Déploiement local de Vanna : Conversions Text2SQL efficaces et faciles
Vanna est un framework open source Text2SQL très apprécié qui transforme le langage naturel en requêtes SQL. Cet article explique comment déployer Vanna localement et le combiner avec une base de données MySQL et l'application Deepseek Les modèles sont configurés et testés pour vous aider à utiliser rapidement l'outil. Toutes les opérations sont basées sur des tests en situation réelle afin de s'assurer que les étapes sont claires et réalisables.
Configuration de l'environnement Python
Pour faire fonctionner Vanna, vous avez d'abord besoin d'un environnement Python stable. Voici un guide étape par étape pour configurer Vanna, en utilisant Miniconda3 comme exemple.
Installation de Miniconda3
- Télécharger le paquet d'installation :
wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh - Exécuter le script d'installation :
sh Miniconda3-latest-Linux-x86_64.sh - Configurer les variables d'environnement :
vim /etc/profileAjoutez-le au dossier :
export PATH="/data/apps/miniconda3/bin:$PATH"Sauvegarder et actualiser la configuration :
source /etc/profile - Si vous devez désinstaller, vous pouvez simplement supprimer le répertoire d'installation :
rm -rf /data/apps/miniconda3/
Créer un environnement virtuel
- Créer un environnement Python 3.10 :
conda create -n test python=3.10 - Activer l'environnement (doit prendre effet sur un nouveau terminal ou après un redémarrage) :
conda activate test - Autres commandes courantes :
- Environnement de sortie :
conda deactivate - Voir les informations sur l'environnement :
conda info --env
- Environnement de sortie :
Après avoir effectué les étapes ci-dessus, vous disposez d'un environnement virtuel Python autonome qui prépare le terrain pour le déploiement de Vanna.
Déploiement et configuration de Vanna
L'environnement Python étant prêt, passons à la configuration de base de Vanna. Les opérations suivantes se réfèrent à la documentation officielle (https://vanna.ai/docs/) et utilisent la base de données MySQL comme exemple.
Configuration de la connexion à la base de données
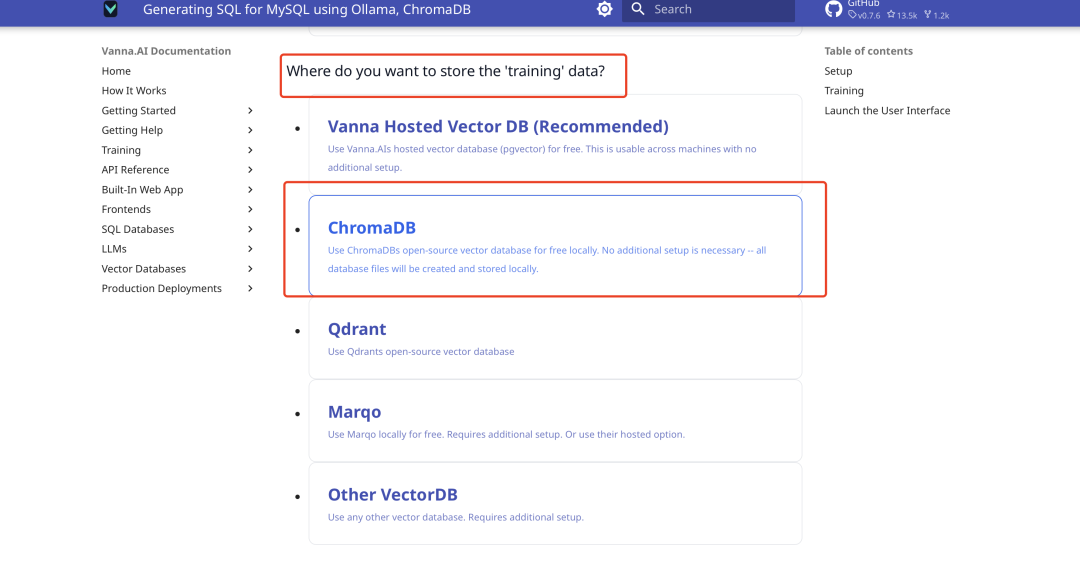
Tout d'abord, assurez-vous que vous pouvez vous connecter correctement à la base de données avec votre compte MySQL, votre mot de passe et votre port. Après avoir testé une connexion réussie, ouvrez la page de configuration de MySQL dans la documentation officielle de Vanna (sélectionnez MySQL dans la barre de menu de gauche). La page affichera un exemple de code de connexion, comme illustré ci-dessous :
En fonction des informations de votre base de données, ajustez les paramètres dans le code (par exemple, hôte, utilisateur, mot de passe, etc.) pour vous assurer que Vanna se connecte sans problème.
Choisir un modèle linguistique
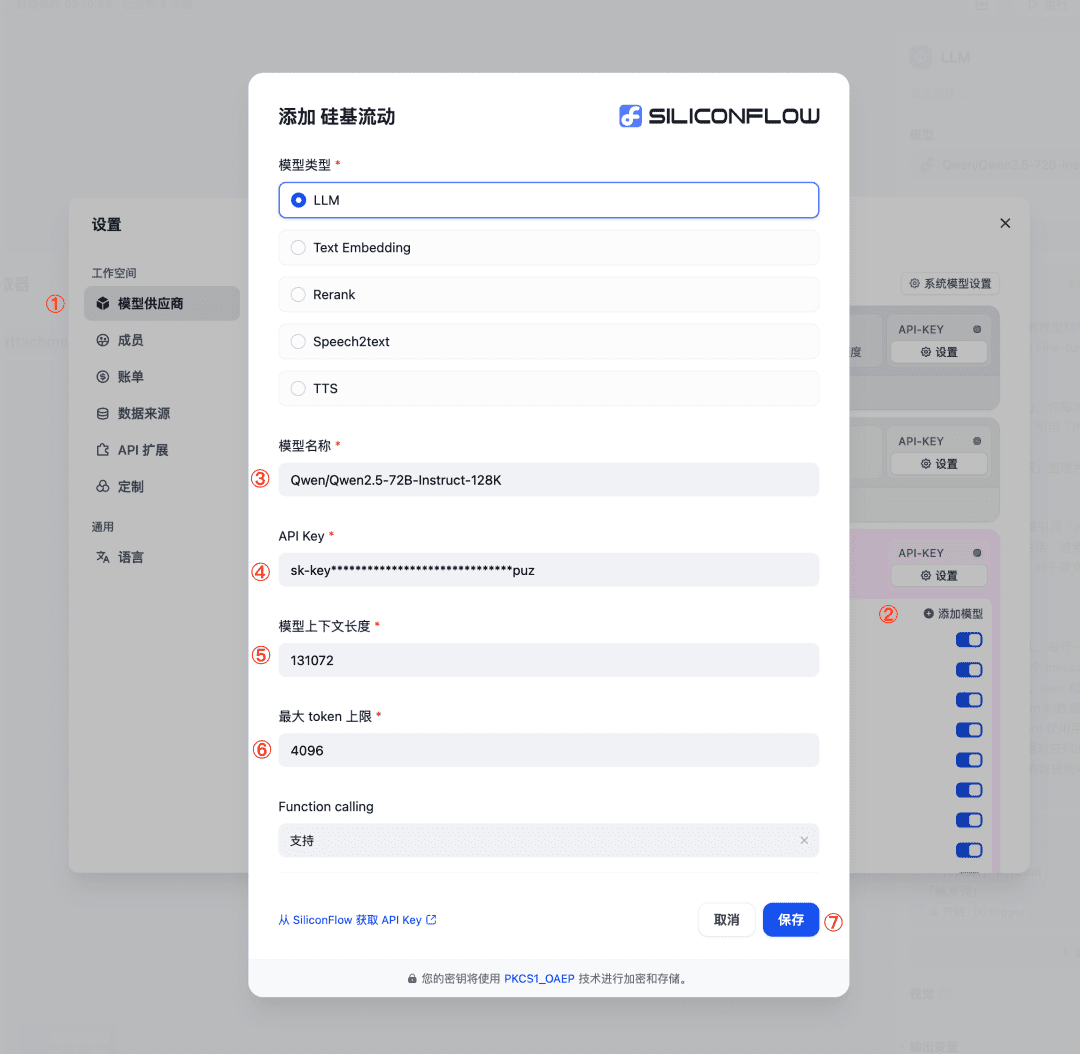
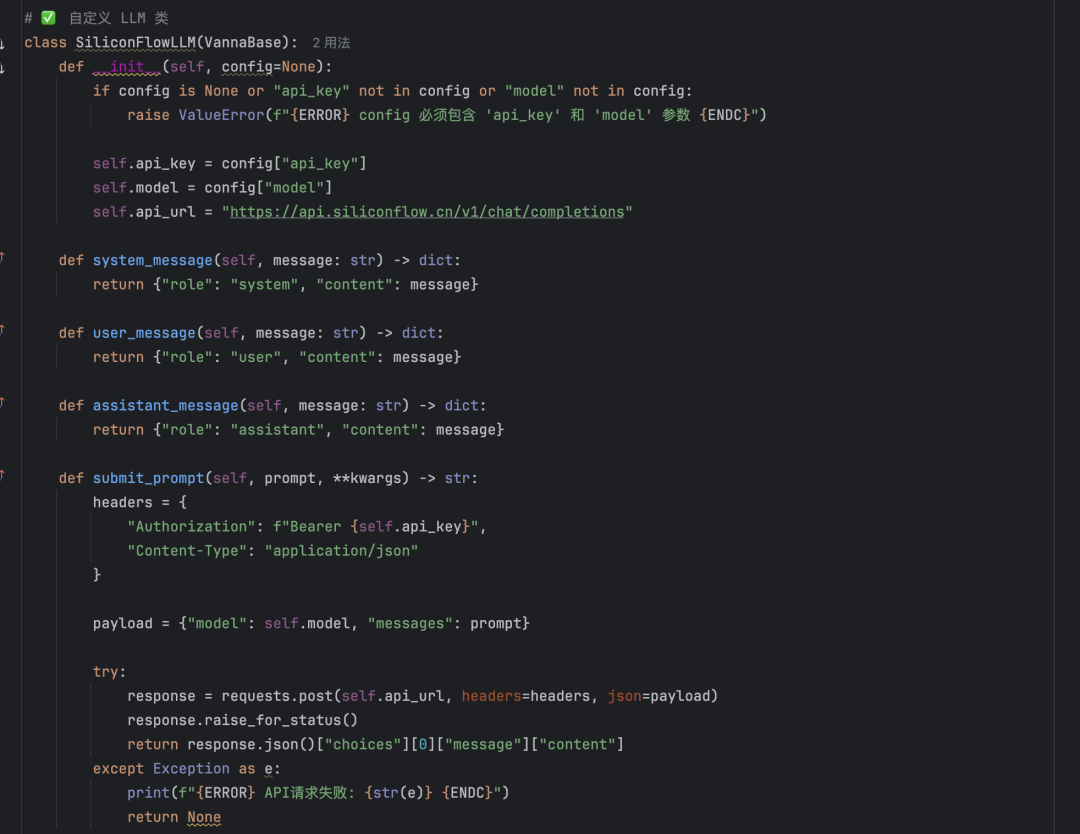
Vanna prend en charge une variété de grands modèles linguistiques (LLM). La page officielle invite à sélectionner un modèle, par exemple Ollama ou des appels d'API. Le modèle Deepseek pour les flux basés sur le silicium est illustré ici à titre d'exemple.
- L'expérience d'OllamaLes tentatives de déploiement du modèle quantifié Deepseek-7b ont donné des résultats médiocres et il est recommandé de ne pas retenir cette option.
- API DeepseekL'appel de modèles Deepseek via des flux in silico est plus performant. Notez cependant que des classes LLM personnalisées sont nécessaires pour utiliser des modèles qui ne sont pas officiellement pris en charge. Voir le projet open source Vanna Mistral (mistral.py), créez une classe adaptée à Deepseek en conséquence.
L'écran de configuration est le suivant :
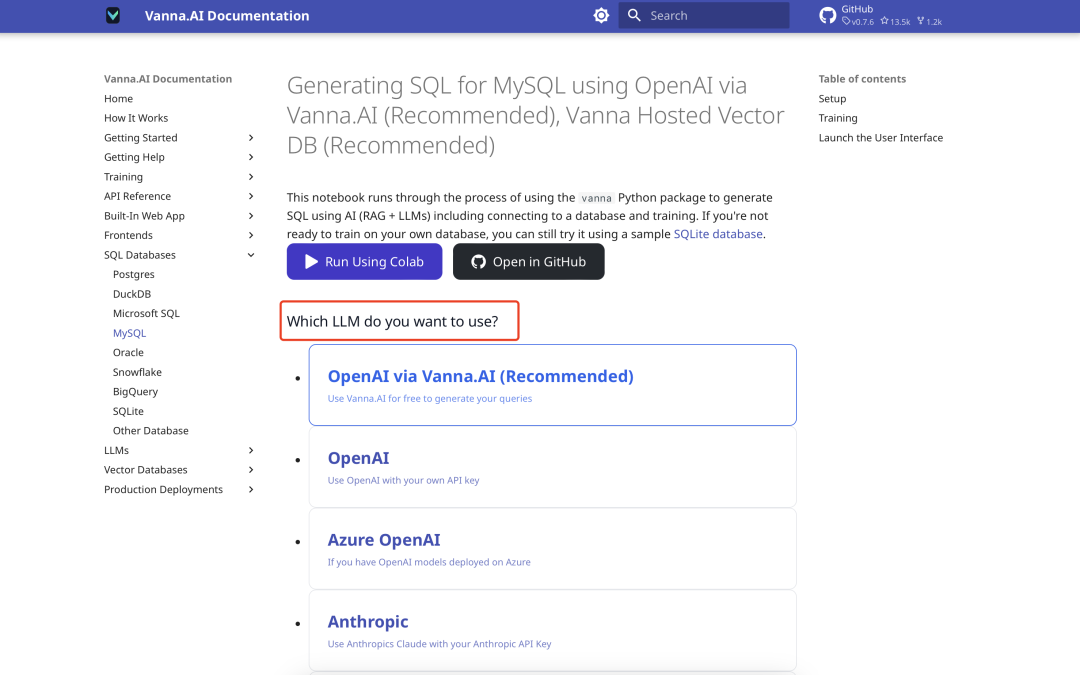
Configuration de la base de données vectorielle
Vanna intègre par défaut ChromaDB comme petite base de données vectorielle, aucune installation supplémentaire n'est nécessaire. La documentation officielle génère du code en fonction de votre choix, comme indiqué ci-dessous :
Installation des dépendances et préparation du code
- Installer Vanna et ses dépendances dans un environnement virtuel activé :
pip install vanna - Créer un
.pyet copiez-y le code officiel généré. Vous trouverez ci-dessous un exemple de code pour adapter MySQL et Deepseek (vous devez ajuster les paramètres en fonction de la situation réelle) :from vanna.remote import VannaDefault vn = VannaDefault(model='deepseek', api_key='your_api_key') vn.connect_to_mysql(host='localhost', dbname='test_db', user='root', password='your_password', port=3306)
formation aux données
Vanna prend en charge trois types de données de formation : les instructions SQL, la documentation produit et les descriptions de la structure des tables de la base de données. Nous recommandons ici d'utiliser la description de la structure des tables, dont l'effet est plus intuitif. Les étapes de la formation sont les suivantes :
- Préparer les données de la structure de la table (par exemple, le fichier DDL).
- Utilisez le code de formation officiellement fourni :
vn.train(ddl="CREATE TABLE employees (id INT, name VARCHAR(255), salary INT)") - Le processus de formation est présenté ci-dessous :
D'autres résultats de formation sont présentés :
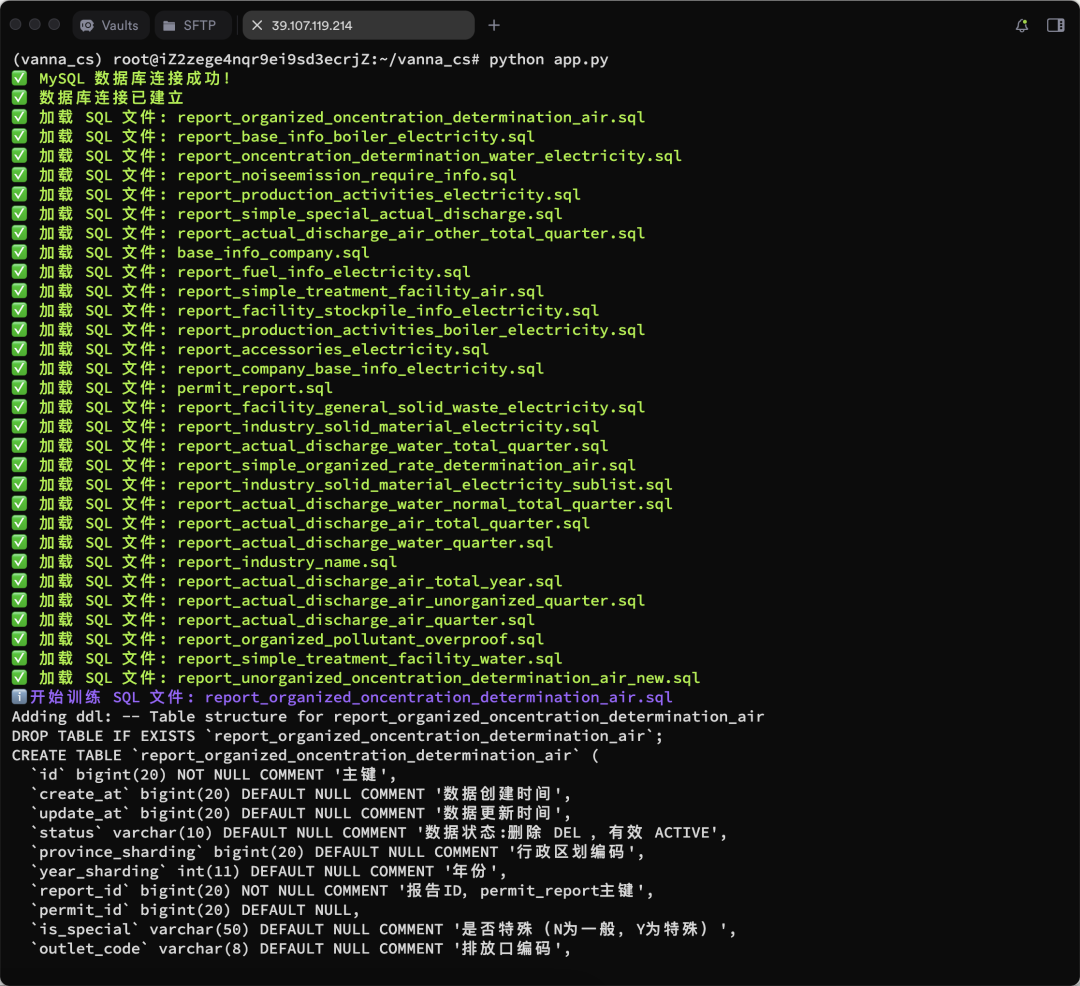
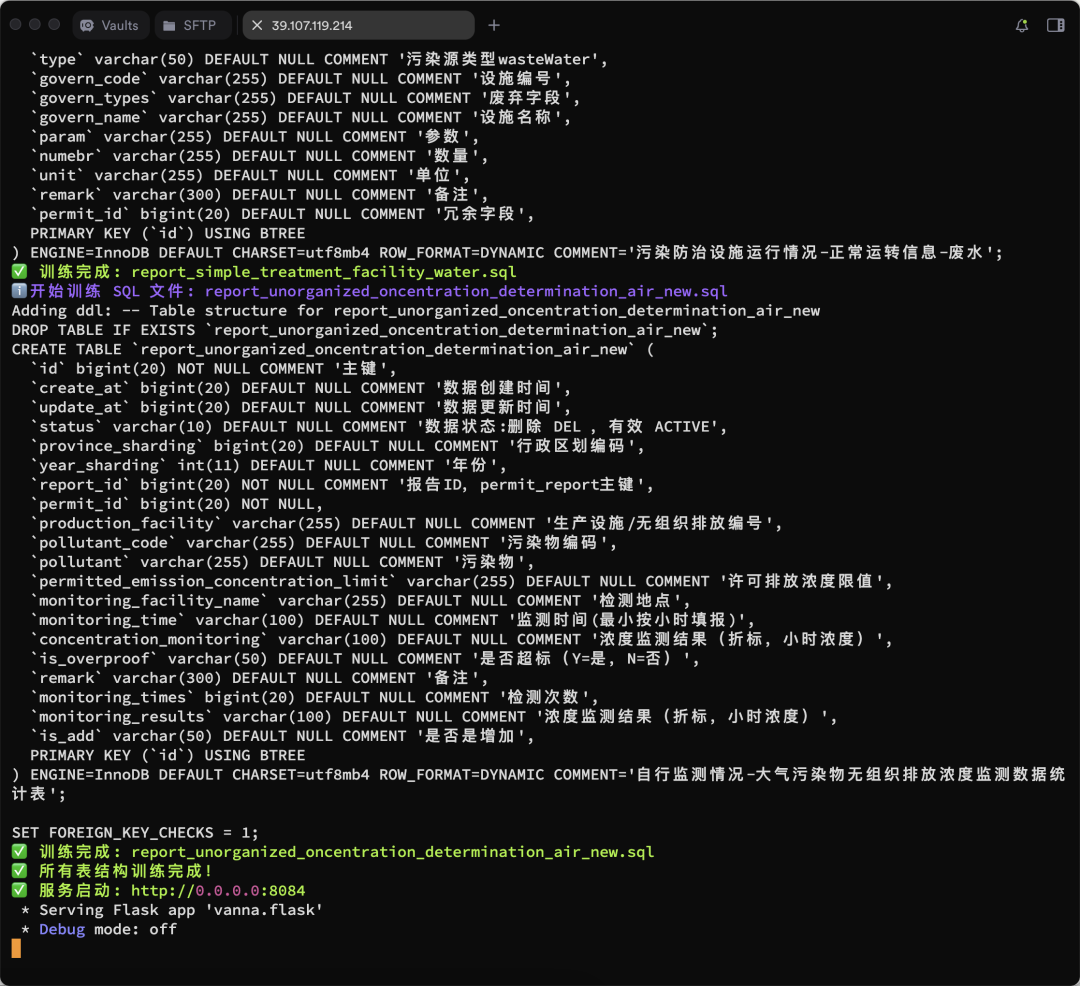
Exécution de l'interface Web
Une fois la formation terminée, exécutez le code API Flask suivant pour lancer l'interface Web de Vanna :
from vanna.flask import VannaFlaskApp
app = VannaFlaskApp(vn)
app.run()
Accès à l'adresse locale (généralement http://127.0.0.1:5000), vous pouvez effectuer des requêtes SQL via l'interface.
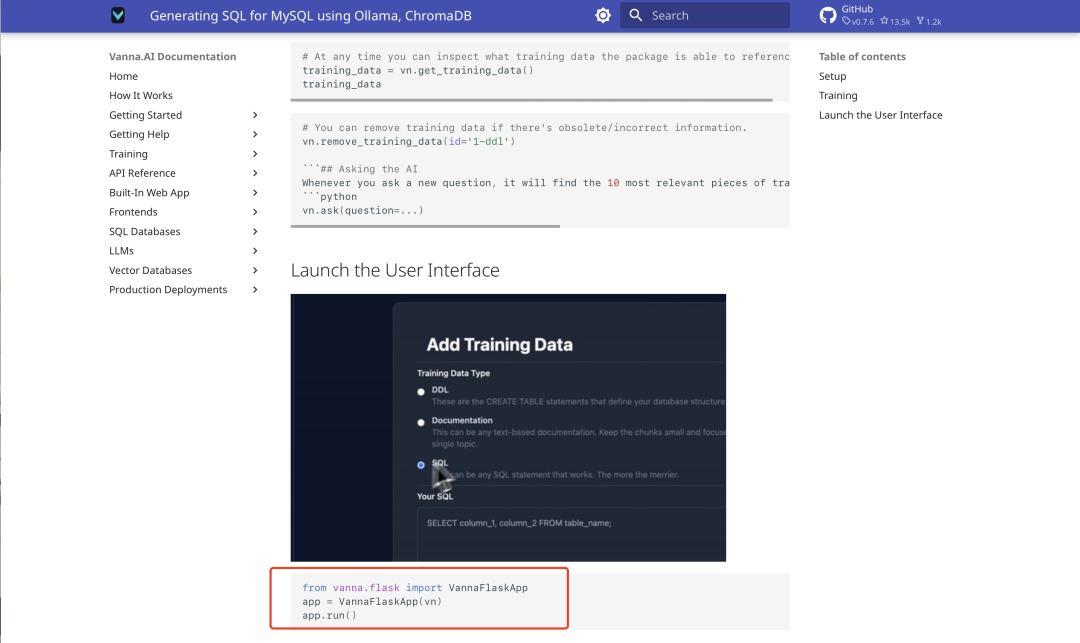
Affichage de l'effet de la demande de renseignements
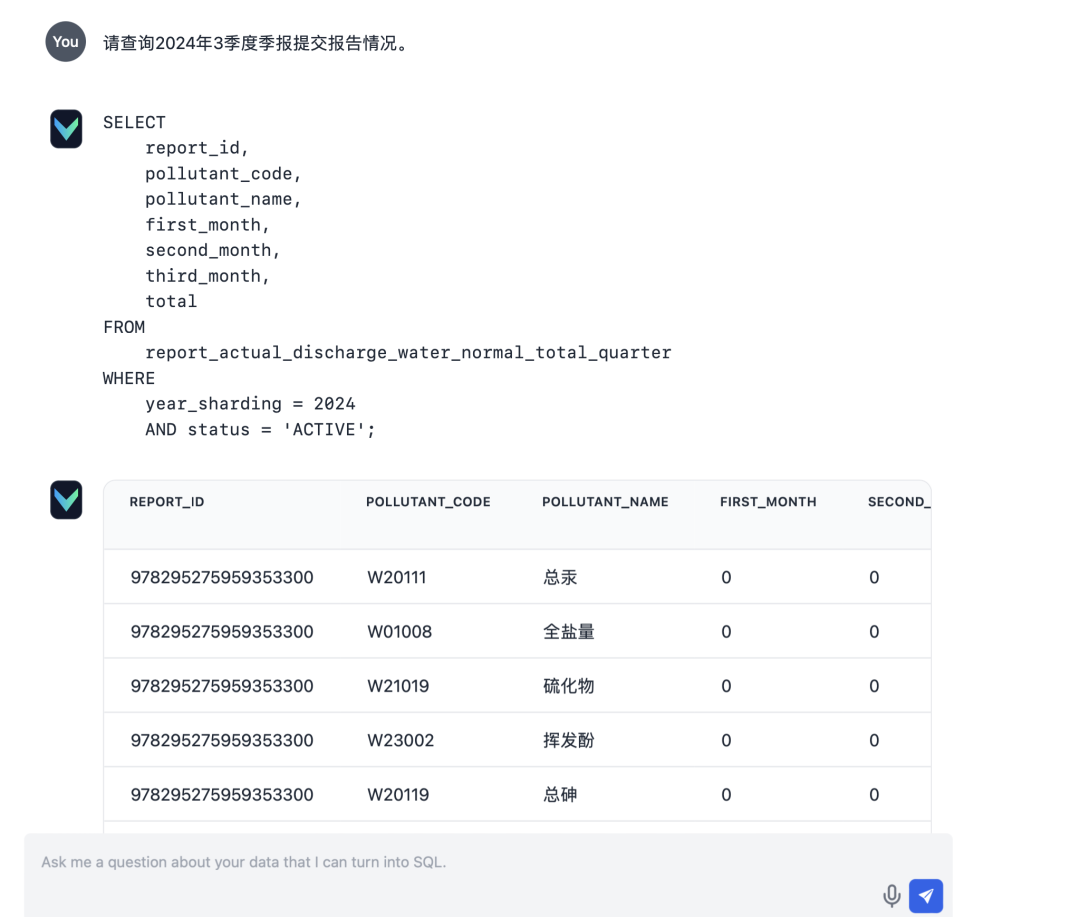
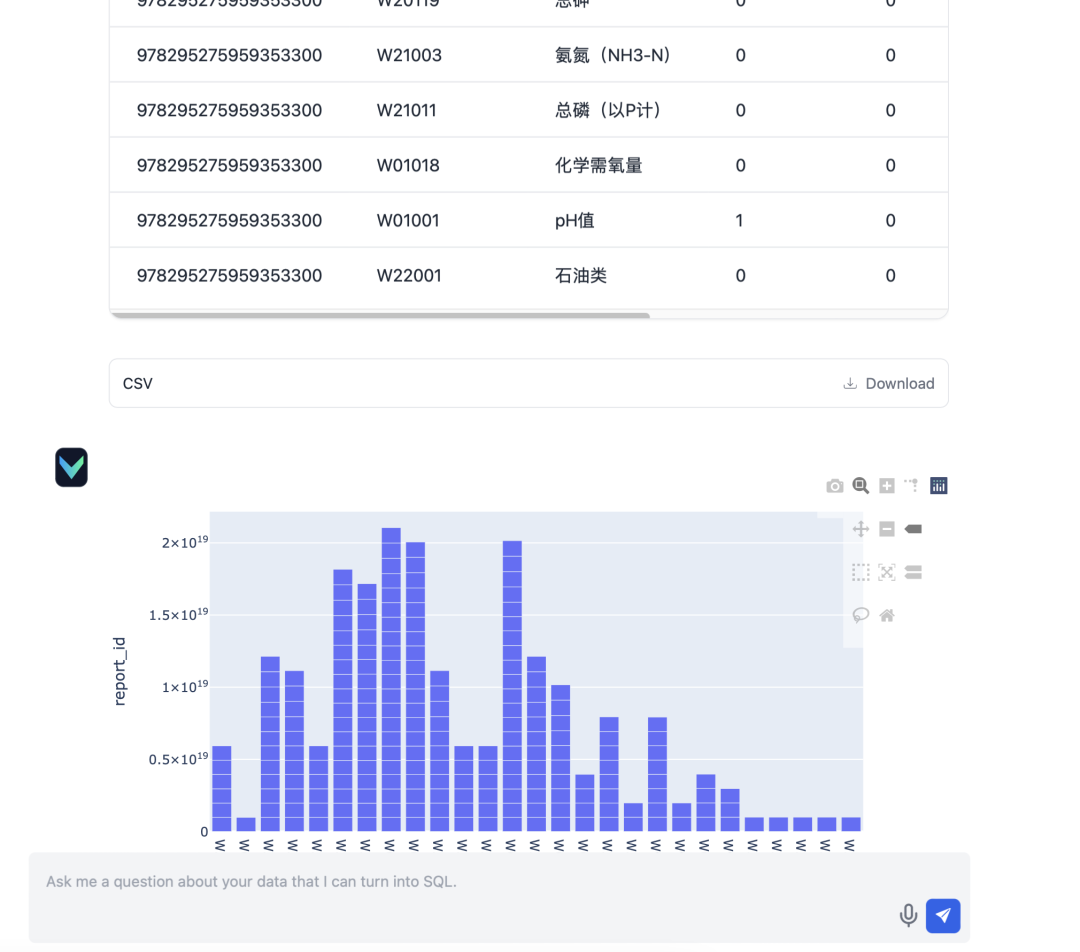
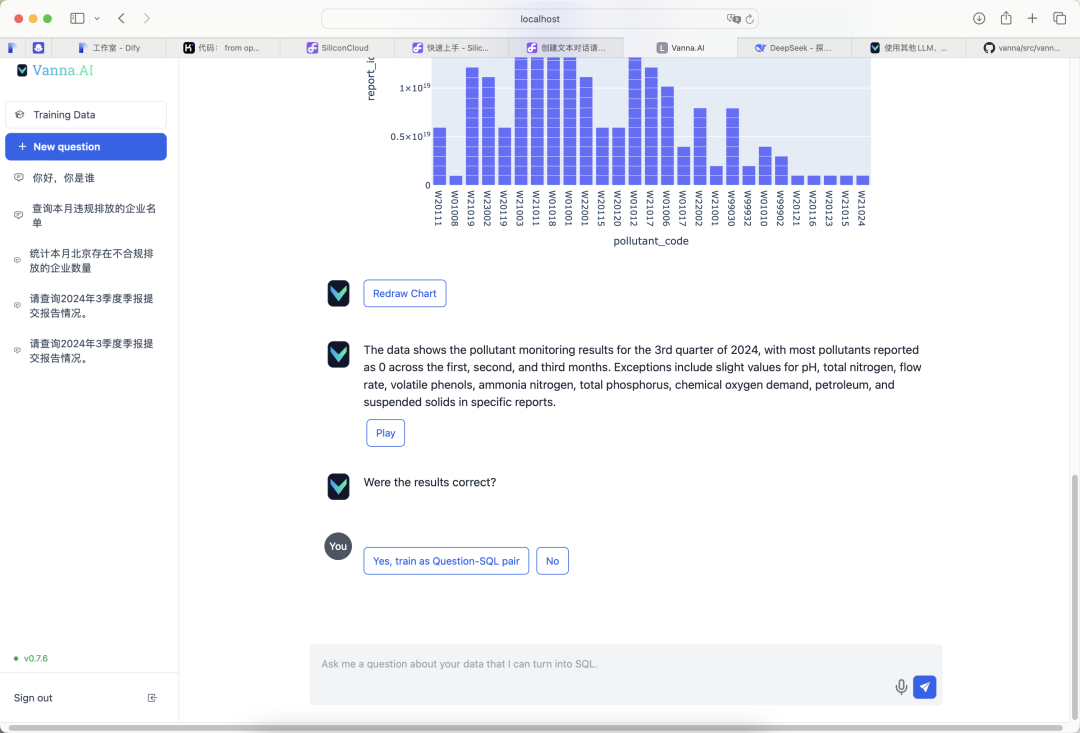
Après le déploiement, la fonctionnalité Q&A de Vanna a fonctionné de manière satisfaisante. Voici quelques résultats de tests réels :
- Saisie : "Veuillez vous renseigner sur l'état de la soumission des rapports pour le rapport trimestriel du trimestre de mars 2024."

- Entrée : "Nombre de statistiques"
- Entrée : "Statistiques sur les polluants"
Résumé et recommandations
Grâce à ces étapes, vous pouvez déployer Vanna localement avec succès et mettre en œuvre des fonctionnalités Text2SQL efficaces en combinaison avec les modèles MySQL et Deepseek. Comparé à d'autres outils, Vanna présente des avantages évidents en termes de facilité d'utilisation et d'efficacité. Il est recommandé aux débutants d'utiliser en priorité des structures de tables pour l'entraînement des données et d'ajuster la configuration du modèle linguistique en fonction des besoins réels.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes



Pas de commentaires...