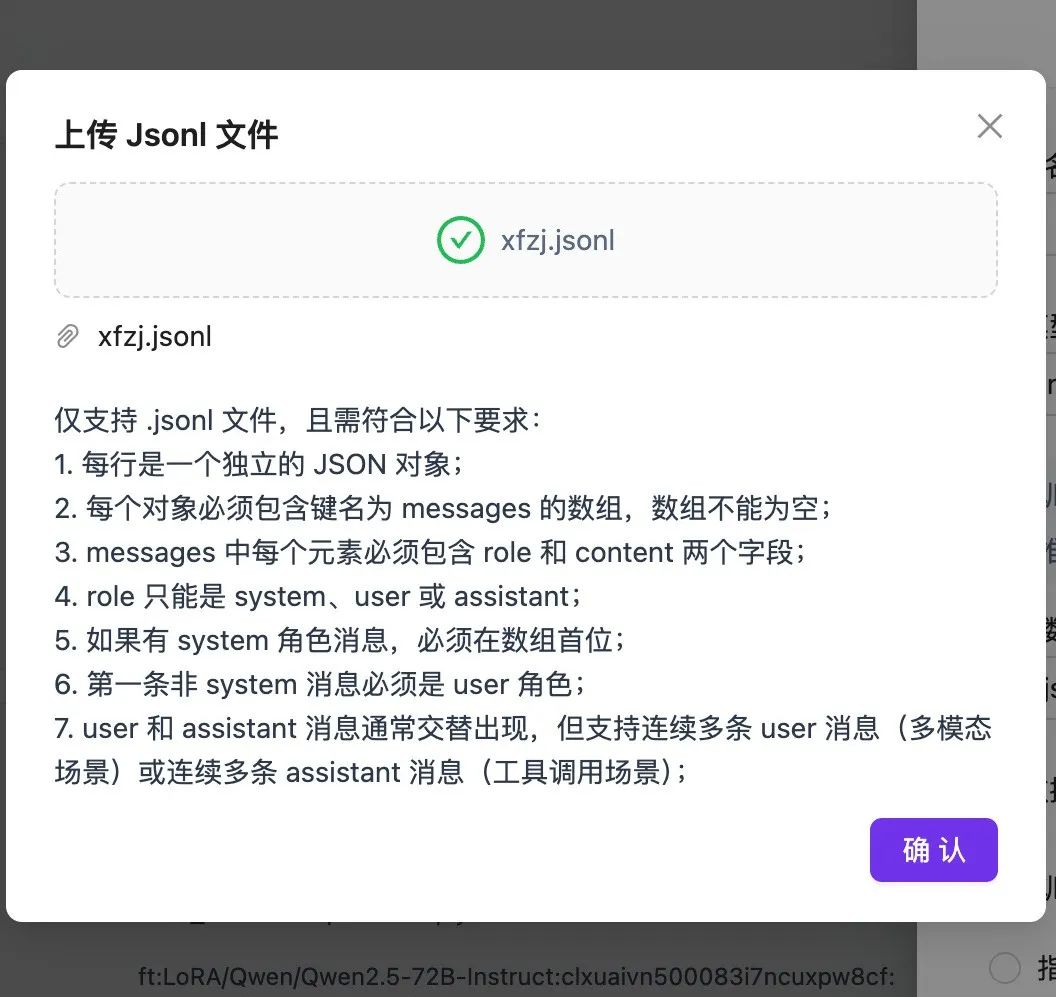
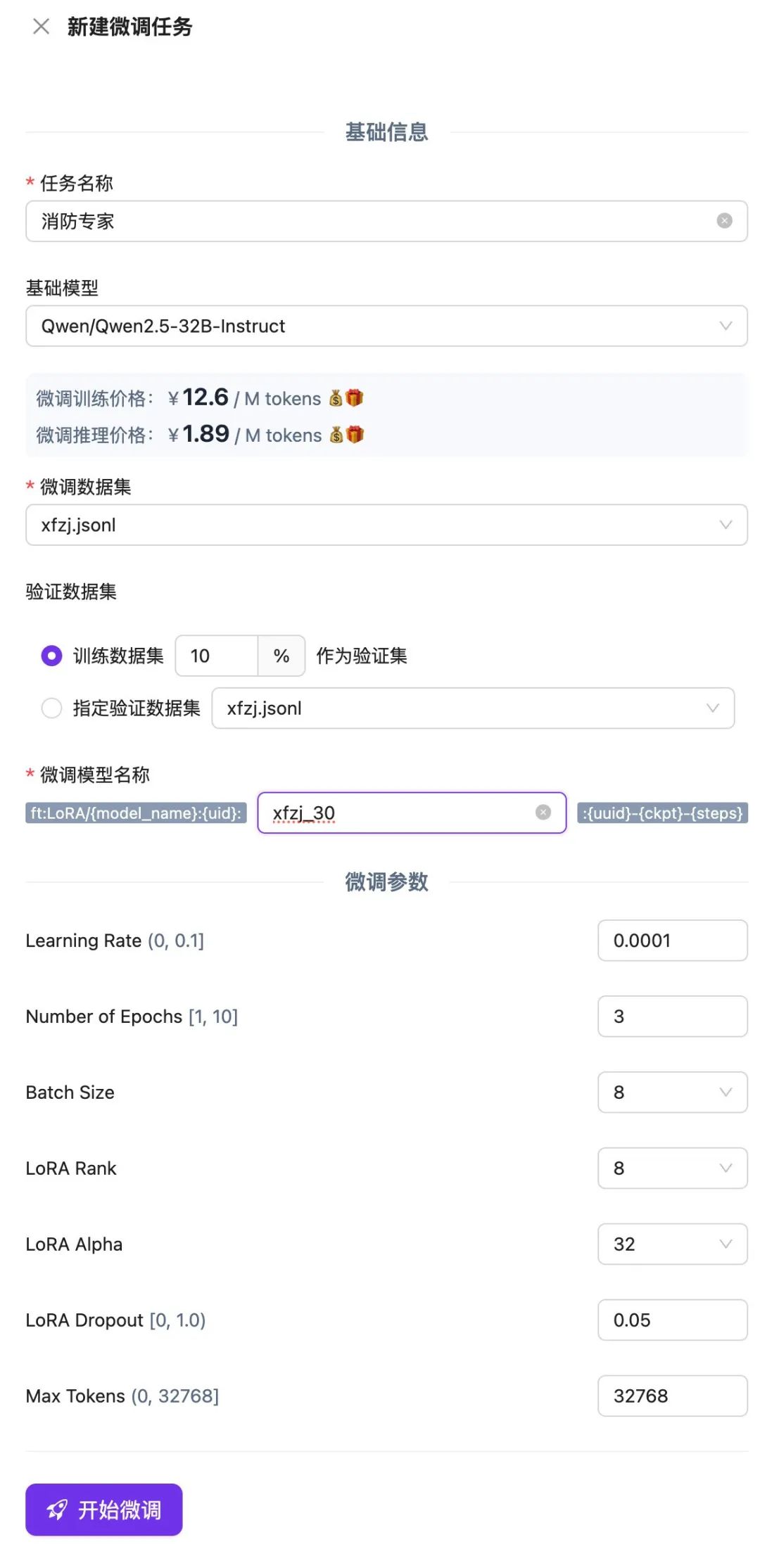 ファインチューニング・タスクのキューイングが終了するのを待ち、実行が完了したら、ファインチューニングされたモデルを使用するか、オンライン・エクスペリエンスやAPIを通じて結果を検証することができる。
ファインチューニング・タスクのキューイングが終了するのを待ち、実行が完了したら、ファインチューニングされたモデルを使用するか、オンライン・エクスペリエンスやAPIを通じて結果を検証することができる。  