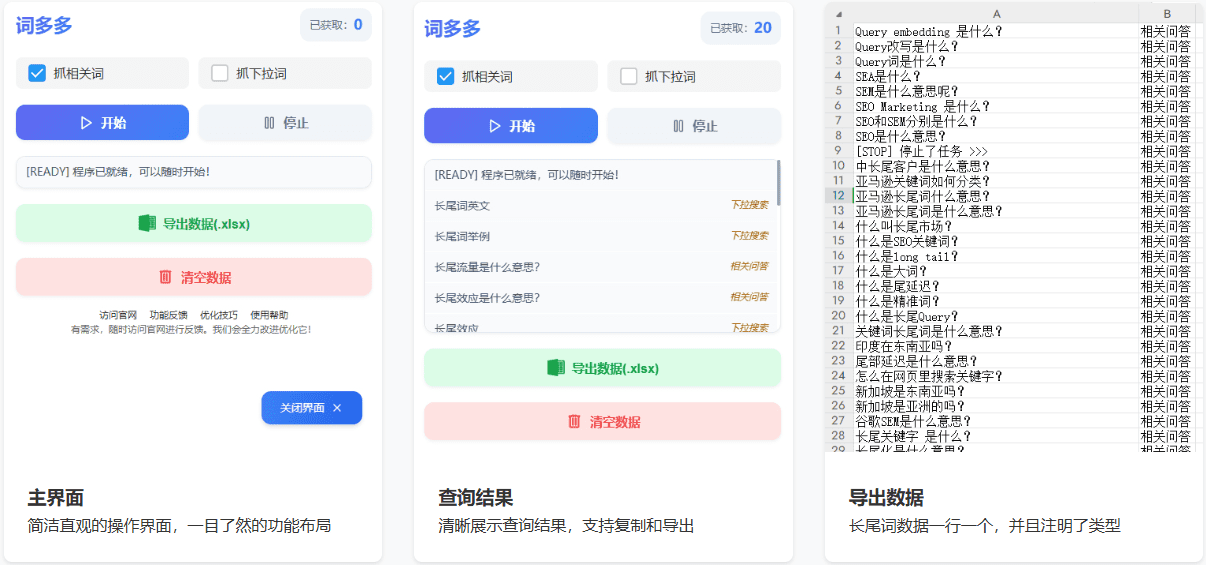
L'apprentissage profond (Deep Learning), c'est quoi, un article pour comprendre

Définition de l'apprentissage profond
apprentissage profond(Deep Learning) est une branche de l'apprentissage automatique qui se concentre sur l'utilisation de réseaux neuronaux artificiels multicouches pour apprendre et représenter des modèles complexes dans les données. La structure de ces réseaux neuronaux s'inspire des réseaux neuronaux du cerveau humain et est mise en œuvre de manière mathématique et informatique. Les modèles d'apprentissage profond contiennent plus de couches cachées que les méthodes traditionnelles d'apprentissage automatique peu profond et peuvent automatiquement extraire des représentations de caractéristiques multicouches à partir de données brutes. Par exemple, dans une tâche de reconnaissance d'images, un réseau peu profond peut n'être capable que d'identifier des caractéristiques de base telles que les bords, alors qu'un réseau profond peut progressivement combiner ces bords pour former des textures et des motifs, et finalement identifier l'objet dans son intégralité.
L'apprentissage profond a évolué grâce à trois piliers : l'émergence d'ensembles de données à grande échelle, de puissantes ressources informatiques (en particulier l'accélération GPU) et les progrès de la théorie algorithmique. Des percées ont été réalisées dans de nombreux domaines, tels que la vision artificielle, le traitement du langage naturel et la reconnaissance vocale. Le processus de formation de l'apprentissage profond implique généralement une grande quantité de données, et les paramètres du réseau sont ajustés par des algorithmes de rétropropagation afin de minimiser l'erreur entre les prédictions du modèle et les valeurs réelles. Bien que l'apprentissage profond nécessite de grandes quantités de données et de ressources informatiques, ses capacités résident dans le traitement de données non structurées à haute dimension, telles que les images, les sons et les textes, qui sont souvent difficiles à traiter avec les méthodes traditionnelles d'apprentissage automatique.

Concepts de base et principes fondamentaux de l'apprentissage profond
Les fondements de l'apprentissage profond reposent sur plusieurs concepts clés qui, ensemble, forment le cadre de sa théorie et de sa pratique.
