L'avenir est là : un regard approfondi sur l'ère du "modèle en tant que produit".
Au cours des dernières années, les discussions sur la prochaine étape du développement de l'IA se sont multipliées : Agentisation ? Des capacités de raisonnement plus fortes ? Ou véritable fusion multimodale ? Toutes sortes de spéculations ont vu le jour, annonçant un nouveau changement dans le domaine de l'IA.
Maintenant, je pense qu'il est temps de donner un jugement clair :L'ère du "modèle en tant que produit" est arrivée. Il ne s'agit pas d'une simple tendance, mais d'un aperçu approfondi du paysage actuel du développement de l'IA.
Qu'il s'agisse de la pointe de la recherche universitaire ou de l'orientation actuelle du marché commercial, tous les signes pointent clairement dans cette direction transformatrice.
- La mise à l'échelle des modèles génériques connaît des goulets d'étranglement : Le modèle de développement "plus c'est gros, mieux c'est" du grand modèle générique révèle peu à peu ses limites. Il ne s'agit pas seulement d'un défi technique, mais aussi d'une question de rentabilité. Comme l'a révélé le débat sectoriel qui a suivi le GPT-4, la relation entre l'augmentation de la capacité des modèles et l'augmentation arithmétique des coûts n'est pas simplement linéaire, c'est un fossé en ciseaux qui se creuse. La puissance des modèles peut n'augmenter qu'à un rythme linéaire, mais le coût de la formation et de l'exploitation de ces mastodontes grimpe de manière exponentielle. Même les entreprises disposant d'autant de technologies et de ressources qu'OpenAI, sans parler des autres fournisseurs, peinent à trouver un modèle commercial capable de couvrir leur énorme investissement. Cela indique que l'époque où l'on comptait uniquement sur l'expansion de la taille des paramètres des modèles pour améliorer à l'infini les capacités de l'IA est peut-être révolue. Nous devons trouver des voies plus efficaces, plus rentables et plus durables pour le développement de l'IA.
- La formation à l'orientation s'est imposée comme une nouvelle force, dont les résultats dépassent largement les attentes : Contrairement à la lenteur du développement des modèles génériques, l'initiative de l"Formation à l'opinion publique". présente un potentiel étonnant. Ce paradigme de formation met l'accent sur le réglage fin et la formation de modèles pour des tâches et des scénarios d'application spécifiques. La convergence des techniques d'apprentissage par renforcement et de raisonnement a revigoré la formation ciblée. Au lieu de simplement "apprendre les données", nous voyons les modèles commencer à "apprendre la tâche". Il s'agit d'un saut qualitatif qui marque un changement dans la manière de concevoir l'IA. Qu'il s'agisse des performances stupéfiantes des petits modèles en mathématiques, de l'évolution des modèles de code, qui passent de générateurs de code à des gestionnaires autonomes de bases de code, ou de l'évolution de l'intelligence artificielle, les modèles de code sont de plus en plus populaires. Claude Les cas de jeux complexes avec un apport d'informations quasi nul sont la preuve de la puissance de l'entraînement à l'orientation. Cette voie de développement de modèles "petits mais fins" et "spécialisés mais forts" pourrait devenir le courant dominant des futures applications de l'IA.
- Les coûts d'inférence des modèles sont en chute libre : Le coût du raisonnement, autrefois considéré comme un "obstacle" à l'adoption de l'IA, a également été considérablement réduit. Grâce aux DeepSeek Grâce aux percées réalisées par des entreprises telles que AI en matière d'optimisation des modèles et d'accélération de l'inférence, le seuil de déploiement et d'application des modèles d'IA a été considérablement réduit. Les dernières recherches de DeepSeek montrent que la puissance de calcul GPU existante peut théoriquement accueillir des milliards de personnes dans le monde, chacune utilisant des modèles de pointe pour traiter 10 000 modèles d'IA par jour. jetons Les besoins des Cela signifie que l'arithmétique n'est plus un facteur clé limitant la popularité de l'IA et que l'ère de l'application à grande échelle de l'IA s'accélère. Pour les fournisseurs de modèles, s'appuyer sur le modèle commercial "paiement à l'utilisation" de la vente de jetons ne suffit manifestement pas pour exploiter pleinement la valeur des modèles d'IA. Ils doivent se tourner vers l'extrémité supérieure de la chaîne de valeur, par exemple en fournissant des services et des solutions de modèles plus verticaux et spécialisés.
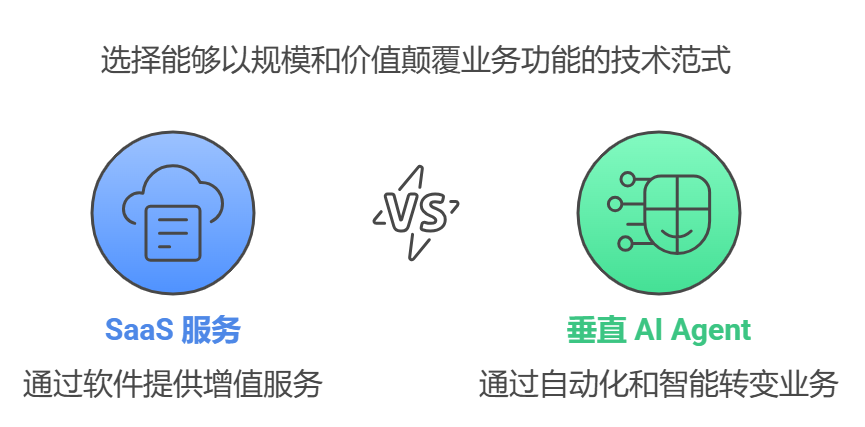
Tous ces signes indiquent que le développement de l'industrie de l'IA passe d'un "modèle général" à un nouveau paradigme de "modèle en tant que produit". Il ne s'agit pas seulement d'un ajustement de l'itinéraire technique, mais aussi d'un changement profond du modèle d'entreprise et du modèle industriel. La philosophie traditionnelle "les applications sont reines" pourrait devoir être revue. Pendant longtemps, les investisseurs et les entrepreneurs se sont concentrés sur la couche d'application de l'IA, estimant que l'innovation dans les applications était la clé de la commercialisation de l'IA. Toutefois, à l'ère du "modèle en tant que produit", la couche applicative pourrait être la première à être automatisée et bouleversée. À l'avenir, l'accent sera mis sur les modèles eux-mêmes, et celui qui disposera des modèles les plus avancés, les plus efficaces et les plus professionnels sera en mesure de prendre la tête de la compétition en matière d'IA.
La forme des modèles futurs : spécialisation, verticalisation, services
Au cours des dernières semaines, nous avons vu deux produits emblématiques émerger du paradigme du "modèle en tant que produit" : DeepResearch d'OpenAI et le programme de recherche sur le cancer de la prostate de l'Union européenne. Anthropique Ces deux produits reflètent les tendances de la nouvelle génération de modèles et préfigurent ce que seront les modèles du futur.
DeepResearch d'OpenAI, qui a suscité beaucoup d'attention depuis sa sortie, a été accompagné de nombreuses interprétations erronées. Beaucoup l'ont interprété comme une simple application "shell" de GPT-4, ou comme un outil d'amélioration de la recherche basé sur GPT-4. Mais c'est loin d'être le cas. OpenAI forme en fait un modèle entièrement nouveau spécifiquement pour les tâches de recherche et d'extraction d'informations. DeepResearch n'est pas un "flux de travail" qui s'appuie sur des moteurs de recherche externes ou des appels d'outils, mais un véritable "modèle de recherche". "Modèle linguistique de la recherche".Il dispose de capacités autonomes de recherche, de navigation, d'intégration d'informations et de génération de rapports de bout en bout, sans aucune intervention extérieure. Il dispose de capacités autonomes de recherche, de navigation, d'intégration d'informations et de génération de rapports de bout en bout, sans aucune intervention extérieure. Quiconque a utilisé DeepResearch peut clairement sentir la différence avec les LLM traditionnels ou les chatbots. Les rapports qu'il génère sont clairement structurés, rigoureusement argumentés et traçables de manière fiable, reflétant un professionnalisme et une profondeur qui dépassent de loin ceux des outils de recherche et des LLM traditionnels.
En revanche, d'autres produits sur le marché qui prétendent faire de la "recherche en profondeur", tels que Perplexité Il en va de même pour les fonctionnalités de Google et de Google, qui sont éclipsées par les leurs. Comme le souligne Hanchung Lee, ces produits sont encore essentiellement basés sur un modèle générique avec quelques ajustements simples et des superpositions de fonctionnalités, et manquent d'optimisation profonde et de conception systématique pour la tâche de recherche. L'émergence de DeepResearch marque l'avènement du concept de "modèle en tant que produit", et nous montre également l'orientation du développement de modèles spécialisés et verticalisés.
Anthropic poursuit également activement une stratégie de "modèle en tant que produit" et a fourni des informations sur les modèles d'agents. Ils ont publié un article en décembre de l'année dernièrerapport de rechercheAnthropic a redéfini le modèle d'agent. Selon Anthropic, un vrai modèle d'agent doit avoir "Autonomiequi est capable d'accomplir la tâche cible de manière autonome, et non comme un simple lien dans le flux de travail. Comme DeepResearch, Anthropic insiste sur le fait que les modèles d'agents doivent être "En interne Compléter l'ensemble du processus d'exécution des tâches, y compris la planification dynamique du flux de tâches, la sélection et l'invocation autonomes d'outils, etc., plutôt que de s'appuyer sur des chemins de code prédéfinis et une orchestration externe.
Un grand nombre de startups spécialisées dans les agents émergent aujourd'hui sur le marché, mais la plupart des "agents" qu'elles construisent sont encore bloqués dans la catégorie des "agents". "Workflow" (flux de travail) Niveau. Ces "agents" sont essentiellement une série de flux de code prédéfinis qui relient les LLM et divers outils pour exécuter des tâches en un nombre fixe d'étapes. Cette approche "pseudo-agent", bien qu'elle puisse avoir une certaine valeur dans certains secteurs verticaux, est encore loin de l'approche "agent réel" définie par Anthropic et OpenAI. Les systèmes véritablement autonomes doivent être remodelés et faire l'objet d'innovations au niveau du modèle afin de réaliser un saut qualitatif.
La sortie de Anthropic Claude 3.7 est une nouvelle preuve de la tendance "modèle en tant que produit". Claude 3.7 est un modèle profondément optimisé pour les scénarios de codes complexes. Claude 3.7 démontre d'excellentes performances dans la génération de code, la compréhension de code et l'édition de code. Il est particulièrement remarquable que même un modèle comme Devin Un tel flux de travail "programmateur d'IA" très complexe et intelligent, alimenté par Claude 3.7, a également été en mesure d'obtenir des améliorations significatives dans les points de référence SWE. Cela suggère que c'est la puissance du modèle lui-même qui est la clé de la création d'applications de qualité. Au lieu de consacrer beaucoup d'efforts à la conception de flux de travail complexes et d'outils externes, les ressources devraient être investies dans le développement et l'optimisation du modèle lui-même.
L'équipe de Pleias à RAG L'exploration du domaine de la génération assistée par récupération (RAG) reflète également l'idée du "modèle en tant que produit". Les systèmes RAG traditionnels sont généralement composés de multiples flux de travail indépendants et couplés, tels que l'acheminement des données, le découpage du texte, la réorganisation des résultats, la compréhension des requêtes, l'expansion des requêtes, la fusion des contextes, l'optimisation de la recherche, etc. Le manque d'intégration organique entre ces liens entraîne une grande vulnérabilité du système et des coûts élevés de maintenance et d'optimisation. L'équipe de Pleias tente d'utiliser les dernières techniques de formation pour intégrer les différents aspects du système RAG. "ModélisationLe RAG comporte deux modèles principaux : l'un pour le prétraitement des données et la construction de la base de connaissances, et l'autre pour la recherche d'informations, la génération de contenu et la production de rapports. Ces deux modèles collaborent l'un avec l'autre pour mener à bien l'ensemble des tâches du RAG. Cette solution, qui nécessite une nouvelle conception de l'architecture du modèle, un pipeline de données synthétiques affiné et une fonction de récompense d'apprentissage par renforcement personnalisée, constitue une véritable innovation technologique et une percée en matière de recherche. La "modélisation" du système RAG permet de simplifier considérablement l'architecture du système, d'en améliorer les performances et la stabilité, de réduire les coûts de déploiement et de maintenance et de réaliser l'application à grande échelle de la technologie RAG.
En bref, le concept de base du "modèle en tant que produit" est le suivant "Déplacer la complexité. Les problèmes complexes qui, à l'origine, doivent être résolus au niveau de l'application sont traités et assimilés à l'avance au niveau du modèle par le biais de la formation au modèle. Le modèle apprend et s'adapte à divers scénarios complexes et situations extrêmes au cours de la phase de formation, ce qui rend le déploiement et l'application du modèle plus simples et plus efficaces. À l'avenir, la valeur fondamentale des produits d'IA se reflétera davantage dans le modèle lui-même que dans des fonctions fantaisistes et des flux de travail complexes au niveau de l'application. Les formateurs de modèles deviendront les acteurs dominants de la création et de la capture de valeur. L'objectif d'Anthropic Claude est de perturber et de remplacer les systèmes de "pseudo-agents" actuels basés sur le flux de travail, tels que le cadre d'agent sous-jacent fourni par LlamaIndex. L'objectif est de créer des applications d'IA plus intelligentes, plus autonomes et plus faciles à utiliser grâce à des modèles plus puissants.

sera remplacée par une architecture de modélisation plus avancée décrite ci-dessous :

Survivre à l'ère du "modèle en tant que produit" : développer son propre modèle ou être avalé par lui ?
Là encore, le placement stratégique des grands laboratoires d'IA n'est pas une "opération secrète", mais est clair et ouvert. Si, à certains égards, leurs stratégies peuvent sembler peu transparentes, leurs intentions fondamentales sont claires : Ils partiront de la couche modèle et pénétreront vers le haut jusqu'à la couche application pour construire des produits et des services d'IA de bout en bout et chercheront à dominer la chaîne de valeur. Les implications commerciales de cette tendance sont considérables. Naveen Rao, vice-président de Gen AI chez Databricks, met le doigt sur le problème :
Au cours des deux ou trois prochaines années, tous les fournisseurs de modèles d'IA à source fermée cesseront progressivement de vendre directement des interfaces API. Seuls les modèles à source ouverte continueront à fournir des services par l'intermédiaire d'API. L'objectif des fournisseurs de modèles à source fermée est de créer des capacités d'IA non génériques et compétitives uniques, et pour fournir ces capacités, ils doivent créer une expérience utilisateur et une interface d'application ultimes. Le produit d'IA du futur ne sera plus seulement le modèle lui-même, mais une application complète intégrant le modèle, l'interface de l'application et des fonctionnalités spécifiques.
Cela signifie que la période de lune de miel de la "division du travail" entre les fournisseurs de modèles et les développeurs d'applications a pris fin. Les développeurs d'applications, en particulier les entreprises "enveloppantes" qui s'appuient sur des modèles d'API tiers pour créer des applications, sont confrontés à des défis sans précédent pour leur survie. À l'avenir, le paysage concurrentiel de l'industrie de l'IA pourrait évoluer dans les directions suivantes :
- Les fournisseurs de modèles développent leurs propres applications pour conquérir des parts de marché : Code Claude et DeepSearch ont montré que les fournisseurs de modèles étendent activement leurs domaines d'application. DeepSearch n'a pas d'interface API ouverte, mais est intégré dans le service d'abonnement premium d'OpenAI en tant que fonctionnalité de base qui améliore la valeur du service. Claude Code est un outil d'intégration léger qui permet aux développeurs d'utiliser les modèles Claude 3.7 directement dans un éditeur de code. Ces mesures indiquent que les fournisseurs de modèles accélèrent la construction de leurs propres écosystèmes d'applications afin de fournir des services directement aux utilisateurs et de s'approprier des parts de marché. Il convient de noter que certaines applications, telles que Cursor, ont connu une dégradation des performances et une désaffection des utilisateurs lorsqu'elles ont été intégrées au modèle Claude 3.7. Cela confirme l'idée que le modèle est le produit : Un véritable agent d'IA cherche à maximiser les capacités du modèle plutôt qu'à s'adapter aux flux de travail existants.
- Application Wrapper Transformation, Focus on Model Self-Research : Face à la "descente aux enfers" des fournisseurs de modèles, certains fournisseurs d'applications de tête ont commencé à chercher activement à se transformer, en essayant de créer leurs propres capacités de formation aux modèles. Malgré leur départ tardif et leur faiblesse relative en matière de formation aux modèles, ces entreprises préparent activement le terrain. Cursor, par exemple, met l'accent sur la valeur de ses modèles d'autocomplétion de petits codes ; WindSurf dispose d'un modèle de code interne à faible coût, Codium ; Perplexity s'appuie depuis longtemps sur un classificateur maison pour l'acheminement du trafic et a commencé à former sa propre variante de DeepSeek pour l'amélioration de la recherche. Ces évolutions montrent que les wrappers d'applications ont compris qu'il était difficile de s'appuyer uniquement sur le modèle "appel d'API" pour s'imposer dans la future concurrence, et qu'ils devaient maîtriser certaines capacités d'auto-développement de modèles afin de rester compétitifs.
- L'innovation en matière d'interface utilisateur peut être la clé de la percée : Pour le grand nombre de petits et moyens wrappers d'applications, la marge de survie sera encore plus étroite à l'avenir. Si les grands laboratoires modèles réduisent leurs services API de manière générale, ces petits wrappers pourraient être contraints de se tourner vers des fournisseurs de services de raisonnement tiers plus neutres. Avec la convergence des capacités des modèles, l'innovation en matière d'interface utilisateur et d'expérience utilisateur pourrait devenir la clé de la réussite pour les petits conditionneurs. La valeur de l'interface utilisateur a longtemps été gravement sous-estimée dans le domaine de l'IA. À mesure que les modèles génériques deviennent plus puissants et que les processus de déploiement et d'application des modèles sont de plus en plus rationalisés, l'interface utilisateur devient de plus en plus importante.Une excellente interface utilisateur sera le facteur clé pour améliorer la compétitivité du produit et attirer les utilisateurs. En particulier dans les scénarios d'application tels que le RAG, la capacité du modèle peut ne plus être le facteur décisif, et la facilité d'utilisation, l'interactivité et l'expérience de l'utilisateur deviendront plus importantes.
En bref, pour la plupart des concepteurs d'applications, l'avenir se résume à un dilemme "soit l'un, soit l'autre" : Soit vous serez transformé en formateur de modèles (Training), soit vous finirez par être avalé par le propriétaire du modèle (Being Trained On). Actuellement, tout le travail effectué par ces applications est devenu, d'une certaine manière, une "étude de marché gratuite" et un "étiquetage gratuit des données" pour les grands laboratoires de modélisation. En effet, toutes les données relatives à l'interaction avec l'utilisateur et le retour d'information parviennent en fin de compte aux fournisseurs de modèles pour les aider à améliorer leurs modèles, à optimiser leurs produits et à renforcer leur position sur le marché.
L'orientation future des applications wrappers dépend également dans une large mesure des attitudes et des perceptions des investisseurs. Il est inquiétant de constater que le climat d'investissement actuel semble quelque peu "biaisé" à l'encontre de l'espace de formation des modèles. De nombreux investisseurs s'accrochent encore au concept traditionnel de "l'application est reine" et ne reconnaissent pas la valeur et le potentiel de la formation de modèles. Cette "inadéquation" des investissements risque d'entraver le développement sain de la technologie de l'IA, et même de faire prendre du retard à l'industrie occidentale de l'IA dans la concurrence future. Par conséquent, certaines sociétés de développement d'applications pourraient également devoir "cacher" leurs efforts en matière de formation de modèles afin de ne pas être mal interprétées par les investisseurs. Les miniatures de Cursor et Codium, par exemple, n'ont pas encore bénéficié d'une publicité et d'une promotion adéquates. Cette orientation de l'investissement, qui consiste à "se concentrer sur les applications et non sur les modèles", doit susciter une réflexion approfondie et une grande vigilance dans l'industrie.
L'apprentissage par renforcement sous-estimé : la clé de l'avenir compétitif de l'IA
Dans l'espace d'investissement actuel de l'IA, il y a une prévalence de l'investissement dans les technologies de l'information et de la communication. "L'apprentissage par renforcement n'a pas été tarifé. Le phénomène. Ce phénomène s'explique par le fait que la communauté des investisseurs privilégie la tendance au développement de la technologie de l'IA et néglige l'importance stratégique de la technologie de l'apprentissage par renforcement.
Les décisions d'investissement des sociétés de capital-risque dans l'IA reposent généralement sur plusieurs hypothèses :
- La couche d'application est la poche de valeur, la couche de modèle n'est que l'infrastructure : Les investisseurs estiment généralement que la valeur réelle de l'IA se reflète dans la couche applicative, et que l'innovation en matière d'applications est la clé pour perturber le marché existant. La couche modèle n'est qu'une infrastructure qui fournit des interfaces API et n'a pas de compétitivité de base.
- Les prix des modèles d'API continueront à baisser et les concepteurs d'applications continueront à en bénéficier : Les investisseurs s'attendent à ce que les fournisseurs de modèles continuent à réduire le prix des appels d'API afin de gagner des parts de marché, stimulant ainsi la rentabilité des wrappers d'applications.
- L'API du modèle à source fermée est suffisante pour toutes les applications : Les investisseurs estiment que les applications construites sur des modèles d'API à source fermée peuvent répondre aux besoins d'un large éventail de scénarios, même dans des secteurs sensibles où les exigences en matière de sécurité des données et d'autonomie sont élevées.
- La formation au modèle est un investissement important, un cycle long, un risque élevé, il est préférable d'acheter l'API directement : Les investisseurs pensent généralement que la mise en place de capacités de formation aux modèles est un investissement "ingrat". La formation aux modèles nécessite d'énormes capitaux, des cycles longs et des seuils techniques élevés, et le risque est beaucoup plus élevé que l'achat direct d'API de modèles et le développement rapide d'applications.
Cependant, ces hypothèses deviennent de plus en plus insoutenables dans le contexte de l'ère du "modèle en tant que produit". Je crains que si la communauté des investisseurs continue à s'accrocher à ces notions dépassées, elle risque de manquer des opportunités stratégiques pour le développement de l'IA et même de conduire à une mauvaise allocation des ressources du marché. Le boom actuel des investissements dans l'IA pourrait se transformer en un "pari risqué", une "défaillance du marché qui ne parvient pas à évaluer avec précision les derniers développements technologiques (en particulier l'apprentissage par renforcement)".
Les fonds de capital-risque (VC), qui sont censés chercher à investir dans un portefeuille de produits et de services, ne sont pas des fonds de capital-risque. "Non corréléL'objectif des sociétés de capital-risque n'est pas de battre l'indice S&P500. L'objectif des sociétés de capital-risque n'est pas de battre l'indice S&P500, mais de constituer un portefeuille diversifié qui réduit le risque global et garantit que certains investissements resteront rentables pendant les cycles baissiers. La formation au modèle, qui correspond au profil de l'investissement "non corrélé". Dans le contexte des risques de récession dans les principales économies occidentales, le domaine de la formation de modèles d'IA, qui recèle un énorme potentiel d'innovation et de croissance, est faiblement corrélé aux cycles macroéconomiques. Cependant, les entreprises de formation par le modèle sont généralement confrontées à des difficultés de financement, ce qui est contraire à la logique essentielle du capital-risque. Prime Intellect est l'une des rares startups occidentales de formation de modèles d'IA ayant le potentiel de devenir un laboratoire d'IA de pointe. Malgré ses avancées technologiques, notamment la formation du premier LLM décentralisé, son niveau de financement est comparable à celui d'une société d'application ordinaire. Ce phénomène de la "mauvaise monnaie qui chasse la bonne" donne à réfléchir.
À l'exception de quelques grands laboratoires, l'écosystème actuel de formation des modèles d'IA reste très fragile et marginal. Au niveau mondial, il n'y a qu'une poignée d'entreprises innovantes qui se concentrent sur la formation des mannequins. Prime Intellect, Moondream, Arcee, Nous, Pleias, Jina, l'équipe de préformation HuggingFace (qui est très petite) et d'autres constituent la quasi-totalité de l'espace de formation de modèles d'IA open source. Avec une poignée d'institutions universitaires telles qu'Allen AI, EleutherAI, etc., ils construisent et maintiennent les pierres angulaires de l'infrastructure actuelle de formation à l'IA open source. En Europe, j'ai appris que 7 à 8 projets LLM prévoient d'entraîner des modèles basés sur le corpus Common Corpus et les outils de pré-entraînement développés par l'équipe Pleias. La communauté florissante des logiciels libres a permis de compenser en partie le manque d'investissements commerciaux, mais elle a également eu du mal à s'attaquer à la racine des problèmes auxquels est confronté l'écosystème de la formation au maniement des modèles.
OpenAI semble également très consciente de l'importance du "RL vertical". Récemment, il a été rapporté que les dirigeants d'OpenAI ont exprimé leur mécontentement à l'égard de la scène des start-ups de la Silicon Valley, qui est "peu axée sur la NR et très axée sur les applications". On peut supposer que ce message est venu de Sam Altman lui-même et qu'il pourrait se refléter dans le prochain YC Startup Camp. Cela signale un changement possible dans la stratégie de collaboration d'OpenAI. À l'avenir, les partenaires d'OpenAI pourraient ne plus être de simples clients d'API, mais des "co-contractants" impliqués dans les premières étapes de formation des modèles. La formation des modèles, qui passera des coulisses à l'avant-scène, deviendra un aspect essentiel de la compétition en matière d'IA.
L'ère du "modèle en tant que produit" implique un changement de paradigme dans l'innovation en matière d'IA. L'ère du combat solitaire est révolue, la coopération ouverte et l'innovation collaborative deviendront le courant dominant. Les domaines de la recherche et du code sont les premiers à réaliser le "modèle en tant que produit", en grande partie en raison de la maturité relative des scénarios d'application dans ces deux domaines, de la demande claire du marché et de la voie technologique claire, qui permet de "cueillir rapidement les fruits à portée de main". Comme Curseur De tels produits innovants peuvent être rapidement mis au point et commercialisés en l'espace de quelques mois. Toutefois, des scénarios d'application de l'IA à plus forte valeur ajoutée, tels que l'amélioration intelligente des systèmes basés sur des règles, en sont encore à un stade précoce d'exploration, avec d'énormes défis techniques et une demande incertaine du marché, ce qui rend difficile la réalisation de percées à court, moyen et rapide. Il s'agit de domaines qui requièrent de petites équipes ayant une formation interdisciplinaire et un degré élevé de concentration pour des investissements de R&D à long terme et en profondeur. Ces "petites et belles" équipes d'innovation pourraient devenir une force importante dans l'industrie de l'IA à l'avenir, et pourraient être acquises par de grandes entreprises technologiques pour réaliser leur valeur après avoir achevé leur accumulation de technologies précoces. Un modèle de collaboration similaire pourrait voir le jour dans le domaine de l'interface utilisateur. Certaines entreprises axées sur l'innovation en matière d'interface utilisateur pourraient créer des produits d'IA différenciés et compétitifs en établissant des partenariats stratégiques avec de grands laboratoires de modélisation afin d'obtenir un accès API exclusif à des modèles spécialisés à source fermée.
La structure stratégique de DeepSeek est sans aucun doute plus prospective et plus ambitieuse dans la tendance "le modèle est le produit". L'objectif de DeepSeek n'est pas seulement le "modèle en tant que produit", mais le "modèle en tant que couche d'infrastructure commune". À l'instar d'OpenAI et d'Anthropic, le fondateur de DeepSeek, Wenfeng Lian, a publiquement exposé sa vision de DeepSeek :
Nous pensons que la phase actuelle est Une explosion de l'innovation technologique, pas une explosion des applicationsLa première étape consiste à s'assurer que l'on dispose de la meilleure solution possible au problème. Ce n'est que lorsqu'un écosystème complet d'IA en amont et en aval de l'industrie est établi que DeepSeek n'a pas à s'occuper de l'application elle-même. Bien entendu, si nécessaire, DeepSeek peut également s'occuper des applications, mais ce n'est pas une priorité. La stratégie fondamentale de DeepSeek a toujours été d'adhérer à l'innovation technologique et de construire une puissante plateforme d'infrastructure commune d'IA.
À l'ère du "modèle en tant que produit", limiter notre attention à la couche d'application équivaut à "Utiliser les généraux de la dernière génération de guerre pour commander la prochaine génération de guerre.Ce qui est inquiétant, c'est que l'industrie occidentale de l'IA semble toujours plongée dans l'ancienne mentalité de "l'application est reine". Ce qui est inquiétant, c'est que l'industrie occidentale de l'IA semble toujours plongée dans l'ancienne mentalité de "l'application est reine" et manque de connaissances et de préparation suffisantes pour faire face aux nouvelles tendances du développement de l'IA. Beaucoup n'ont peut-être pas encore réalisé que la "guerre" dans le domaine de l'IA est discrètement entrée dans une nouvelle phase. Celui qui sera le premier à adopter le nouveau paradigme du "modèle en tant que produit" aura une longueur d'avance dans la future compétition de l'IA.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Postes connexes


Pas de commentaires...