ダイアログ・モデルのオンライン・エクスペリエンスの比較機能では、複数のチェックポイント・モデルとベース・モデルでモデルの応答と出力を比較し、最も効果的なモデルを選択して使い続けることもできます。微調整モデルとベースモデルの比較
ダイアログ・モデルのオンライン・エクスペリエンスの比較機能では、複数のチェックポイント・モデルとベース・モデルでモデルの応答と出力を比較し、最も効果的なモデルを選択して使い続けることもできます。微調整モデルとベースモデルの比較 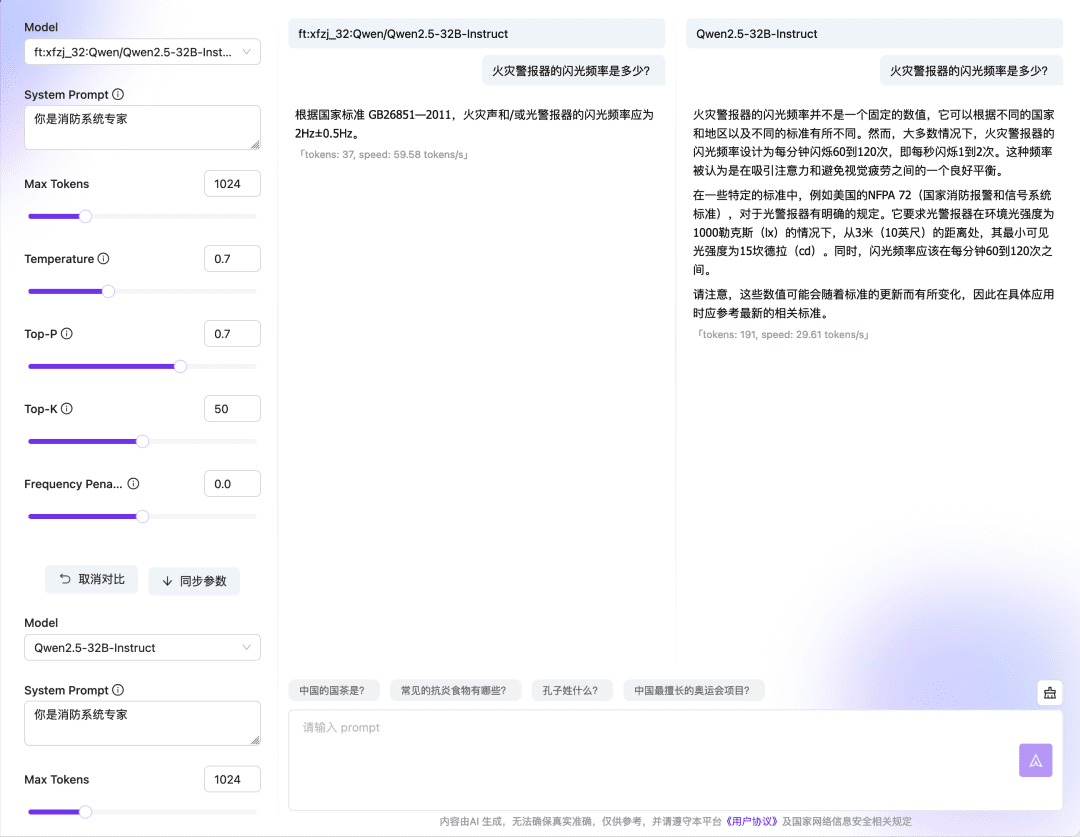 複数のチェックポイント間の比較:
複数のチェックポイント間の比較: 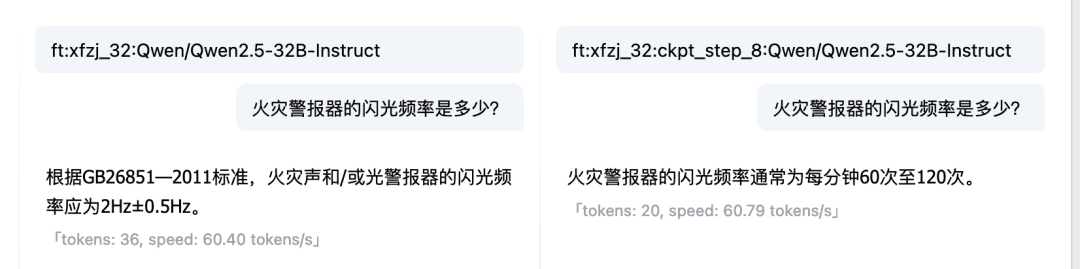 この時点で、ローカルファイルを使ってLLMファインチューニングデータを構築し、ファイヤーエキスパートLLMをファインチューニングした。もちろん、上記の手順で、独自のドメイン固有のLLMを構築してみることもできる。
この時点で、ローカルファイルを使ってLLMファインチューニングデータを構築し、ファイヤーエキスパートLLMをファインチューニングした。もちろん、上記の手順で、独自のドメイン固有のLLMを構築してみることもできる。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません