TPO-LLM-WebUI : un cadre d'intelligence artificielle dans lequel vous pouvez saisir des questions pour entraîner un modèle en temps réel et produire les résultats.
Introduction générale
TPO-LLM-WebUI est un projet innovant ouvert par Airmomo sur GitHub qui permet l'optimisation en temps réel de grands modèles de langage (LLM) par le biais d'une interface web intuitive. Il adopte le cadre TPO (Test-Time Prompt Optimization), ce qui permet d'abandonner complètement le processus fastidieux de mise au point traditionnelle et d'optimiser directement la sortie du modèle sans formation. Une fois que l'utilisateur a saisi une question, le système utilise des modèles gratifiants et un retour d'information itératif pour permettre au modèle d'évoluer dynamiquement au cours du processus de raisonnement, le rendant de plus en plus intelligent et améliorant la qualité du résultat jusqu'à 50%. Qu'il s'agisse de peaufiner des documents techniques ou de générer des réponses de sécurité, cet outil léger et efficace fournit un soutien puissant aux développeurs et aux chercheurs.


Liste des fonctions
- Évolution en temps réelL'optimisation de la production par la phase d'inférence, plus elle est utilisée, plus elle répond aux besoins de l'utilisateur.
- Aucun réglage fin n'est nécessaireLes résultats de l'analyse de la qualité de l'eau de pluie et de la qualité de l'eau de mer sont également pris en compte.
- Compatible avec plusieurs modèlesLes modèles de base et de récompenses : Prise en charge du chargement de différents modèles de base et de récompenses.
- Alignement dynamique des préférences: Ajustement de la production en fonction du retour d'information sur les récompenses pour se rapprocher des attentes humaines.
- Visualisation du raisonnementLes résultats de l'analyse de l'impact de l'optimisation sur l'environnement : Démontrer le processus d'itération de l'optimisation afin de faciliter la compréhension et le débogage.
- Léger et efficaceL'informatique est peu coûteuse et simple à déployer.
- Open source et flexibilitéLe logiciel de gestion de l'information (GIA) : Il fournit le code source et prend en charge le développement défini par l'utilisateur.
Utiliser l'aide
Processus d'installation
Le déploiement de TPO-LLM-WebUI nécessite une configuration de base de l'environnement. Les étapes détaillées ci-dessous aideront les utilisateurs à démarrer rapidement.
1. préparer l'environnement
Assurez-vous que les outils suivants sont installés :
- Python 3.10Environnement opérationnel de base : Core Operating Environment.
- Git: Permet d'obtenir le code du projet.
- GPU (recommandé)Les GPU NVIDIA accélèrent l'inférence.
Créer un environnement virtuel :
Utilisez Condi :
conda create -n tpo python=3.10
conda activate tpo
ou les outils propres à Python :
python -m venv tpo
source tpo/bin/activate # Linux/Mac
tpo\Scripts\activate # Windows
Téléchargez et installez les dépendances :
git clone https://github.com/Airmomo/tpo-llm-webui.git
cd tpo-llm-webui
pip install -r requirements.txt
Installer TextGrad :
TPO s'appuie sur TextGrad, qui nécessite une installation supplémentaire :
cd textgrad-main
pip install -e .
cd ..
2. modèle de configuration
Vous devez télécharger manuellement le modèle de base et le modèle bonus :
- modèle de baseEn tant que
deepseek-ai/DeepSeek-R1-Distill-Qwen-32B(étreignant le visage) - la modélisation des incitationsEn tant que
sfairXC/FsfairX-LLaMA3-RM-v0.1(étreignant le visage)
Placer le modèle dans le répertoire spécifié (par ex./model/HuggingFace/), et enconfig.yamlDéfinir le chemin d'accès dans le champ
3. démarrer le service vLLM
utiliser vLLM Modèle de base de l'hébergement. Prenons l'exemple de 2 GPU :
vllm serve /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
--dtype auto
--api-key token-abc123
--tensor-parallel-size 2
--max-model-len 59968
--port 8000
Une fois le service lancé, écoutez le message http://127.0.0.1:8000.
4. exécuter l'interface WebUI
Lancez l'interface web dans un nouveau terminal :
python gradio_app.py
accès au navigateur http://127.0.0.1:7860Voici une liste des produits les plus courants et les plus populaires disponibles sur le marché.
Principales fonctions
Fonction 1 : Initialisation du modèle
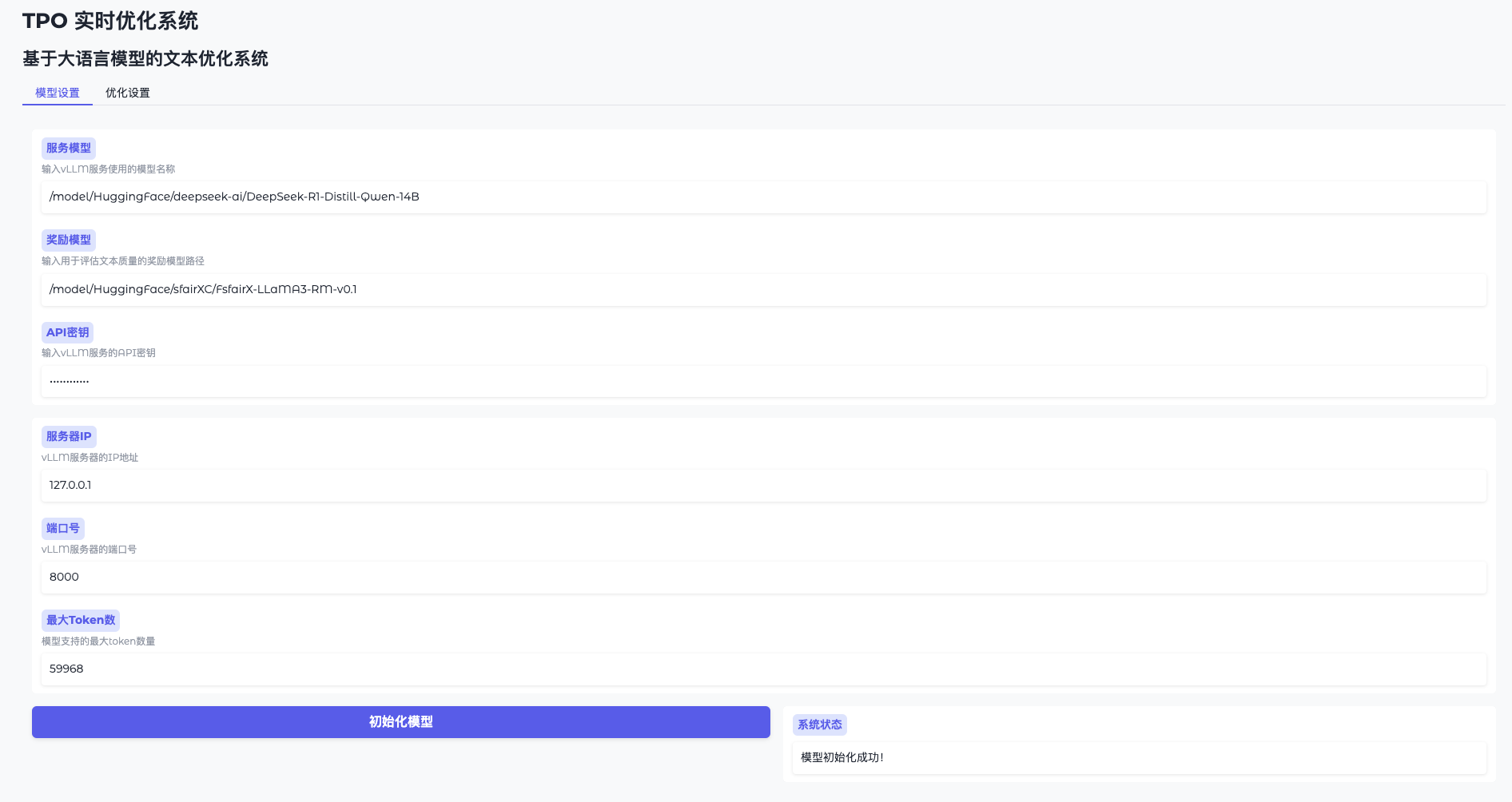
- Paramètres du modèle ouvert
Allez dans l'interface WebUI et cliquez sur "Model Settings". - Connexion à vLLM
Saisissez l'adresse (par exemplehttp://127.0.0.1:8000) et la clé (token-abc123). - Chargement du modèle de récompense
Spécifiez le chemin d'accès (par exemple/model/HuggingFace/sfairXC/FsfairX-LLaMA3-RM-v0.1Cliquez sur "Initialiser" et attendez 1 à 2 minutes. - Confirmation de l'état de préparation
L'interface affiche "Modèle prêt" et vous pouvez continuer.
Fonction 2 : Optimiser la production en temps réel
- Page d'optimisation des bascules
Allez dans "Optimiser les paramètres". - Problèmes de saisie
Saisissez un contenu tel que "Retouchez ce document technique". - Optimisation opérationnelle
Cliquez sur "Démarrer l'optimisation" et le système génère plusieurs résultats candidats qu'il améliore de manière itérative. - Vérifier le processus d'évolution
La page de résultats affiche les résultats initiaux et optimisés avec une qualité de plus en plus élevée.
Fonctionnalité 3 : optimisation du mode script
Si vous n'utilisez pas l'interface WebUI, vous pouvez exécuter un script :
python run.py
--data_path data/sample.json
--ip 0.0.0.1
--port 8000
--server_model /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
--reward_model /model/HuggingFace/sfairXC/FsfairX-LLaMA3-RM-v0.1
--tpo_mode tpo
--max_iterations 2
--sample_size 5
Les résultats de l'optimisation sont enregistrés dans logs/ Dossier.
Description détaillée des caractéristiques spéciales
Fini le réglage fin, place à l'évolution en temps réel
- procédure: :
- Saisissez la question et le système génère la réponse initiale.
- Récompenser l'évaluation du modèle et le retour d'information pour guider l'itération suivante.
- Après plusieurs itérations, le résultat devient plus "intelligent" et la qualité s'améliore considérablement.
- tranchantLes avantages : Gagnez du temps et de l'arithmétique en optimisant à tout moment sans formation.
Plus vous l'utilisez, plus il devient intelligent.
- procédure: :
- Utiliser le même modèle plusieurs fois avec des données d'entrée différentes pour des problèmes différents.
- Le système accumule de l'expérience sur la base de chaque retour d'information et le résultat est mieux adapté aux besoins.
- tranchantLe système : apprend de manière dynamique les préférences de l'utilisateur pour obtenir de meilleurs résultats à long terme.
mise en garde
- exigences en matière de matérielRecommandé 16GB de mémoire vidéo ou plus, plusieurs GPU doivent s'assurer que les ressources sont libres et disponibles.
export CUDA_VISIBLE_DEVICES=2,3Désignation. - Résolution de problèmesLorsque la mémoire vidéo est saturée, abaissez le bouton de la télécommande.
sample_sizeou vérifier l'occupation du GPU. - Soutien communautaireLes problèmes de sécurité : Voir le README de GitHub ou les problèmes pour obtenir de l'aide.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...