- réseau neuronal artificielLes réseaux neuronaux artificiels sont les éléments de base de l'apprentissage en profondeur et se composent de nœuds interconnectés (neurones) organisés en couches d'entrée, cachées et de sortie. Chaque connexion est pondérée et les neurones appliquent une fonction d'activation pour traiter le signal d'entrée.
- réseau neuronal profondLes réseaux neuronaux profonds : Les réseaux neuronaux profonds contiennent plusieurs couches cachées qui permettent au modèle d'apprendre les caractéristiques hiérarchiques des données. Les réseaux profonds les plus courants sont les réseaux neuronaux convolutifs (CNN), les réseaux neuronaux récurrents (RNN) et les transformateurs.
- fonction d'activationLes fonctions d'activation introduisent des propriétés non linéaires qui permettent aux réseaux d'apprendre des schémas complexes. Les fonctions d'activation couramment utilisées sont ReLU, Sigmoïde et Tanh, qui déterminent si un neurone doit être activé ou non.
- fonction de perteFonctions de perte : Les fonctions de perte mesurent la différence entre les prédictions du modèle et la valeur réelle, ce qui permet d'orienter le processus de formation. Les fonctions de perte les plus courantes sont l'erreur quadratique moyenne et la perte d'entropie croisée.
- algorithme d'optimisationLes algorithmes d'optimisation sont utilisés pour ajuster les poids du réseau afin de minimiser la fonction de perte. La descente stochastique de gradient (SGD) et ses variantes (par exemple Adam) sont des méthodes d'optimisation largement utilisées.
- propagation à reboursLa rétropropagation est un algorithme clé pour la formation des réseaux neuronaux, où les paramètres sont ajustés couche par couche, de la sortie à la couche d'entrée, en calculant le gradient de la fonction de perte par rapport aux poids.
- Surajustement et régularisationSurajustement : Le surajustement se produit lorsque le modèle est surajusté aux données d'apprentissage et que sa capacité de généralisation est réduite. Les techniques de régularisation (telles que le Dropout et le weight decay) permettent d'éviter l'overfitting.
- normalisation des lotsLa normalisation par lots accélère l'apprentissage et améliore la stabilité en normalisant les entrées des couches et en réduisant l'effet du biais des covariables internes.
- représentation intégréeLes modèles d'apprentissage profond apprennent des représentations distribuées des données, en mettant en correspondance les entrées avec des vecteurs dans un espace à haute dimension qui capture les relations sémantiques.
Comment fonctionne l'apprentissage profond et le processus de formation
La formation de modèles d'apprentissage profond est un processus itératif impliquant de multiples étapes et considérations.
- Préparation des donnéesLa formation commence par la collecte et le prétraitement des données, y compris le nettoyage, la normalisation et l'amélioration. Les données sont divisées en un ensemble de formation, un ensemble de validation et un ensemble de test afin d'évaluer les performances du modèle.
- propagation vers l'avantLes données d'entrée passent par les couches du réseau et les poids et fonctions d'activation sont appliqués à chaque couche pour finalement produire la sortie prédite. Calculez la valeur de la perte au niveau de la couche de sortie.
- propagation à reboursLa valeur de perte calcule le gradient, qui est propagé de la couche de sortie à la couche d'entrée à l'aide de la règle de la chaîne. Le gradient indique la direction et l'ampleur de l'ajustement des poids.
- Mise à jour de la pondérationLes algorithmes d'optimisation utilisent des gradients pour mettre à jour les poids du réseau et réduire progressivement les pertes. Le taux d'apprentissage contrôle la taille du pas de mise à jour et affecte la vitesse de convergence et la stabilité.
- cycle itératifLa formation est répétée pendant plusieurs cycles (époques), chaque cycle parcourant l'ensemble des données de formation. Le modèle surveille les performances sur l'ensemble de validation afin d'éviter tout surajustement.
- réglage des hyperparamètresLes hyperparamètres tels que le taux d'apprentissage, la taille du lot et la structure du réseau doivent être ajustés pour trouver la configuration optimale par une recherche en grille ou une recherche aléatoire.
- accélération matérielle: La formation des réseaux profonds repose sur l'accélération des GPU ou TPU pour traiter un grand nombre d'opérations matricielles en parallèle et réduire le temps de formation.
- évaluation de la modélisationAprès l'apprentissage, le modèle est évalué sur un ensemble de tests, en utilisant des mesures telles que l'exactitude et la précision pour mesurer la capacité de généralisation.
- Déploiement et raisonnementLa phase d'inférence : Le modèle formé est déployé dans l'environnement de production pour traiter les nouvelles données et faire des prédictions. La phase d'inférence optimise l'efficacité des calculs pour répondre aux demandes en temps réel.
Scénarios d'application et implications de l'apprentissage profond
L'apprentissage profond a pénétré de nombreux domaines, favorisant l'innovation technologique et l'efficacité.
- vision par ordinateurL'apprentissage profond excelle dans la classification d'images, la détection d'objets et la reconnaissance faciale. Les voitures autonomes utilisent des modèles visuels pour détecter l'environnement, et l'analyse d'images médicales aide à diagnostiquer les maladies.
- le traitement du langage naturel (NLP)Traduction automatique, analyse des sentiments et chatbots : La traduction automatique, l'analyse des sentiments et les chatbots s'appuient sur l'apprentissage en profondeur (deep learning). Les modèles de transformation tels que BERT et GPT permettent une compréhension et une génération du langage plus précises.
- reconnaissance vocaleLes assistants intelligents tels que Siri et Alexa utilisent l'apprentissage profond pour convertir la parole en texte et traiter les signaux audio en temps réel.
- système de recommandationLes plateformes de commerce électronique et de streaming appliquent l'apprentissage profond pour analyser le comportement des utilisateurs, fournir des recommandations personnalisées et améliorer l'expérience des utilisateurs.
- Jeux et divertissementsL'apprentissage profond est utilisé pour les jeux d'IA, comme AlphaGo de DeepMind qui bat des champions humains. L'industrie du divertissement utilise la modélisation générative pour créer de l'art et de la musique.
- technologie financièreLes activités de l'entreprise : la détection des fraudes, l'évaluation des risques et le trading algorithmique utilisent l'apprentissage profond pour analyser les données du marché et améliorer la précision de la prise de décision.
- Soins de santéL'apprentissage profond facilite la découverte de médicaments, l'analyse génomique et le traitement personnalisé afin d'accélérer la recherche médicale.
- l'automatisation industrielleL'industrie manufacturière utilise l'apprentissage profond pour le contrôle de la qualité, la maintenance prédictive et la navigation des robots afin d'améliorer la productivité.
- protection de l'environnementLe projet de l'Institut de recherche sur les sciences de la vie et de l'environnement (IRSS) : applications d'apprentissage profond pour la modélisation du climat et la surveillance des espèces afin d'analyser l'imagerie satellitaire et les données des capteurs pour soutenir le développement durable.
Défis techniques et limites de l'apprentissage profond
Malgré ses résultats remarquables, l'apprentissage profond se heurte encore à plusieurs obstacles et limites techniques.
- Dépendance à l'égard des donnéesLes modèles d'apprentissage profond nécessitent de grandes quantités de données étiquetées, et les performances se dégradent lorsque les données sont rares ou de mauvaise qualité. Le processus d'étiquetage est coûteux et prend du temps.
- Besoins en ressources informatiques: La formation de réseaux profonds consomme d'énormes ressources informatiques et de l'énergie, ce qui limite les applications dans les environnements à ressources limitées. Les empreintes de carbone soulèvent des préoccupations environnementales.
- Mauvaise interprétabilité: Les modèles d'apprentissage profond sont souvent considérés comme des boîtes noires dont le processus de prise de décision est difficile à expliquer. Cela devient un obstacle dans les domaines où la transparence est nécessaire, tels que les soins de santé ou la justice.
- risque de surajustementLes modèles : Les modèles ont tendance à suradapter les données d'apprentissage, en particulier lorsque la quantité de données est insuffisante. Les techniques de régularisation atténuent le problème mais ne le résolvent pas complètement.
- Capacité limitée de généralisationLe modèle est peu performant sur les données d'entraînement hors distribution et manque d'adaptabilité et de raisonnement de bon sens à l'instar de l'homme.
- limitation du matériel: Les applications en temps réel nécessitent une inférence efficace, mais avec la puissance de calcul limitée des appareils périphériques tels que les appareils mobiles, la compression et la quantification des modèles deviennent nécessaires.
- Faible base théoriqueL'apprentissage profond : L'apprentissage profond manque d'un soutien théorique mathématique solide, et de nombreux succès reposent sur des conseils empiriques plutôt que théoriques, ce qui entrave les percées futures.
L'apprentissage profond par rapport à d'autres méthodes d'IA
L'apprentissage profond fait partie du vaste domaine de l'intelligence artificielle et est à la fois distinct et lié à d'autres approches.
- Relation avec l'apprentissage automatiqueL'apprentissage en profondeur : L'apprentissage en profondeur est un sous-ensemble de l'apprentissage automatique qui se concentre sur l'utilisation de réseaux neuronaux profonds. L'apprentissage automatique traditionnel repose davantage sur l'ingénierie des caractéristiques et sur des modèles peu profonds.
- Comparaison avec l'IA symboliqueL'IA symbolique est basée sur des règles et un raisonnement logique, tandis que l'apprentissage profond repose sur la reconnaissance des formes à partir de données. La combinaison des deux explore l'intégration neuronale-symbolique.
- Interaction avec l'apprentissage par renforcementL'apprentissage profond et l'apprentissage par renforcement sont combinés pour former l'apprentissage par renforcement profond pour l'intelligence artificielle des jeux et le contrôle des robots, qui traitent des espaces d'état à haute dimension.
- Chevauchement avec l'apprentissage non superviséL'apprentissage profond comprend des méthodes non supervisées telles que les auto-encodeurs et les réseaux adversaires génératifs pour la réduction et la génération de données.
- Intégration avec la vision par ordinateur: L'apprentissage profond révolutionne la vision par ordinateur, les réseaux neuronaux convolutifs devenant l'outil standard pour le traitement des images.
- Synergie avec le traitement du langage naturel: L'apprentissage profond est à l'origine du passage d'une approche statistique à une approche neuronale du traitement du langage naturel, les modèles de transformation dominant les dernières avancées.
- Intégration avec les technologies big dataL'apprentissage en profondeur bénéficie de l'infrastructure des big data, et les cadres informatiques distribués tels que Spark permettent l'apprentissage de modèles à grande échelle.
- Révélations sur la science du cerveauL'apprentissage profond s'inspire des neurosciences, les modèles actuels simplifient le cerveau humain et les neurosciences continuent d'inspirer de nouvelles architectures.
- Différences avec la théorie classique de l'optimisationL'optimisation par apprentissage profond de fonctions non convexes remet en question la théorie traditionnelle de l'optimisation et stimule le développement de nouveaux algorithmes.
Support matériel et logiciel pour l'apprentissage profond
- Accélération par le GPULa plate-forme CUDA de NVIDIA est devenue la norme dans l'industrie.
- puce dédiéeLes technologies de l'information et de la communication (TIC) : des unités de traitement tensoriel (TPU) et des réseaux de portes programmables (FPGA) personnalisés pour l'apprentissage profond afin d'améliorer l'efficacité énergétique et la rapidité.
- Plate-forme d'informatique en nuageAWS, Google Cloud et Azure fournissent des ressources informatiques élastiques qui démocratisent l'accès au deep learning et abaissent la barrière à l'entrée.
- Cadres d'apprentissage profondLes frameworks tels que TensorFlow, PyTorch et Keras simplifient le développement de modèles grâce à des API de haut niveau et des composants prédéfinis.
- communauté open sourceLes projets open source favorisent le partage des connaissances et la collaboration, les chercheurs et les développeurs contribuant au code, aux modèles et aux ensembles de données.
- Outils d'automatisationAutoML et Neural Network Architecture Search (NAS) automatisent la conception des modèles et réduisent l'intervention humaine.
- informatique de pointeLes cadres légers tels que TensorFlow Lite permettent de déployer des modèles sur des appareils mobiles et IoT pour l'inférence en temps réel.
- Outils de traitement des donnéesApache Hadoop et Spark : Apache Hadoop et Spark traitent des données à grande échelle pour préparer les données d'entrée pour l'apprentissage profond.
- Outils de visualisationLes outils tels que TensorBoard permettent de visualiser le processus d'apprentissage, de déboguer les modèles et de comprendre les représentations internes.
Impact social et considérations éthiques de l'apprentissage profond
L'utilisation généralisée de l'apprentissage profond a des implications sociales et des défis éthiques importants.
- Changements sur le marché du travailL'automatisation remplace certains emplois répétitifs et crée de nouveaux postes, comme celui d'ingénieur en IA. La main-d'œuvre doit être requalifiée.
- problème de protection de la vie privéeFuites de données sensibles : la technologie de reconnaissance faciale suscite des inquiétudes en matière de protection de la vie privée. Les réglementations telles que le GDPR tentent de protéger les données personnelles.
- Préjugés et discriminationLes modèles perpétuent les préjugés sociaux dans les données d'apprentissage, ce qui conduit à des décisions injustes. Les algorithmes d'audit et d'équité cherchent à les atténuer.
- risque de sécuritéLe terme "deep learning" désigne l'utilisation malveillante de l'apprentissage profond pour générer des contrefaçons profondes ou des attaques automatisées qui menacent la cybersécurité et la stabilité sociale.
- l'inégalité économiqueLe rapport de la Commission européenne sur les technologies de l'information et de la communication (TIC) : L'inégalité d'accès aux technologies exacerbe la fracture numérique et creuse le fossé entre les pays développés et les pays en voie de développement.
- Coûts environnementauxLa recherche en IA verte explore les moyens d'économiser l'énergie.
- Droit et responsabilitéLa complexité de l'attribution des responsabilités en cas d'accident impliquant des applications telles que la conduite autonome. Le cadre juridique doit être mis à jour pour l'ère de l'IA.
- Coopération et gouvernance mondialesL'IA : collaboration internationale en vue d'élaborer des normes éthiques pour l'IA afin de garantir que les développements technologiques sont compatibles avec les valeurs humaines. Des organisations telles que l'OCDE publient des principes en matière d'IA.
L'avenir de l'apprentissage profond
- apprentissage auto-superviséL'apprentissage auto-supervisé réduit la dépendance à l'égard des données étiquetées et utilise des données non étiquetées pour apprendre des représentations et améliorer l'efficacité des données.
- Recherche d'architecture neuronaleLes réseaux d'entreprise : Automatiser la conception de structures de réseaux, découvrir des architectures plus efficaces et réduire la charge de travail des concepteurs manuels.
- IA interprétableDéveloppement de méthodes permettant d'expliquer les décisions des modèles et d'améliorer la transparence et la confiance. Les mécanismes d'attention et les outils de visualisation progressent.
- Apprentissage fédéralL'apprentissage fédéré permet de former des modèles sur des appareils locaux, de protéger la confidentialité des données et de prendre en charge l'apprentissage distribué.
- Intégration de l'apprentissage amélioréL'apprentissage par renforcement profond pour résoudre des tâches plus complexes telles que le contrôle des robots et la gestion des ressources.
- l'apprentissage multimodalLes modèles traitent de plusieurs types de données (textes, images, sons) afin d'obtenir une compréhension plus complète.
- IA neurosymbolique: Combiner les réseaux neuronaux et le raisonnement symbolique pour améliorer le raisonnement et le bon sens.
- modèle bioinspiréLes réseaux neuronaux : développer de nouveaux types de réseaux, tels que les réseaux neuronaux à impulsions, qui s'appuient sur les structures cérébrales pour améliorer l'efficacité énergétique.
- Développement durableRecherche sur les modèles et algorithmes économes en énergie afin de réduire l'empreinte carbone et de promouvoir l'apprentissage en profondeur écologique.
Ressources d'apprentissage et parcours de démarrage pour l'apprentissage profond
Pour les débutants, de nombreuses ressources soutiennent l'étude et la pratique de l'apprentissage profond.
- programme en ligneCoursera, edX et Udacity proposent des cours spécialisés, tels que la spécialisation en apprentissage profond d'Andrew Ng, qui couvrent des sujets de base à avancés.
- Manuels et essaisDeep Learning par Ian Goodfellow et d'autres livres fournissent la base théorique. Lisez les derniers articles arXiv pour suivre les progrès.
- Plate-forme de pratiqueLes concours Kaggle et Google Colab offrent des GPU gratuits et une expérience pratique de la construction de modèles.
- Communauté et forumLe site web de la Commission européenne : Stack Overflow, r/MachineLearning de Reddit, et GitHub pour faciliter la discussion et la collaboration.
- projet open sourceLes projets d'entreprise : Participer à des projets open source pour contribuer au code, apprendre les meilleures pratiques et les applications pratiques.
- Programmes d'étudesL'université propose des programmes de master et de doctorat qui approfondissent la théorie et les applications de l'apprentissage profond.
- Séminaires et conférencesParticipez à des conférences telles que NeurIPS et ICML pour vous informer sur la recherche de pointe et vous mettre en relation avec des experts.
- Certifications industriellesLes entreprises telles que NVIDIA et Google proposent des programmes de certification qui valident les compétences afin d'améliorer l'employabilité.
- Parcours d'auto-apprentissageLes cours de formation à la programmation Python, l'apprentissage de NumPy et de Pandas, la progression vers des frameworks tels que PyTorch, et la réalisation de portefeuilles de projets.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes

Pas de commentaires...